https://github.com/akanimax/natural-language-summary-generation-from-structured-data
Implementation of the paper -> https://arxiv.org/abs/1709.00155. For converting information present in the form of structured data into natural language text
https://github.com/akanimax/natural-language-summary-generation-from-structured-data
Last synced: 6 months ago
JSON representation
Implementation of the paper -> https://arxiv.org/abs/1709.00155. For converting information present in the form of structured data into natural language text
- Host: GitHub
- URL: https://github.com/akanimax/natural-language-summary-generation-from-structured-data
- Owner: akanimax
- License: mit
- Created: 2017-11-23T06:56:58.000Z (almost 8 years ago)
- Default Branch: master
- Last Pushed: 2019-03-12T09:08:07.000Z (over 6 years ago)
- Last Synced: 2024-11-18T23:52:26.593Z (12 months ago)
- Language: Python
- Size: 1.03 GB
- Stars: 183
- Watchers: 14
- Forks: 57
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-nlg - Summary Generation From Structured Data - For converting information present in the form of structured data into natural language text. (Neural Natural Language Generation)
README
# Natural-Language-Summary-Generation-From-Structured-Data
Implementation (Personal) of the paper titled
`"Order-Planning Neural Text Generation From Structured Data"`. The dataset
for this project can be found at ->
[WikiBio](https://github.com/DavidGrangier/wikipedia-biography-dataset)
Requirements for training:
* `python 3+`
* `tensorflow-gpu` (preferable; CPU will take forever)
* `Host Memory 12GB+` (this will be addressed soon)
## Architecture
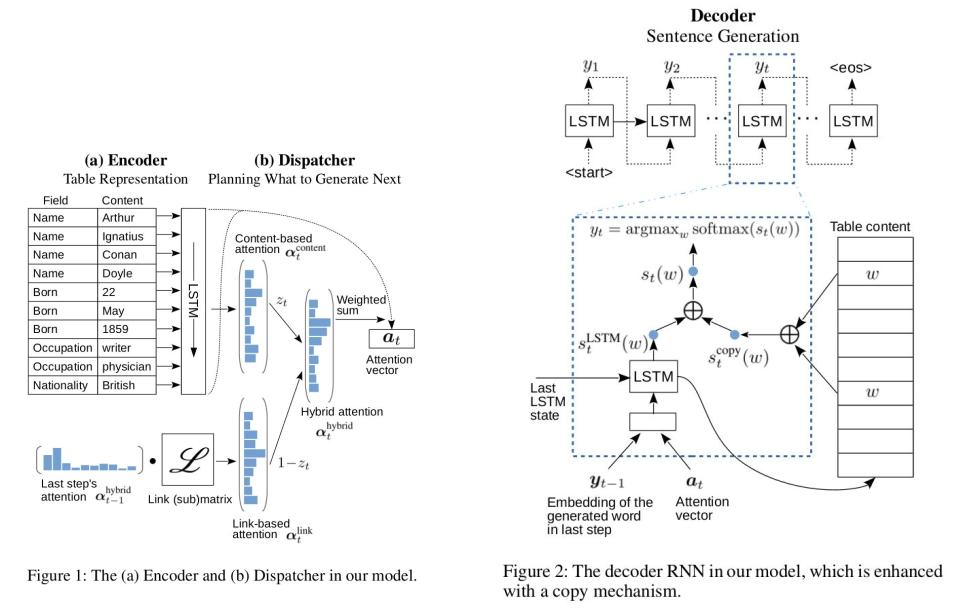
## Running the Code
Process of using this code is slightly involved presently.
This will be addressed in further development (perhaps with collaboration).
#### 1. Preprocessing:
Please refer to the `/TensorFlow_implementation/Data_Preprocessor.ipynb`
for info about what steps are performed in preprocessing the data. Using
the notebook on the full data for preprocessing will be very slow,
so please use the following procedure for it.
Step 1:
(your_venv)$ python fast_data_preprocessor_part1.py
Note that all the tweakable parameters are declared at the
beginning of the script (Change them as per your requirement).
This will generate a `temp.pickle` file in the same directory. Do not delete
it even after full preprocessing. This is like a backup of the
preprocessing pipeline; i.e. if you decide to change something later,
you would'nt have to run the entire preprocessing again.
Step 2:
(your_venv)$ python fast_data_preprocessor_part12.py
This will create the following file: `/Data/plug_and_play.pickle`. Again,
tweakable parameters are at the beginning of the script.
**Please Note that this process requires RAM 12GB+.
If you have < 12GB Host memory, please use a subset of
the dataset instead of the entire dataset
(change `data_limit` in the script).**
#### 2. Training:
Once preprocessing is done, simply run one of the two training Scripts.
(your_venv)$ python trainer_with_copy_net.py
OR
(your_venv)$ python trainer_without_copy_net.py
Again all the hyperparameters are present at the beginning of the script.
Example `trainer_without_copy_net.py`:
''' Name of the model: '''
# This can be changed to create new models in the directory
model_name = "Model_1(without_copy_net)"
'''
========================================================
|| All Tweakable hyper-parameters
========================================================
'''
# constants for this script
no_of_epochs = 500
train_percentage = 100
batch_size = 8
checkpoint_factor = 100
learning_rate = 3e-4 # for learning rate
# but I have noticed that this learning rate works quite well.
momentum = 0.9
# Memory usage fraction:
gpu_memory_usage_fraction = 1
# Embeddings size:
field_embedding_size = 100
content_label_embedding_size = 400 # This is a much bigger
# vocabulary compared to the field_name's vocabulary
# LSTM hidden state sizes
lstm_cell_state_size = hidden_state_size = 500 # they are
# same (for now)
'''
========================================================
'''
## Test Runs:
Once training is started, log-dirs are created for Tensorboard.
Start your `tensorboard` server pointing to the log-dir.
#### Loss monitor:
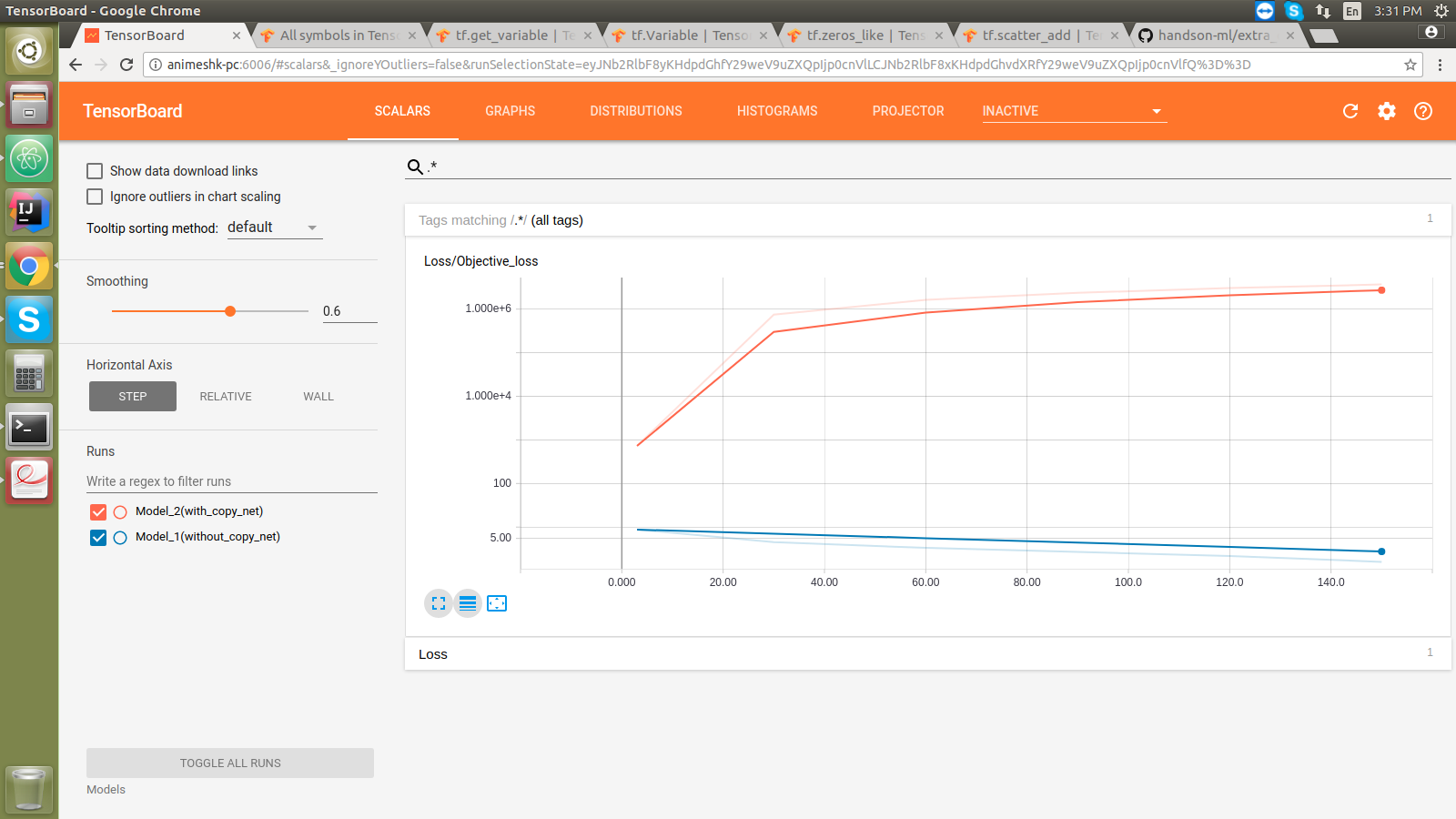
#### Embedding projector:
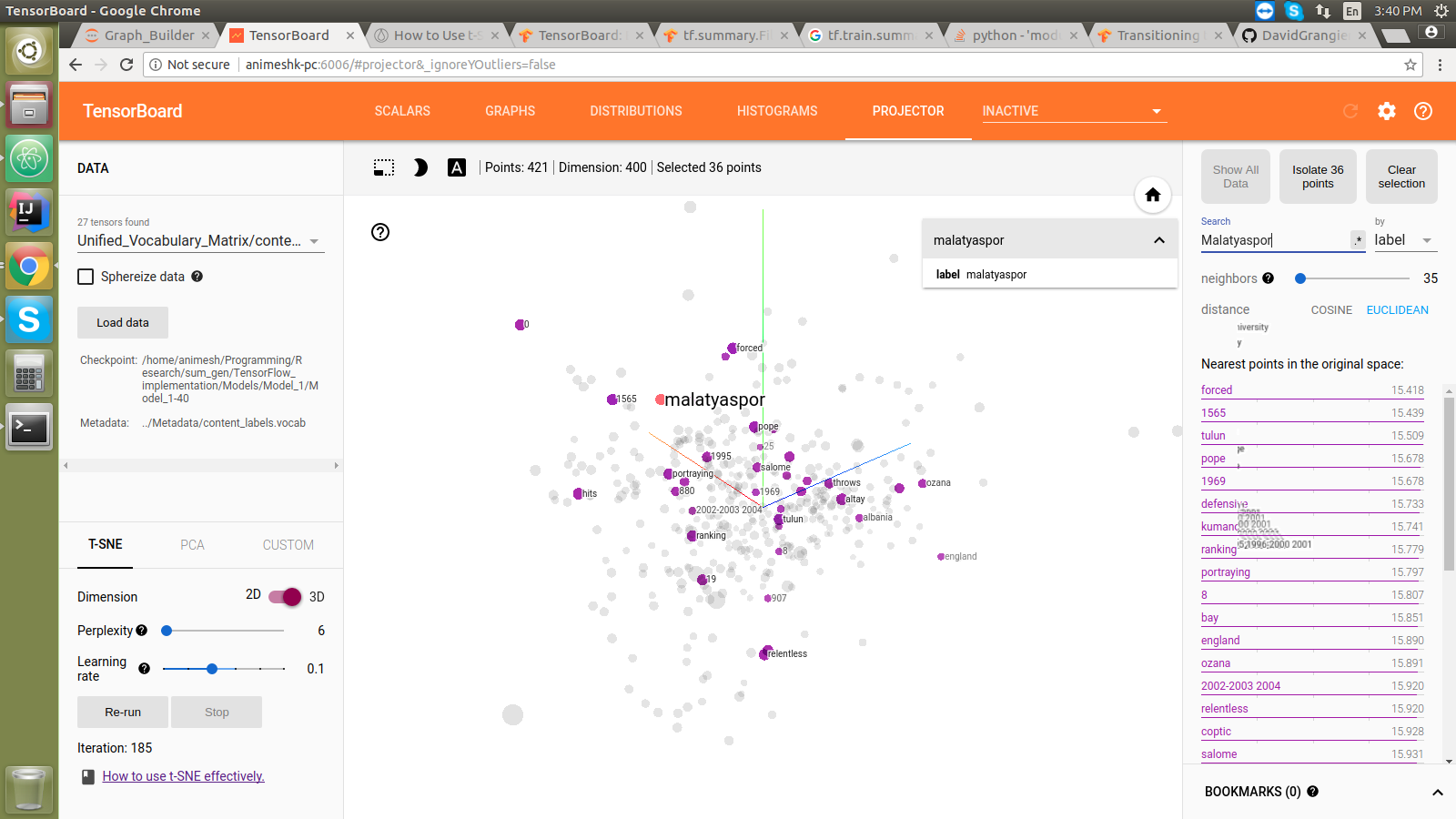
* **Trained models coming soon ...**
## Thanks
Please feel free to open PRs (contribute)/ issues / comments (feedback) here.
Best regards,
@akanimax :)