https://github.com/alejo1630/whatsapp_chat_analysis
A Jupyter Notebook with the analysis for a Whatsapp Chat using several techniques of data wrangling, EDA and Sentiment Analysis
https://github.com/alejo1630/whatsapp_chat_analysis
data-visualization data-wrangling emojis exploratory-data-analysis jupyter-notebook sentiment-analysis whatsapp-chat
Last synced: 4 months ago
JSON representation
A Jupyter Notebook with the analysis for a Whatsapp Chat using several techniques of data wrangling, EDA and Sentiment Analysis
- Host: GitHub
- URL: https://github.com/alejo1630/whatsapp_chat_analysis
- Owner: alejo1630
- Created: 2024-02-14T18:55:01.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-03-27T22:11:01.000Z (over 2 years ago)
- Last Synced: 2025-10-13T23:26:29.017Z (9 months ago)
- Topics: data-visualization, data-wrangling, emojis, exploratory-data-analysis, jupyter-notebook, sentiment-analysis, whatsapp-chat
- Language: Jupyter Notebook
- Homepage:
- Size: 13.4 MB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Whatsapp Chat Analysis
A Jupyter Notebook with the analysis for a Whatsapp Chat using several techniques of data wrangling, EDA and Sentiment Analysis
## 🔰 How does it work?
Data is downloaded as a .txt file from Whatsapp App Without Media and loaded in the Jupyer Notebook
### Data Wrangling
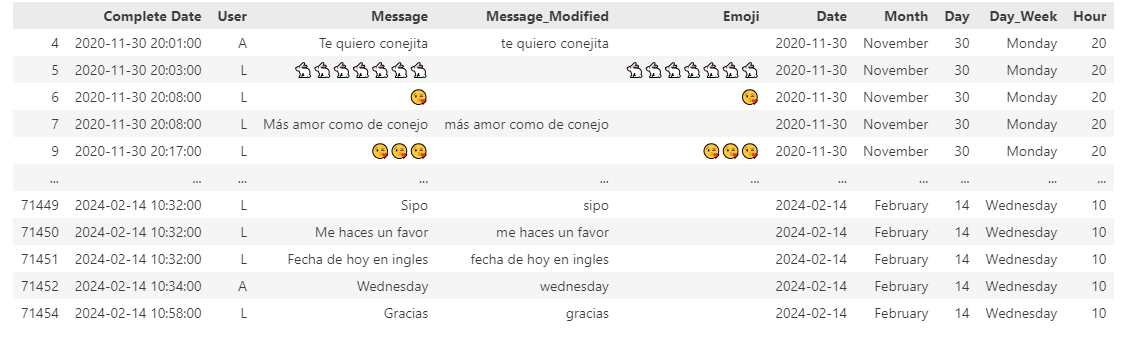
- Chat data is organized into three columns:
- Complete Date
- User
- Message
- A **Regex Function** is used for several operations and create a *Message_Modified* column:
- Lowercase the messages
- Delete messages with URL
- Remove numbers
- Remove messages with spaces
- Remove special characters
- Remove repeated letters
- An **Emoji** column is created to identify all the emojis used in messages
- Complete Date information is used to create the following columns.
- Date [YYYY-MM-DD]
- Month (Name)
- Day (Number 1-31)
- Day (Week Name)
- Hour
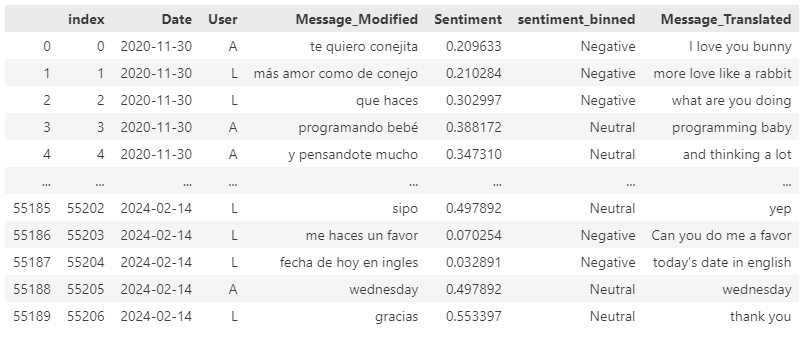
This is what the final dataset looks like:
### Exploratory Data Analysis (EDA)
Several questions were answered using the dataset information.
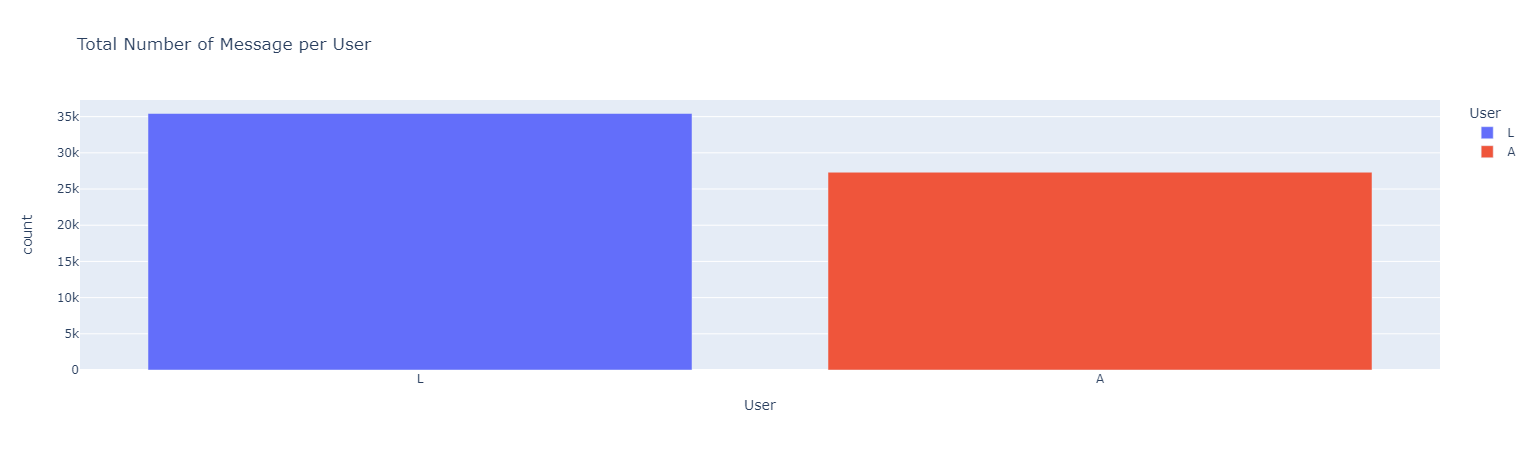
#### *Who has sent the highest number of messages?*
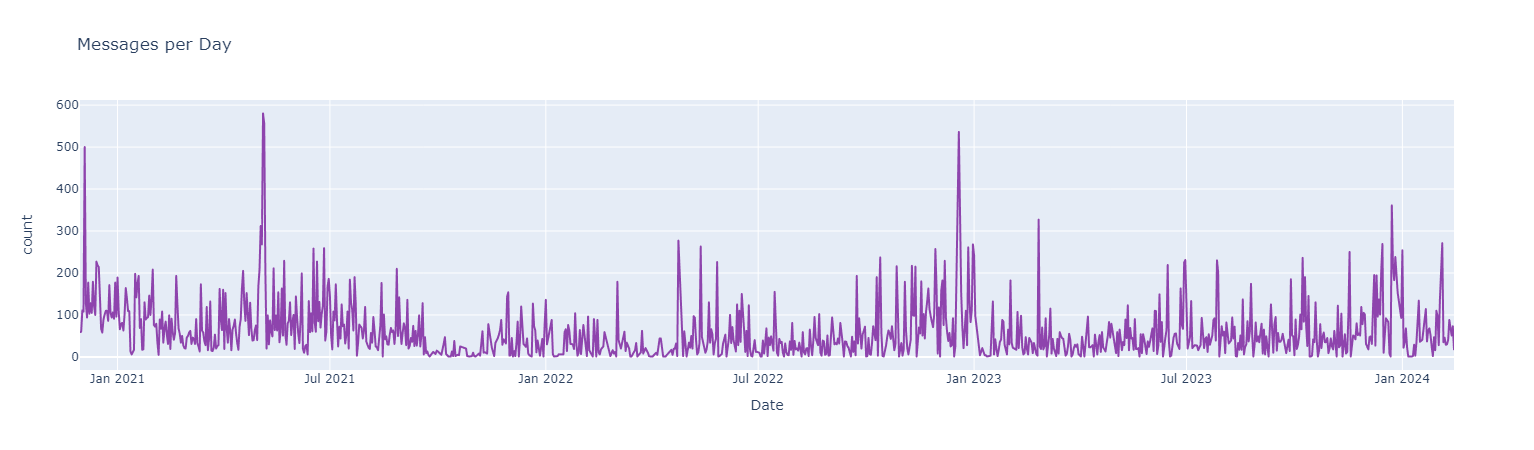
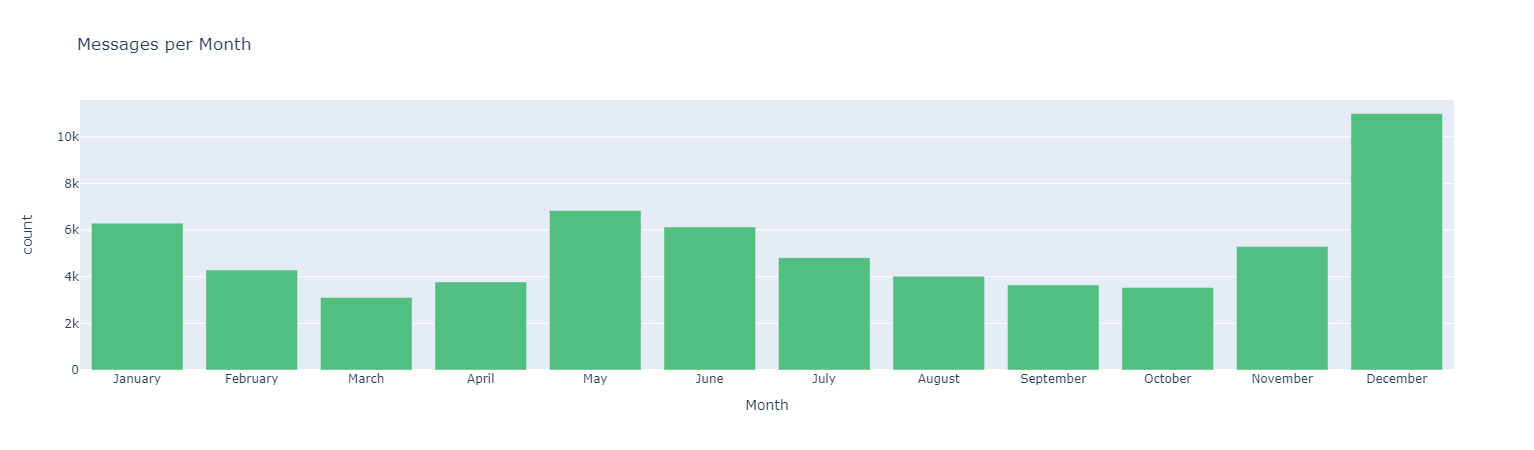
#### *Messages interactions through time*
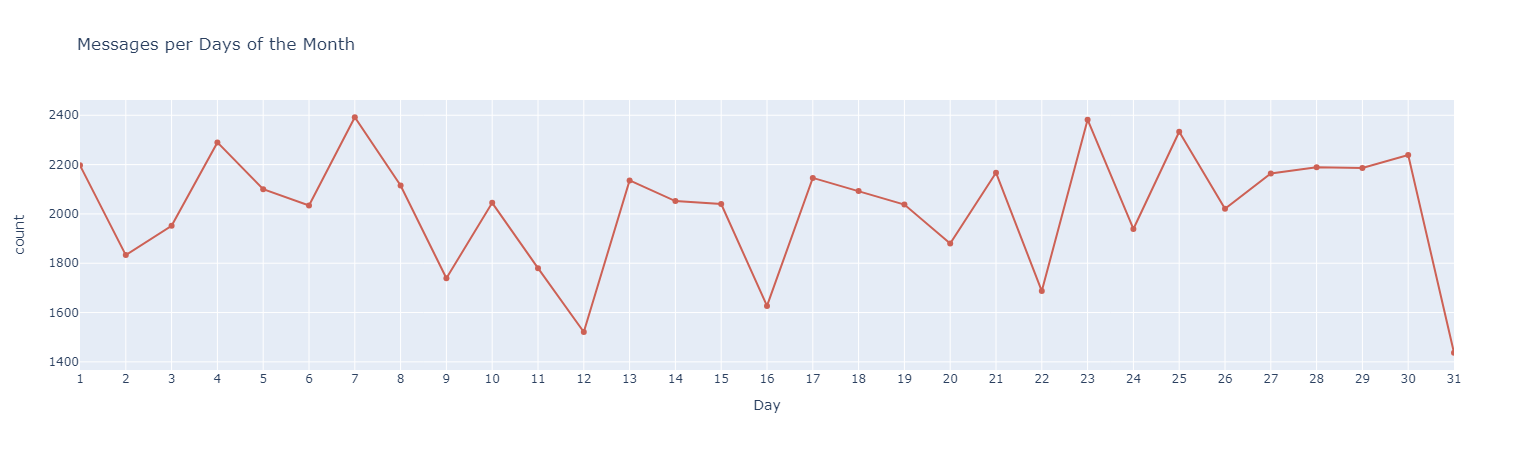
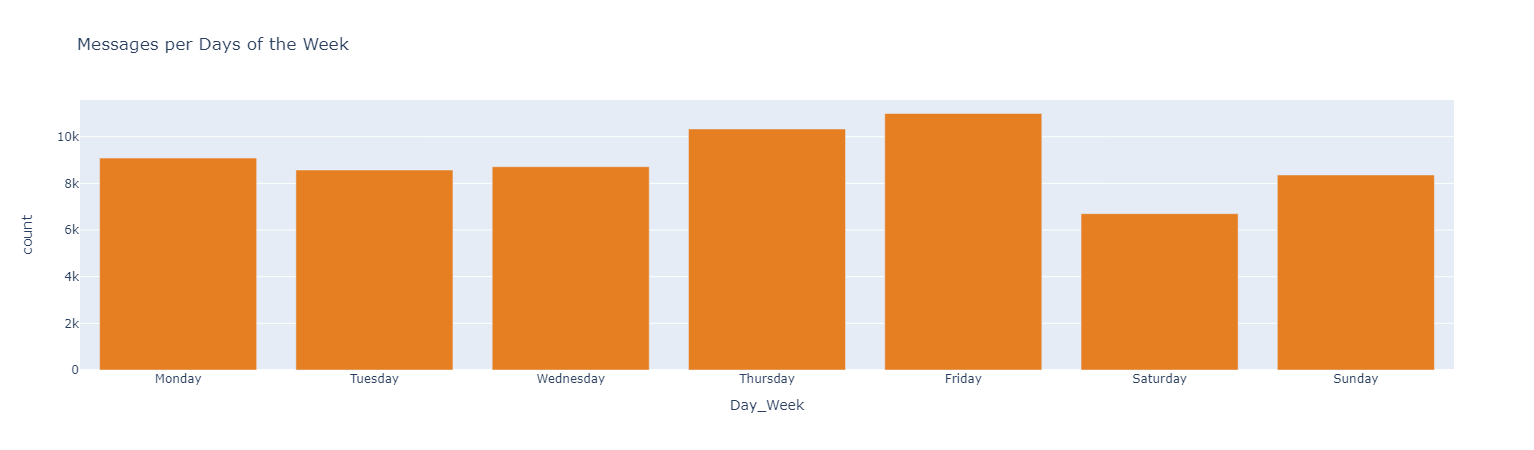
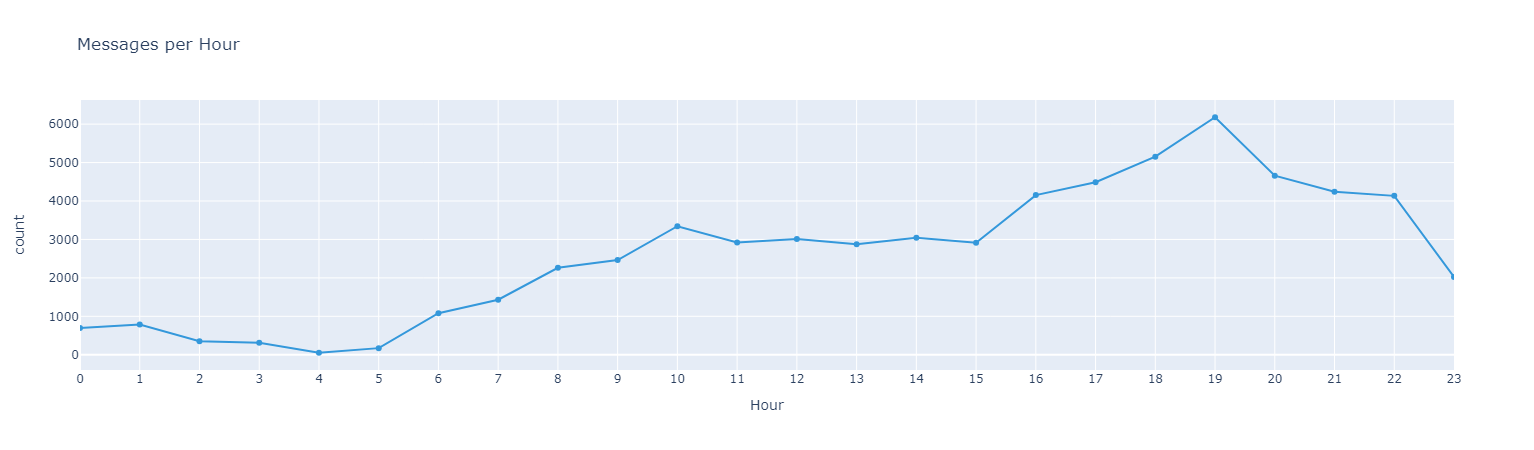
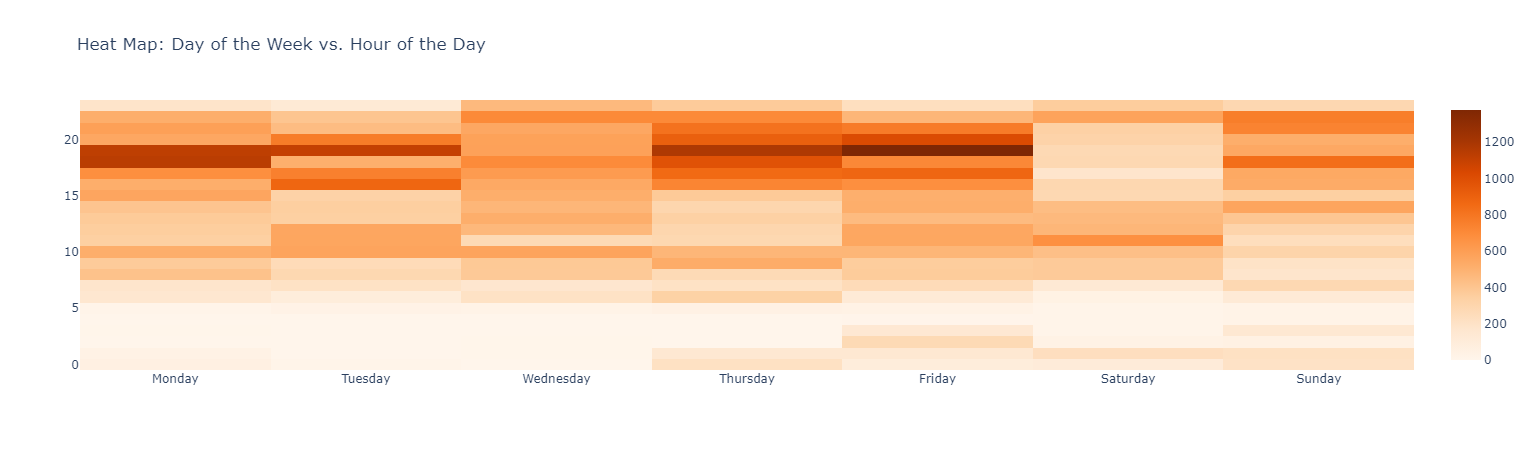
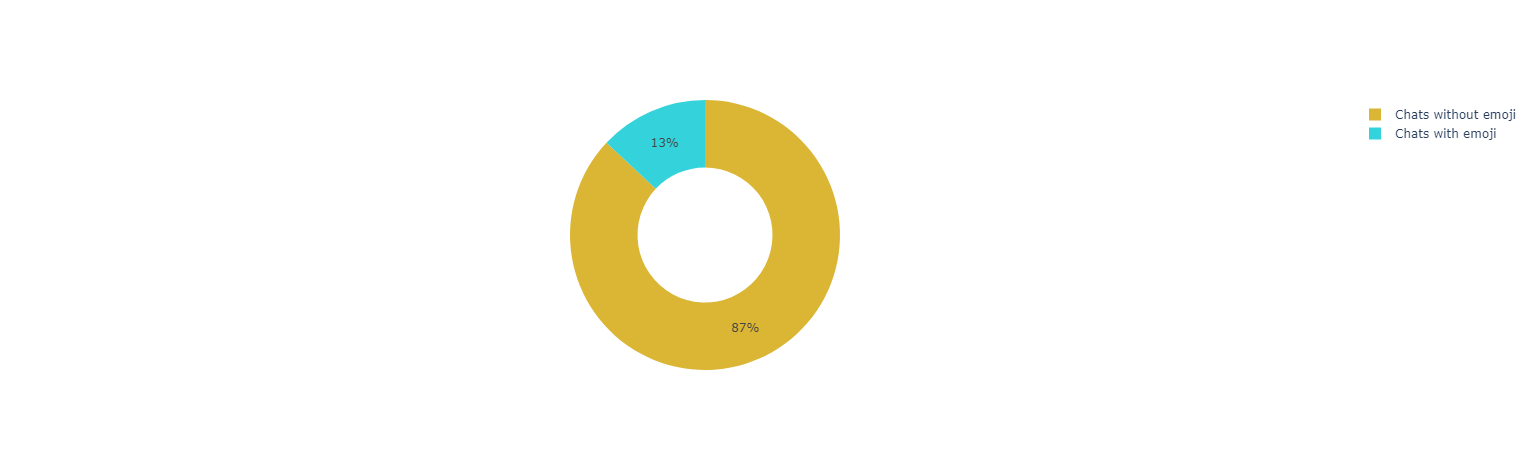
#### *Use of Emojis*
*Top Emojis User A*
`[('😘', 7403), ('🥺', 1058), ('😬', 411), ('🤪', 277), ('❤', 266)]`
*Top Emojis User L*
`[('🥺', 1378), ('😘', 1111), ('🥰', 912), ('☺', 622), ('😊', 587)]`
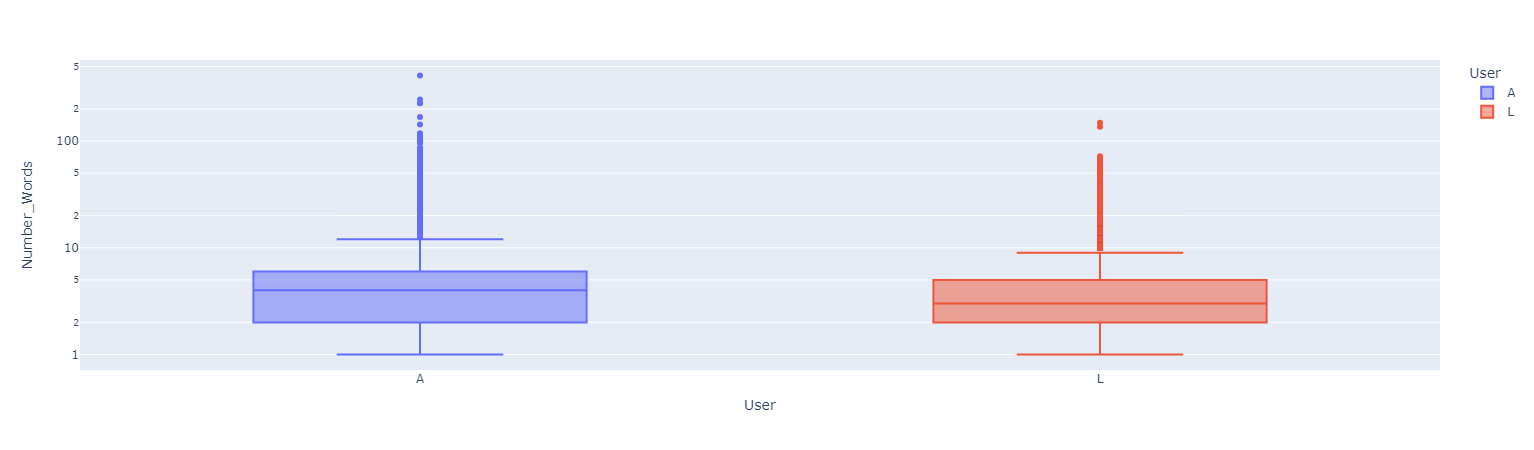
#### *Count of Words*
#### *WordCloud*
*Both Users*

*Both Users with Spanish Stop Words*

*A User*

*L User*

### Sentiment Analysis
#### *Spanish Analysis*
Sentiment score {Negative [0 : 0.33] | Neutral [0.33 : 0.66] ! Positive [0.66 : 1]}
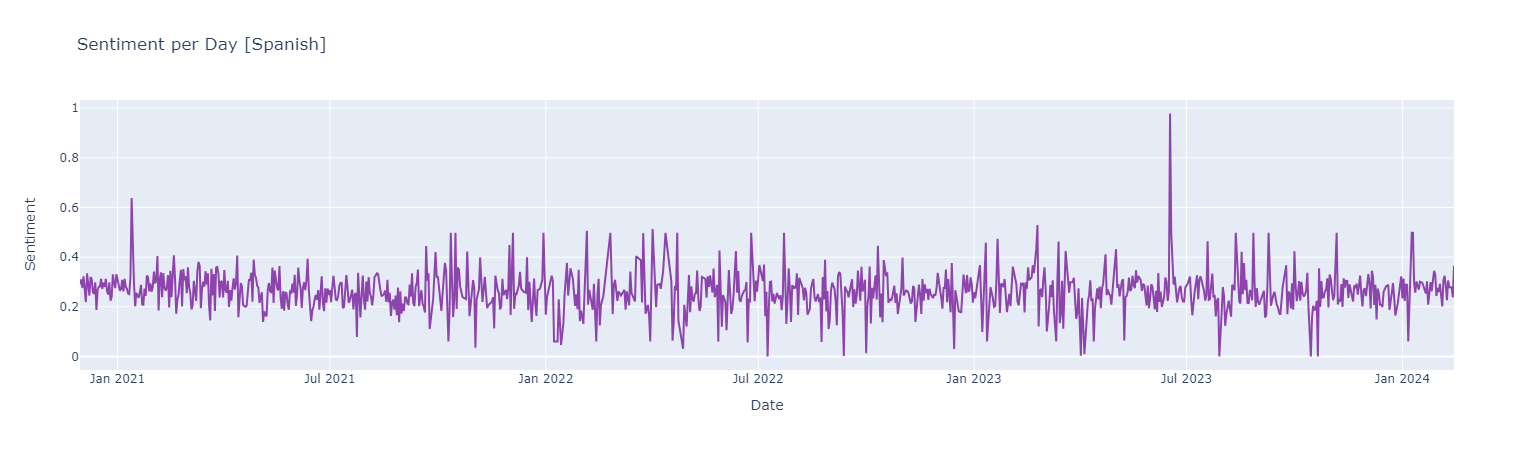
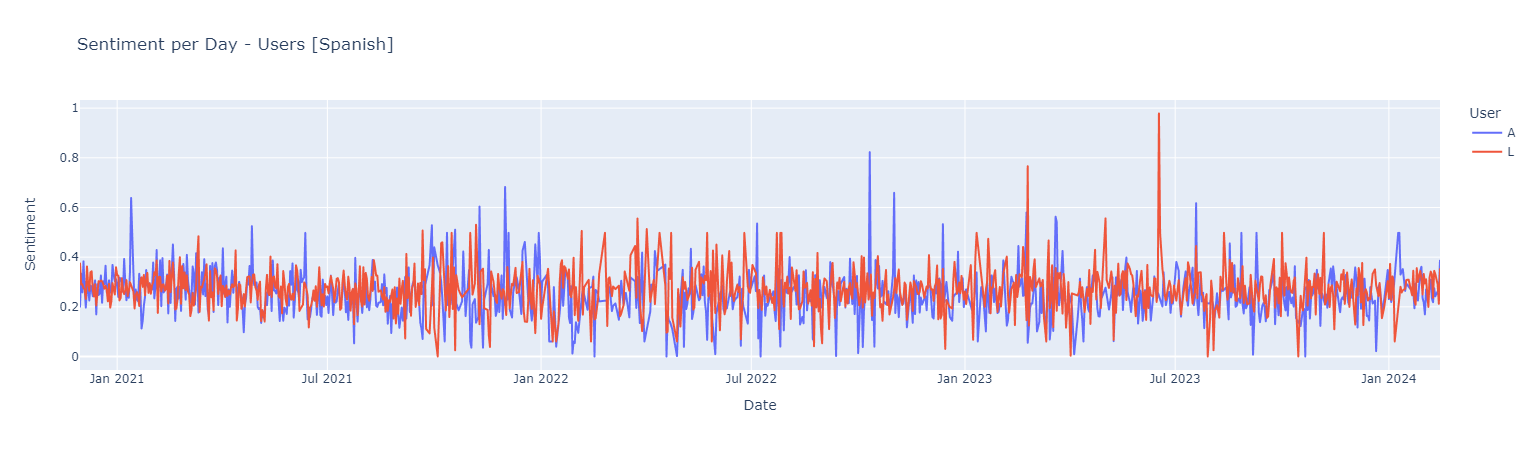
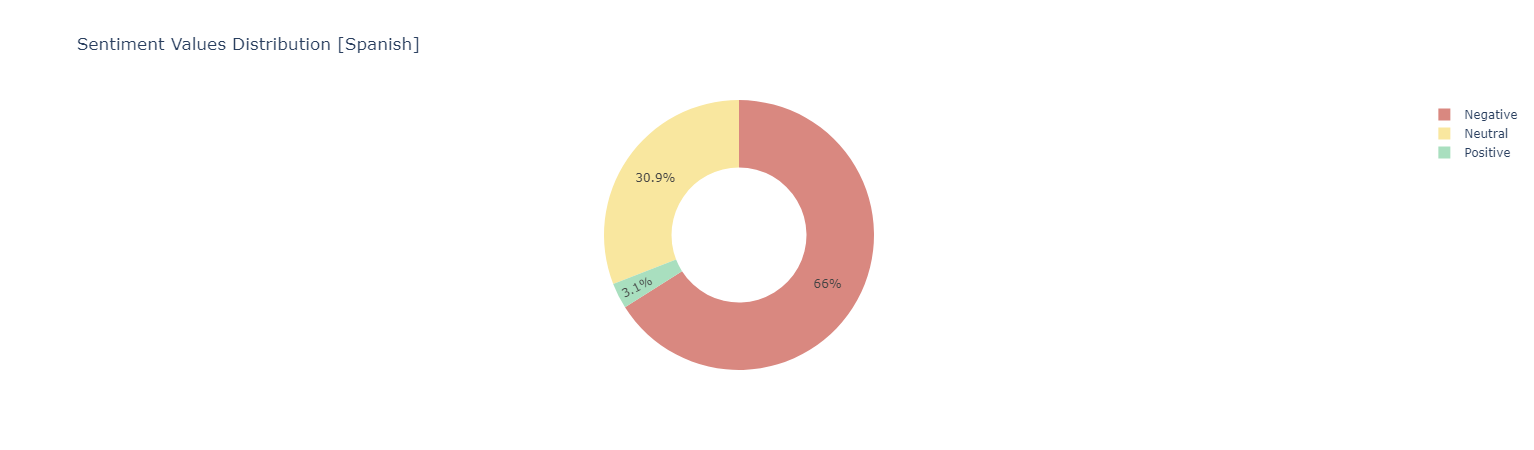
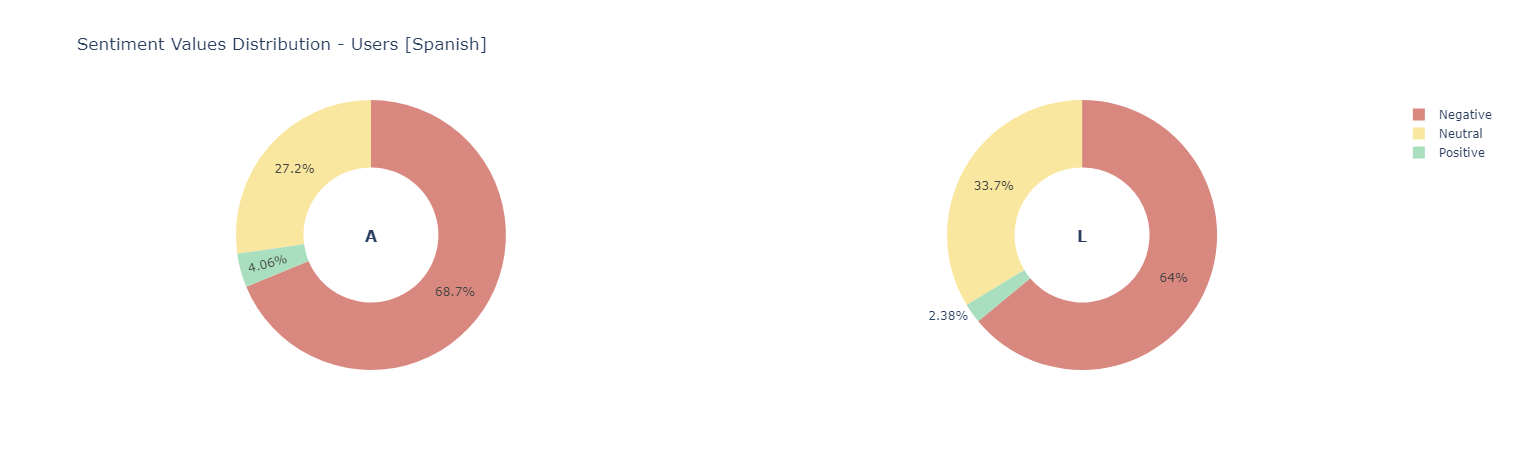
*Positive Words*

*Negative Words*

*The *Spanish Sentiment Analysis* didn't get good results. Now we want to try to perform a Sentiment Analysis with the Messages Translations to English*
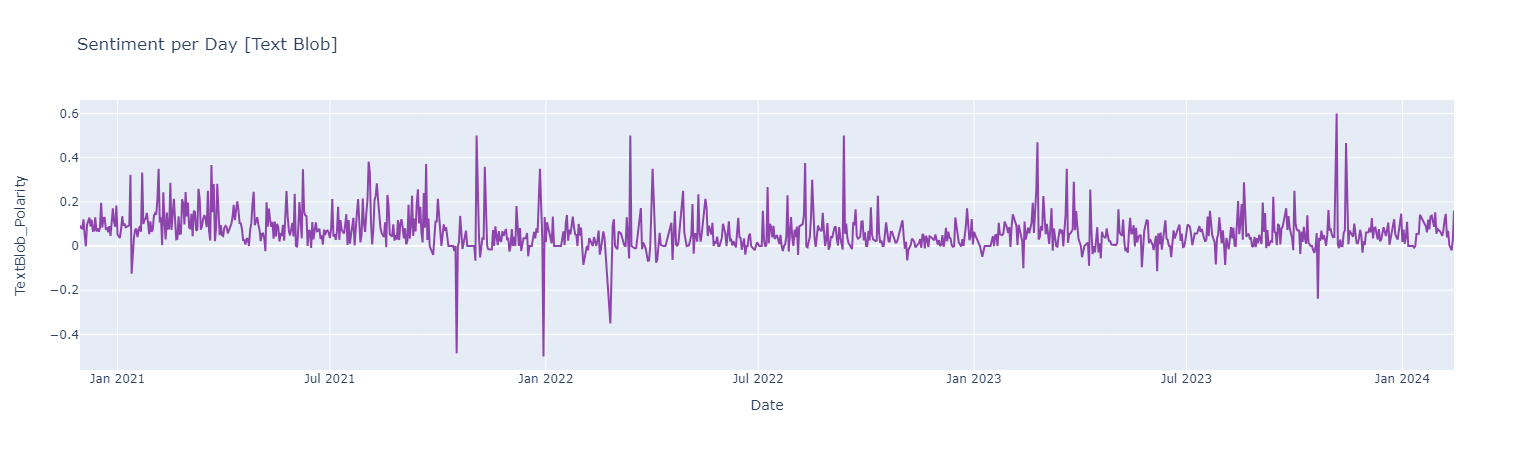
#### *Sentiment Analysis Using [Text Blob](https://www.analyticsvidhya.com/blog/2021/10/making-natural-language-processing-easy-with-textblob/)*
Sentiment score {Negative [-1 : -0.33] | Neutral [-0.33 : 0.33] ! Positive [0.33 : 1]}
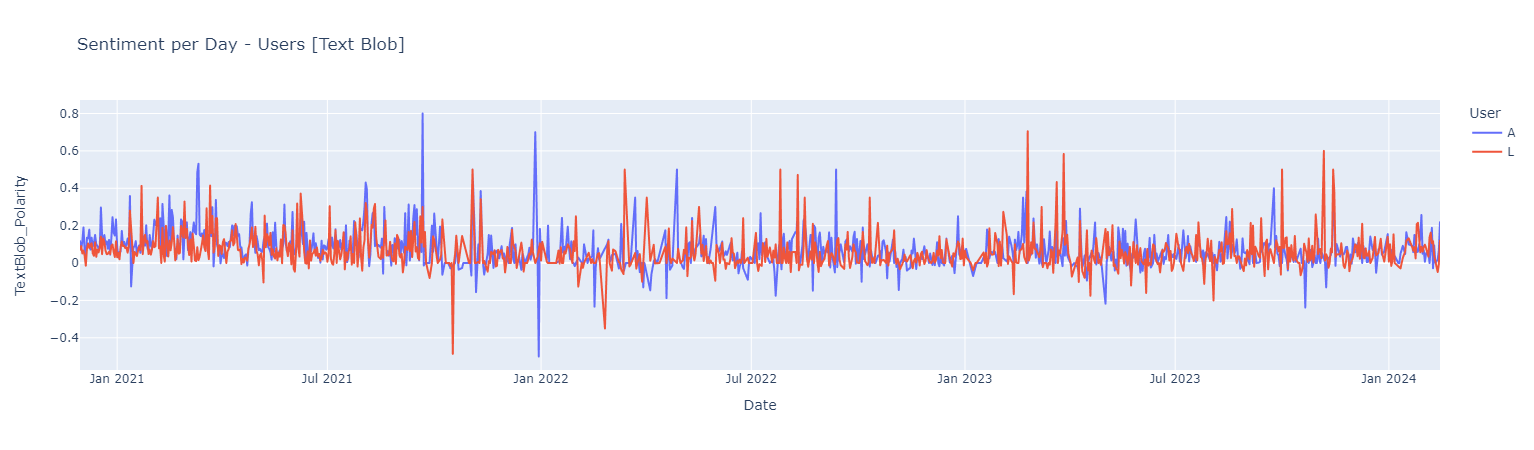
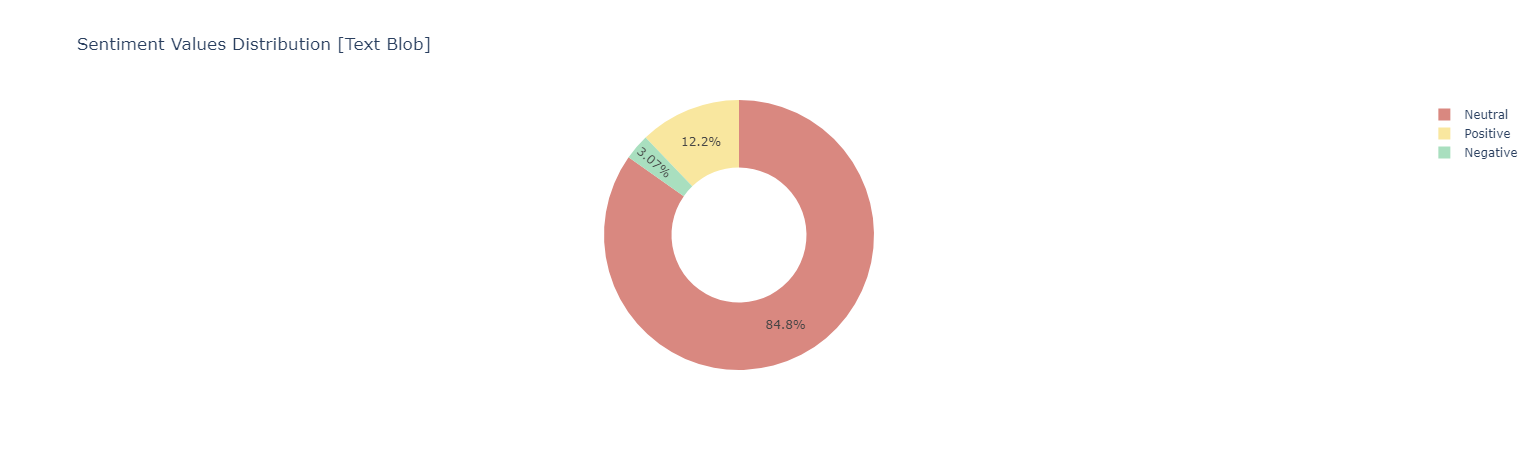

*Positive Words*

*Negative Words*

#### *Sentiment Analysis Using [NLTK](https://akladyous.medium.com/sentiment-analysis-using-vader-c56bcffe6f24)*
Sentiment score {Negative [0 : -0.05] | Neutral [-0.05 : 0.05] ! Positive [0.05 : 1]}
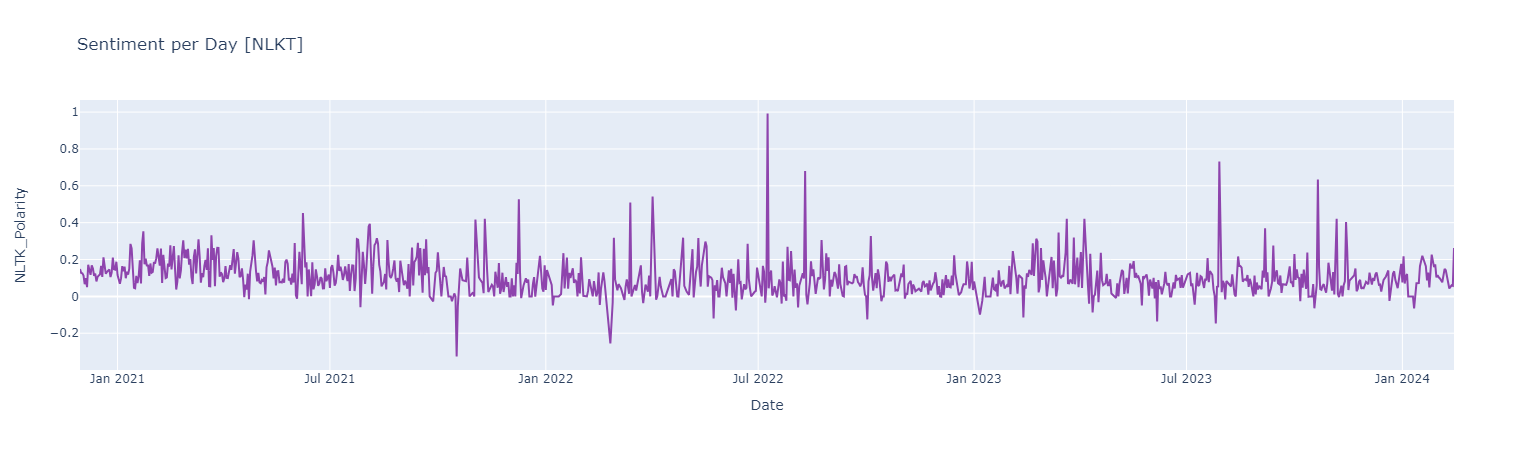
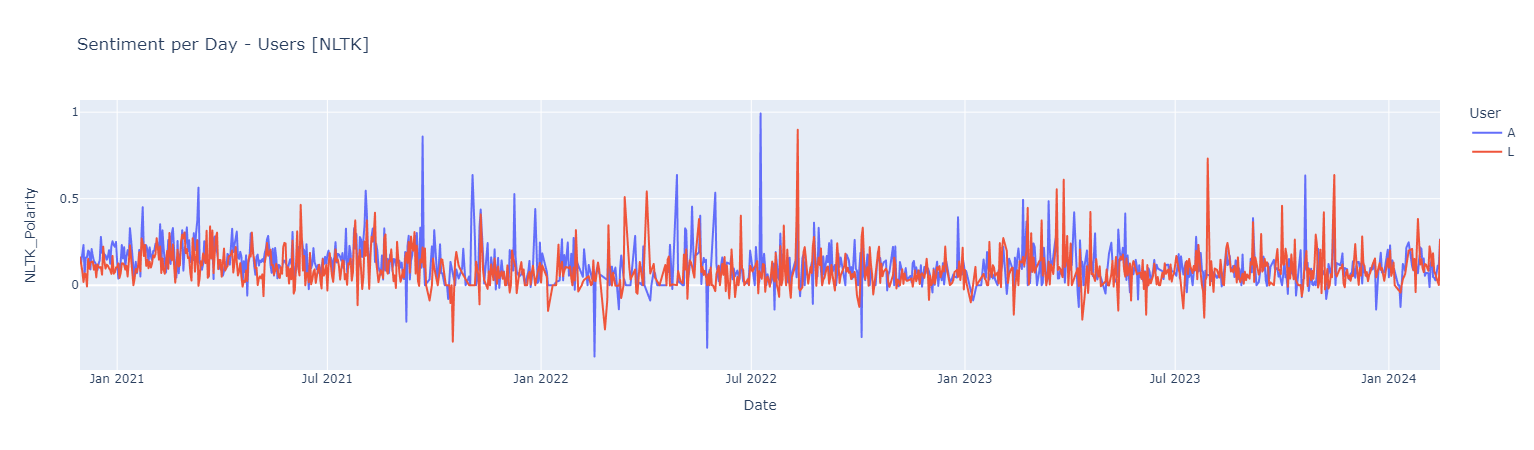
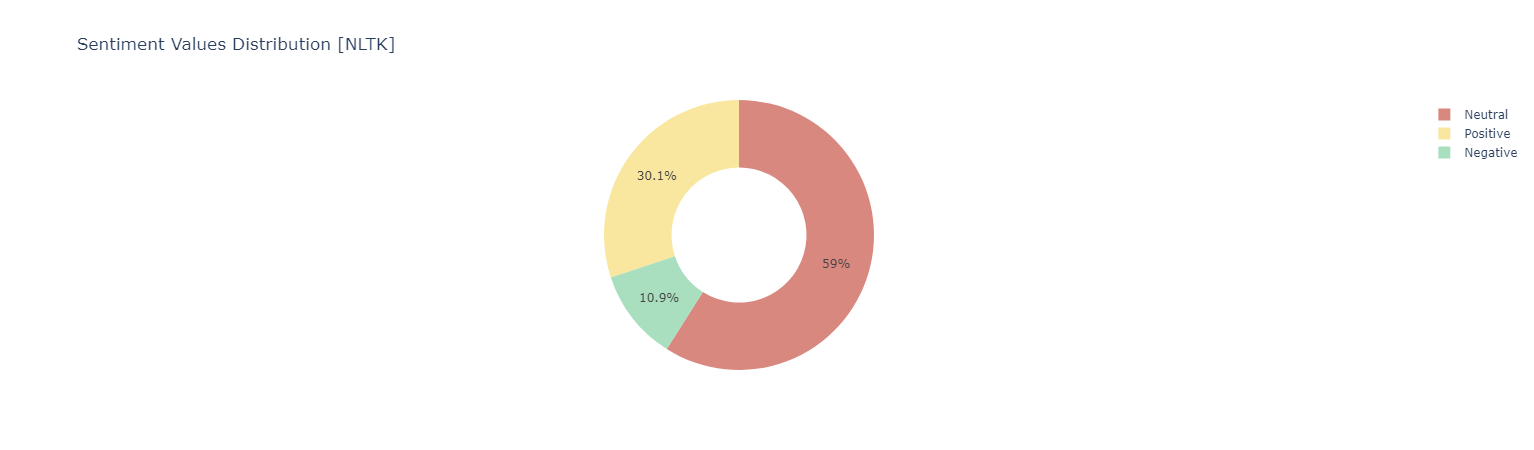

*Positive Words*
*Negative Words*
