Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/aimanamri/yellow-taxi-trips-etl-data-engineering-project
https://github.com/aimanamri/yellow-taxi-trips-etl-data-engineering-project
azure data-engineering etl-pipeline jupyter-notebook
Last synced: 13 days ago
JSON representation
- Host: GitHub
- URL: https://github.com/aimanamri/yellow-taxi-trips-etl-data-engineering-project
- Owner: aimanamri
- Created: 2023-10-24T23:10:57.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2023-12-09T12:03:46.000Z (about 1 year ago)
- Last Synced: 2024-11-24T15:15:37.254Z (2 months ago)
- Topics: azure, data-engineering, etl-pipeline, jupyter-notebook
- Language: Jupyter Notebook
- Homepage:
- Size: 41.5 MB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Yellow Taxi Trips Data Analytics | Data Engineering Azure Project





## Introduction
The "Yellow Taxi Trips Data Analytics" project uses modern technology and data analysis to extract valuable insights from New York City's yellow taxi trip records. I'm employing a range of advanced tools like Python, SQL, Azure services, and Power BI to process, analyze, and visualize the data.
## Architecture

## Technologies Used
1. Python
2. SQL
3. Azure Data Factory
4. Azure Data Bricks
5. Azure Synapse Analytics
6. Power BI
## Dataset Used
1. Source : https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
2. Data Dictionary : https://www.nyc.gov/assets/tlc/downloads/pdf/data_dictionary_trip_records_yellow.pdf
The data is separated by months for each year, so I created a simple Python script to download all the Parquet files and combine them by year. The dataset is stored in .parquet.gzip format to be cost-effective for storage. But since it were too large to be stored on GitHub (without Git LFS), reducing the file size and using CSV/Parquet format is the best solution by filtering the rows for this side project use. Here, first `20,000` rows randomly selected from each month will be used.
## Data Model
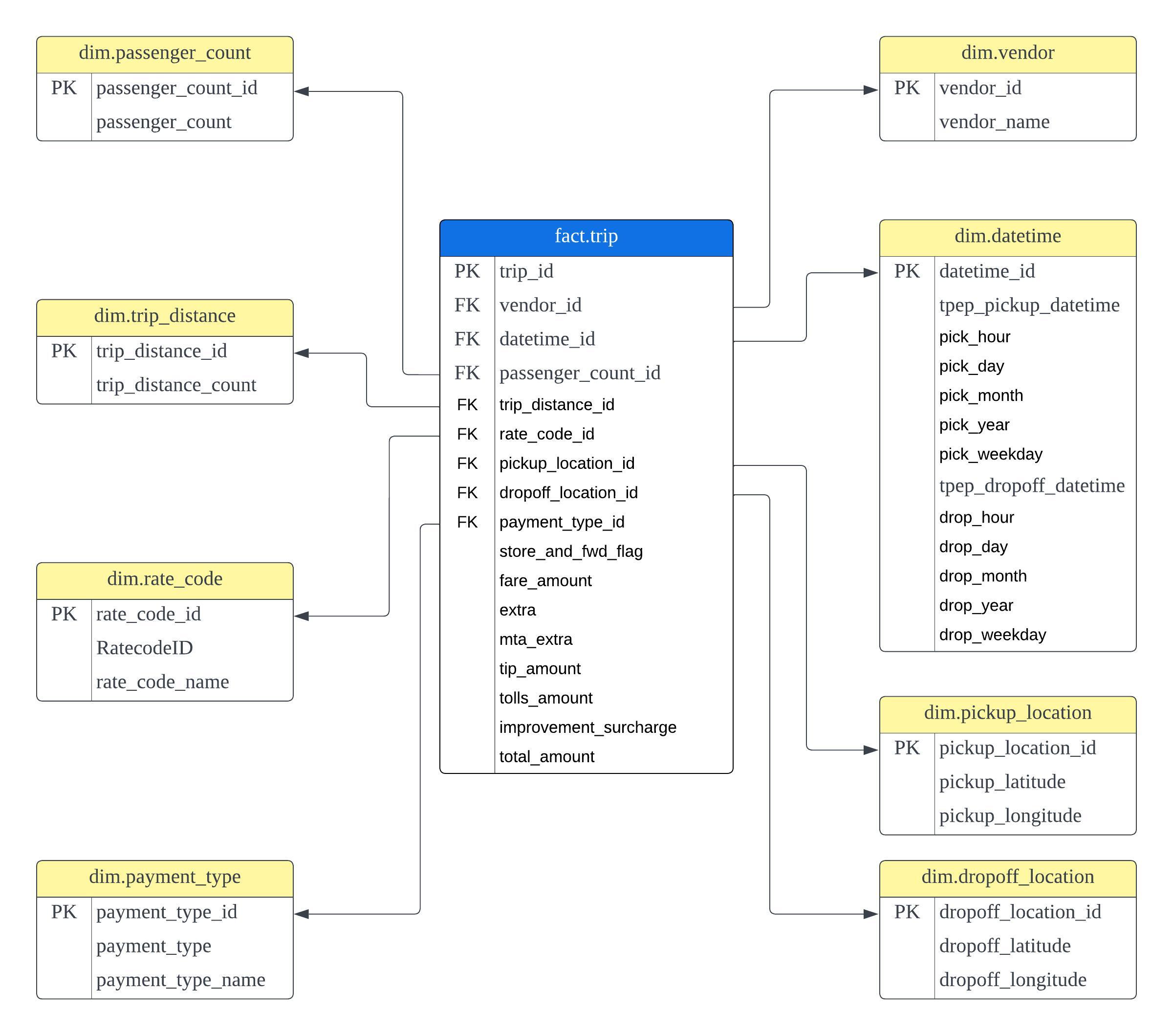
## Insights