https://github.com/alephdata/followthemoney-compare
followthemoney-compare
https://github.com/alephdata/followthemoney-compare
Last synced: 11 months ago
JSON representation
followthemoney-compare
- Host: GitHub
- URL: https://github.com/alephdata/followthemoney-compare
- Owner: alephdata
- Created: 2021-04-26T13:47:00.000Z (about 5 years ago)
- Default Branch: main
- Last Pushed: 2023-03-20T21:52:05.000Z (about 3 years ago)
- Last Synced: 2025-05-07T03:03:52.105Z (about 1 year ago)
- Language: Jupyter Notebook
- Size: 1.71 MB
- Stars: 2
- Watchers: 8
- Forks: 1
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Follow The Money: Compare
> Tools and models for comparing followthemoney entities
## Overview
This repo provides the tools necessary to pre-process and train models to power
a cross-reference system on top of `followthemoney`. It was built with a tight
integration with [aleph](https://github.com/alephdata/aleph) in mind, however
this repo is aleph agnostic.
Currently, there are three main components to this system:
- Exporting training data
- Creating preprocessing filters (optional)
- Creating the training data
- Training a model
They are explained in further detail below.
## Installation
Installation is done through pipy. To install the minimal dependencies for
model evaluation, run
```
$ pip install followthemoney-compare
```
If you intend to train a model or do any model development, you should install
the development dependencies as well,
```
$ pip install followthemoney-compare[dev]
```
In addition, a Dockerfile is provided (which defaults to a minimal
followthemoney-compare installation) to simplify system dependencies.
## Pre-built models
Pre-built models and word frequency objects are available on OCCRP's public
data site. The URLs are:
- https://public.data.occrp.org/develop/models/word-frequencies/word_frequencies.zip
- https://public.data.occrp.org/develop/models/xref/glm_bernoulli_2e_wf-v0.4.1.pkl
The word_frequencies.zip archive should be unzipped and the envvar
`FTM_COMPARE_FREQUENCIES_DIR` should be set with the path to the unzipped data.
The model file can be loaded with pickle and used immediately. This pre-built
model achives the following accuracy-precision-recall on a dataset build from
https://aleph.occrp.org/,
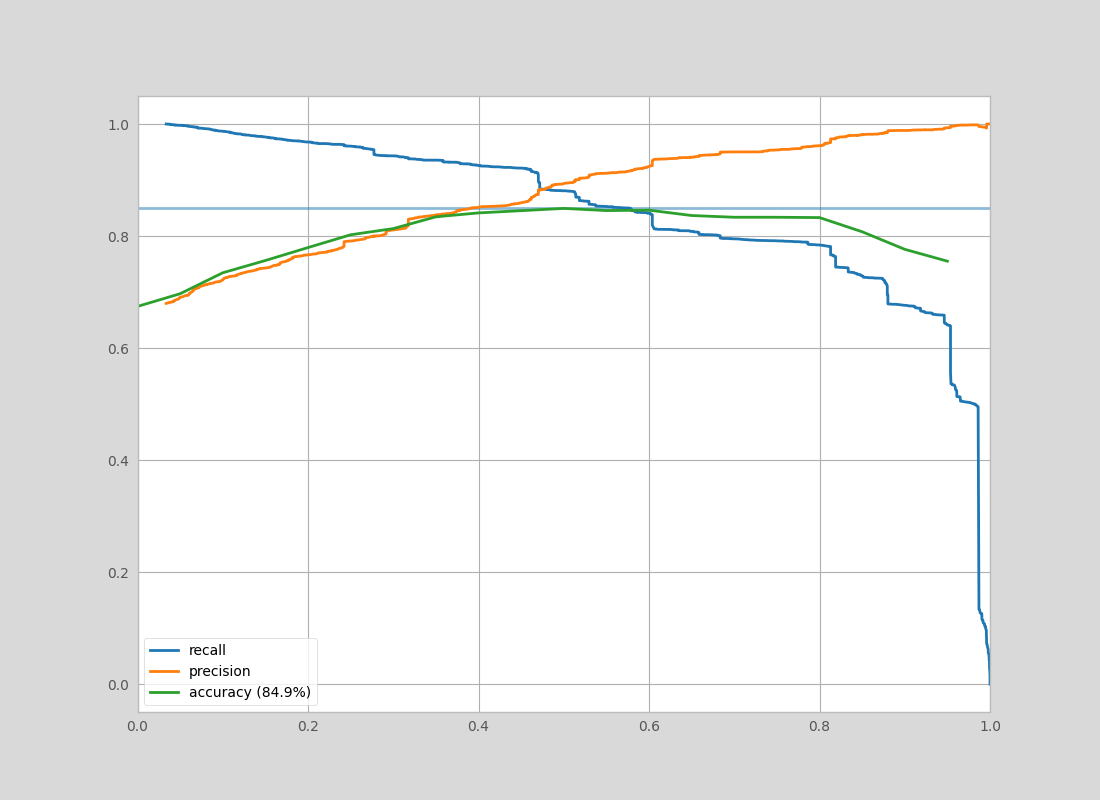
### Exporting Training Data
The initial data feeding this system comes from the aleph profile system. In
this system, users see proposed entity matches and decide whether the two
entities are indeed the same or not. Using the aleph profile API endpoint
(`/api/2/entitysets?filter:type=profile&filter:collection_id=`)
or by using the aleph profile export utility (`$ aleph dump-profiles`), you can
export these user decisions into JSON format.
This JSON data includes a profile ID, the two entities being compared, which
collections they originate from and the user decision regarding their
similarity. If multiple positive matches all have the same profile ID, we can
consider all of the entities to be the same. As a result, many judgements on
one profile generally gives more training data than the same number of
judgements on different profiles.
In addition to this human labeled data, you can optionally provide a list of
entities that can be used to create smarter pre-processing filters to clean the
data. This is done by exporting raw entities out of aleph and making sure that
the entities have a `collection_id` field (depending on your export method,
this may have to be added manually).
### Creating preprocessing filters (optional)
In order to reduce noise in the entity properties, we calculate an approximate
[TF-IDF](https://en.wikipedia.org/wiki/Tf%E2%80%93idf) using a [count-min
sketch](https://en.wikipedia.org/wiki/Count%E2%80%93min_sketch). Using this
system, we are able to weight each token by how "informative" it is and help
the resulting models from focusing on very common tokens (tokens like common
last names, or the term "corporation" for companies).
To make this possible, the subcommand `$ followthemoney-compare
create-word-frequency` is used. It takes in a flat file of entities (including
their `collection_id`), tokenizes the `name` property and accumulates counts
for token frequency for all entities, token frequency per schema and number of
collections that token was seen in.
When creating these structures, you can decide how large the acceptable error
is for the approximate TF-IDF. The confidence and error-rate has been tuned to
give reasonable results on the scale of data that OCCRP's Aleph installation
provides. In this case, each structure is ~8MB and gives 0.01% error 99.95% of
the time. The error rates and confidence level can be tuned for the amount of
data you intend on using in order to adjust the size of the resulting structure.
The `create-word-frequency` subcommand saves the resulting counts into a
directory structure containing the count-min sketches. A path to this directory
should be saved in your `FTM_COMPARE_FREQUENCIES_DIR` environment variable (it
defaults to "./data/word_frequencies/").
```
$ cat ./data/entities.json | \
followthemoney-compare create-word-frequency ./data/word-frequency/
```
### Creating the training data
In order to speed up training, all entity comparison features that the model
uses are pre-computed and saved into a pandas data frame. In order to create
this data frame, run the `$ followthemoney-compare create-data` subcommand. This
will use the count-min sketch filters calculated in the previous step if they
are available (if not, a UserWarning will be issued to make sure you know!).
Note that the progress bar while doing this step can be pretty jumpy if you have
large profiles. Be patient with this step as it can take upwards of an hour to
complete. If you find yourself constantly rebuilding the training data (ie: if
you are tuning the model features), this may phase is ripe for optimization.
```
$ export FTM_COMPARE_FREQUENCIES_DIR="./data/word-frequency" # optional
$ followthemoney-compare create-data \
./data/profiles-export/ ./data/training-data.pkl
```
### Training a model
All models can be trained using the same CLI. In order to see the available
models, run the command `$ followthemoney-compare list-models`. Currently, the
`glm_bernoulli_2e` model performs best, particularly on entities that can have
different levels of completeness.
```
$ export FTM_COMPARE_FREQUENCIES_DIR="./data/word-frequency" # optional
$ followthemoney-compare train \
--plot "./data/models/glm_bernoulli_2e.png" \
glm_bernoulli_2e \
./data/training-data.pkl \
"./data/models/glm_bernoulli_2e.pkl"
```
Once trained, the optional parameter `--plot` will create a
accuracy/precision/recall curve for the resulting model which can be used for
diagnostics.
The resulting model can be loaded using `pickle` or the
`followthemoney_compare.models.GLMBernouli2EEvaluate.load_pickles` method. This
model file is a reduced version of the trained model which is ideal for fast
evaluation with minimal dependencies and resource overhead. However, it also
lacks diagnostic and intermediary variables used for the training of the model.
As a result, when creating a new model type it is probably best to train the
models using the python API and to only use the CLI tool when training a known
model.
Evaluation of the resulting evaluation object is quite simple and flexible. It
provides the method:
- predict(): returns True / False representing whether the arguments are or
aren't matches
- predict_proba(): return a probability from (0, 1) that the arguments are
matches
- predict_std(): return a standard deviation, or confidence, of the prediction
(higher means less confidence)
- predict_proba_std(): returns both the match probability and the standard
deviation faster than calling both methods individually (not all models have
this)
The arguments to these functions can take the following forms:
- DataFrame: a DataFrame in the same format as the one returned by the
`create-data` command
- dict: a dictionary from the output of
`followthemoney_compare.compare.scores()`
- list of proxy pairs: A tuple of two `followthemoney.proxy.EntityProxy`
objects or a list of these pairs.
## Model Descriptions
### Sample Weighting
In order to help alleviate potential noise in our training data, each sample is
weighted. The weights have two contributions: the user weight and the sample
weight.
The user weight applies a weight to all judgements made by a user based on how
many judgements they submitted. This weighting prefers users who have made 100+
submissions and gradually down-weights users who have made substantially less
(code in `followthemoney_compare.lib.utils user_weight()`
The sample weight looks at the potential information content in the entity
pairing. It down-weights samples who are trivially the same or trivially
different (ie: two entities where all properties are exactly the same or
completely different). It does this by taking the average score from
`compare.scores()` and down-sampling entities that are far from an average score
of 0.25 - 0.7 (code in `followthemoney_compare.lib.utils.pair_weight()`.
The product of these two weights create a sample's effective weight which is
used in the models.
### GLM Bernoulli 2E
This model uses [pymc3](https://docs.pymc.io/) to fit a model using
[MCMC](https://en.wikipedia.org/wiki/Markov_chain_Monte_Carlo). As input, the
model uses the output of `followthemoney_compare.compare.scores`, which
compares followthemoney property groups between two entities, in addition to
the auxiliary variables which show how many properties are shared by both
entities and how many are just in one entity.
The following is a list of features used in the model. The value for `name`,
for example, is the numerical value from (0, 1) from
`followthemoney_compare.compare.scores` representing the similarity of both
entities "name" properties.
- name
- country
- date
- identifier
- address
- phone
- email
- iban
- url
- pct_share_prop: percentage of possible properties shared by the two entities
- pct_miss_prop: percentage of possible properties that only one entity has
- pct_share_prop^2
- name * pct_share_prop
- name^2
- pct_share_prop * pct_miss_prop
- pct_miss_prop^2
- name * identifier
- country * pct_share_prop
- identifier^2
- identifier * pct_miss_prop
- date^2
- address^2
All these features are fed into a logistic regression with a bias and fit using
the sample weights to help remove noise.
When a model is trained using this method using the CLI, a summary of the MCMC
process is displayed before exiting. Some things to look for to make sure the
model performed well:
- The SD (standard deviation) of the parameters should be low. Any variables
with a high standard deviation were not particularly useful for the
classification and should be reconsidered
- The `bulk_essi` field should be reasonably high. This field shows the
effective number of samples used to fit this parameter. If it is quite low,
then your data isn't well represented by the model or the training data is
too noisy.
- Inspect the accuracy-precision-recall curve and make sure the model is
sensible.
## Improvements
- [ ] Parallelize training data creation
- [ ] Better test/train split (stratified group sampling on collection id?
k-folds?)
- [ ] Better feature engineering or deep learning models?