https://github.com/amaiya/onprem
A toolkit for applying on-premises large language models to non-public data
https://github.com/amaiya/onprem
Last synced: 7 months ago
JSON representation
A toolkit for applying on-premises large language models to non-public data
- Host: GitHub
- URL: https://github.com/amaiya/onprem
- Owner: amaiya
- License: apache-2.0
- Created: 2023-08-29T14:46:45.000Z (about 2 years ago)
- Default Branch: master
- Last Pushed: 2025-05-10T22:08:39.000Z (7 months ago)
- Last Synced: 2025-05-10T22:15:17.727Z (7 months ago)
- Language: Jupyter Notebook
- Homepage: https://amaiya.github.io/onprem
- Size: 7.48 MB
- Stars: 716
- Watchers: 7
- Forks: 35
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Citation: CITATION.cff
Awesome Lists containing this project
- jimsghstars - amaiya/onprem - A tool for running on-premises large language models with non-public data (Jupyter Notebook)
README
# OnPrem.LLM
> A document intelligence toolkit for applying on-premises large
> language models to non-public data
**[OnPrem.LLM](https://github.com/amaiya/onprem)** (or “OnPrem” for
short) is a simple Python package that makes it easier to apply large
language models (LLMs) to non-public data on your own machines (possibly
behind corporate firewalls). Inspired largely by the
[privateGPT](https://github.com/imartinez/privateGPT) GitHub repo,
**OnPrem.LLM** is intended to help integrate local LLMs into practical
applications.
The full documentation is [here](https://amaiya.github.io/onprem/).
A Google Colab demo of installing and using **OnPrem.LLM** is
[here](https://colab.research.google.com/drive/1LVeacsQ9dmE1BVzwR3eTLukpeRIMmUqi?usp=sharing).
------------------------------------------------------------------------

*Latest News* 🔥
- \[2025/04\] v0.13.0 released and now includes streamlined support for
Ollama and many cloud LLMs via special URLs (e.g.,
`model_url="ollama://llama3.2"`,
`model_url="anthropic://claude-3-7-sonnet-latest"`). See the [cheat
sheet](https://amaiya.github.io/onprem/#how-to-use) for examples.
(**Note: Please use `onprem>=0.13.1` due to bug in v0.13.0.**)
- \[2025/04\] v0.12.0 released and now includes a re-vamped and improved
Web UI with support for interactive chatting, document
question-answering (RAG), and document search (both keyword searches
and semantic searches). See the [Web UI
documentation](https://amaiya.github.io/onprem/webapp.html) for more
information.
- \[2025/03\] v0.11.0 released. Default model changed to Zephyr-7b-beta.
- \[2025/03\] v0.10.0 released and now includes built-in support for
[sparse vector
stores](https://amaiya.github.io/onprem/#talk-to-your-documents). To
select the store type, supply either `store_type='dense'` or
`store_type='sparse'` when instantiating the
[`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm). This is a
breaking change as vector stores are now stored in subfolders (either
“sparse” or “dense”). If you have an existing dense vector store that
you still want to use, please move to a subfolder named “*dense*”:
`mv onprem_data/vectordb/* onprem_data/vectordb/dense`.
- \[2025/02\] v0.9.0 released and now includes built-in support for
[self-ask
prompting](https://learnprompting.org/docs/advanced/few_shot/self_ask)
with RAG and better table question-answering.
- \[2025/02\] v0.8.0 released and now includes support for [training a
wide range of different text classification
models](https://amaiya.github.io/onprem/pipelines.classifier.html#example-training-hugging-face-transformer-models).
- \[2024/12\] v0.7.0 released and now includes support for [structured
outputs](https://amaiya.github.io/onprem/#structured-and-guided-outputs).
- \[2024/12\] v0.6.0 released and now includes support for PDF to
Markdown conversion (which includes Markdown representations of
tables), as shown
[here](https://amaiya.github.io/onprem/#extract-text-from-documents).
- \[2024/11\] v0.5.0 released and now includes support for running LLMs
with Hugging Face
[transformers](https://github.com/huggingface/transformers) as the
backend instead of
[llama.cpp](https://github.com/abetlen/llama-cpp-python). See [this
example](https://amaiya.github.io/onprem/#using-hugging-face-transformers-instead-of-llama.cpp).
- \[2024/11\] v0.4.0 released and now includes a `default_model`
parameter to more easily use models like **Llama-3.1** and
**Zephyr-7B-beta**.
- \[2024/10\] v0.3.0 released and now includes support for
[concept-focused
summarization](https://amaiya.github.io/onprem/examples_summarization.html#concept-focused-summarization)
- \[2024/09\] v0.2.0 released and now includes PDF OCR support and
better PDF table handling.
- \[2024/06\] v0.1.0 of **OnPrem.LLM** has been released. Lots of new
updates!
- [Ability to use with any OpenAI-compatible
API](https://amaiya.github.io/onprem/#connecting-to-llms-served-through-rest-apis)
(e.g., vLLM, Ollama, OpenLLM, etc.).
- Pipeline for [information
extraction](https://amaiya.github.io/onprem/examples_information_extraction.html)
from raw documents.
- Pipeline for [few-shot text
classification](https://amaiya.github.io/onprem/examples_classification.html)
(i.e., training a classifier on a tiny number of labeled examples)
along with the ability to explain few-shot predictions.
- Default model changed to
[Mistral-7B-Instruct-v0.2](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF)
- [API augmentations and bug
fixes](https://github.com/amaiya/onprem/blob/master/CHANGELOG.md)
------------------------------------------------------------------------
## Install
Once you have [installed
PyTorch](https://pytorch.org/get-started/locally/), you can install
**OnPrem.LLM** with the following steps:
1. Install **llama-cpp-python**:
- **CPU:** `pip install llama-cpp-python` ([extra
steps](https://github.com/amaiya/onprem/blob/master/MSWindows.md)
required for Microsoft Windows)
- **GPU**: Follow [instructions
below](https://amaiya.github.io/onprem/#on-gpu-accelerated-inference).
2. Install **OnPrem.LLM**: `pip install onprem`
**Note:** Installing **llama-cpp-python** is optional if either the
following is true:
- You use Hugging Face Transformers (instead of llama-cpp-python) as the
LLM backend by supplying the `model_id` parameter when instantiating
an LLM, as [shown
here](https://amaiya.github.io/onprem/#using-hugging-face-transformers-instead-of-llama.cpp).
- You are using **OnPrem.LLM** with an LLM being served through an
[external REST API](#connecting-to-llms-served-through-rest-apis)
(e.g., Ollama, vLLM, OpenLLM).
- You are using **Onprem.LLM** with a cloud LLM (more information
below).
### On GPU-Accelerated Inference With `llama-cpp-python`
When installing **llama-cpp-python** with
`pip install llama-cpp-python`, the LLM will run on your **CPU**. To
generate answers much faster, you can run the LLM on your **GPU** by
building **llama-cpp-python** based on your operating system.
- **Linux**:
`CMAKE_ARGS="-DGGML_CUDA=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir`
- **Mac**: `CMAKE_ARGS="-DGGML_METAL=on" pip install llama-cpp-python`
- **Windows 11**: Follow the instructions
[here](https://github.com/amaiya/onprem/blob/master/MSWindows.md#using-the-system-python-in-windows-11s).
- **Windows Subsystem for Linux (WSL2)**: Follow the instructions
[here](https://github.com/amaiya/onprem/blob/master/MSWindows.md#using-wsl2-with-gpu-acceleration).
For Linux and Windows, you will need [an up-to-date NVIDIA
driver](https://www.nvidia.com/en-us/drivers/) along with the [CUDA
toolkit](https://developer.nvidia.com/cuda-downloads) installed before
running the installation commands above.
After following the instructions above, supply the `n_gpu_layers=-1`
parameter when instantiating an LLM to use your GPU for fast inference:
``` python
llm = LLM(n_gpu_layers=-1, ...)
```
Quantized models with 8B parameters and below can typically run on GPUs
with as little as 6GB of VRAM. If a model does not fit on your GPU
(e.g., you get a “CUDA Error: Out-of-Memory” error), you can offload a
subset of layers to the GPU by experimenting with different values for
the `n_gpu_layers` parameter (e.g., `n_gpu_layers=20`). Setting
`n_gpu_layers=-1`, as shown above, offloads all layers to the GPU.
See [the FAQ](https://amaiya.github.io/onprem/#faq) for extra tips, if
you experience issues with
[llama-cpp-python](https://pypi.org/project/llama-cpp-python/)
installation.
## How to Use
### Setup
``` python
from onprem import LLM
llm = LLM(verbose=False) # default model and engine are used
```
#### Cheat Sheet
*Local Models:* A number of different local LLM engines are supported.
- **Llama-cpp**: `llm = LLM(default_model="llama", n_gpu_layers=-1)`
- **Llama-cpp with selected GGUF model via URL**:
``` python
llm = LLM(model_url='https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/resolve/main/zephyr-7b-beta.Q4_K_M.gguf',
prompt_template= "<|system|>\n\n<|user|>\n{prompt}\n<|assistant|>", n_gpu_layers=-1)
```
- **Llama-cpp with selected GGUF model via file path**:
``` python
llm = LLM(model_url='zephyr-7b-beta.Q4_K_M.gguf',
model_download_path='/path/to/folder/to/where/you/downloaded/model',
prompt_template= "<|system|>\n\n<|user|>\n{prompt}\n<|assistant|>", n_gpu_layers=-1)
```
- **Hugging Face Transformers**:
`llm = LLM(model_id='Qwen/Qwen2.5-0.5B-Instruct')`
- **Ollama**: `llm = LLM(model_url="ollama://llama3.2", api_key='na')`
- **Also Ollama**:
`llm = LLM(model_url="ollama/llama3.2", api_key='na')`
- **Also Ollama**:
`llm = LLM(model_url='http://localhost:11434/v1', api_key='na', model='llama3.2')`
- **VLLM**:
`llm = LLM(model_url='http://localhost:8000/v1', api_key='na', model='Qwen/Qwen2.5-0.5B-Instruct')`
*Cloud Models:* Despite the focus on local LLMs, cloud LLMs are also
supported (a warning will be issued that your prompts are being sent
externally):
- **Anthropic Claude**:
`llm = LLM(model_url="anthropic://claude-3-7-sonnet-latest")`
- **Also Anthropic Claude**:
`llm = LLM(model_url="anthropic/claude-3-7-sonnet-latest")`
- **OpenAI GPT-4o**: `llm = LLM(model_url="openai://gpt-4o")`
- **Also OpenAI GPT-4o**: `llm = LLM(model_url="openai/gpt-4o")`
The instantiations above are described in more detail below.
#### Specifying the Local Model to Use
The default LLM engine is
[llama-cpp-python](https://github.com/abetlen/llama-cpp-python), and the
default model is currently a 7B-parameter model called
**Zephyr-7B-beta**, which is automatically downloaded and used. The two
other default models are `llama` and `mistral`. For instance, if
`default_model='llama'` is supplied, then a **Llama-3.1-8B-Instsruct**
model is automatically downloaded and used:
``` python
# Llama 3.1 is downloaded here and the correct prompt template for Llama-3.1 is automatically configured and used
llm = LLM(default_model='llama')
```
*Choosing Your Own Models:* Of course, you can also easily supply the
URL or path to an LLM of your choosing to
[`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm) (see the
[FAQ](https://amaiya.github.io/onprem/#faq) for an example).
*Supplying Extra Parameters:* Any extra parameters supplied to
[`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm) are forwarded
directly to
[llama-cpp-python](https://github.com/abetlen/llama-cpp-python), the
default LLM engine.
#### Changing the Default LLM Engine to Hugging Face Transformers
If `default_engine="transformers"` is supplied to
[`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm), Hugging Face
[transformers](https://github.com/huggingface/transformers) is used as
the LLM engine (and `transformers.pipeline` receives any extra
parameters supplied to
[`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm)). If
supplying a `model_id` parameter, the default LLM engine is
automatically changed to Hugging Face
[transformers](https://github.com/huggingface/transformers).
``` python
# LLama-3.1 model quantized using AWQ is downloaded and run with Hugging Face transformers (requires GPU)
llm = LLM(default_model='llama', default_engine='transformers')
# Using a custom model with Hugging Face Transformers
llm = LLM(model_id='Qwen/Qwen2.5-0.5B-Instruct', device_map='cpu')
```
See
[here](https://amaiya.github.io/onprem/#using-hugging-face-transformers-instead-of-llama.cpp)
for more information about using Hugging Face
[transformers](https://github.com/huggingface/transformers) as the LLM
engine.
#### Using LLMs Served Through Local APIs
You can connect to any LLM served through local OpenAI-style APIs:
``` python
# connecting to an LLM served by Ollama
lm = LLM(model_url='http://localhost:11434/v1', api_key='NA', model='llama3.2')
# connecting to an LLM served through vLLM (set API key as needed)
llm = LLM(model_url='http://localhost:8000/v1', api_key='token-abc123', model='Qwen/Qwen2.5-0.5B-Instruct')`
```
See
[here](https://amaiya.github.io/onprem/#connecting-to-llms-served-through-rest-apis)
for more information on local APIs.
#### Using Cloud LLMs
As mentioned above, despite our focus on local LLMs, you can also use
**OnPrem.LLM** with many different cloud LLMs by simply supplying
special URLs to indicate the provider and model:
- **Anthropic Claude**:
`llm = LLM(model_url="anthropic://claude-3-7-sonnet-20250219")`
- **OpenAI GPT-4o**: `llm = LLM(model_url="openai://gpt-4o")`
**OnPrem.LLM** suppports any provider and model supported by the
[LiteLLM](https://github.com/BerriAI/litellm) package.
More information on using OpenAI models specifically with **OnPrem.LLM**
is [here](https://amaiya.github.io/onprem/examples_openai.html).
#### Supplying Parameters to the LLM Engine
The default context window size (`n_ctx`) is set to 3900 and the default
output size (`max_tokens`) is set 512. Both are configurable parameters
to [`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm). Increase
if you have larger prompts or need longer outputs. Other parameters
(e.g., `api_key`, `device_map`, etc.) can be supplied directly to
[`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm) and will be
routed to the LLM engine or API (e.g., llama-cpp-python, Hugging Face
transformers, vLLM, OpenAI, etc.).
### Send Prompts to the LLM to Solve Problems
This is an example of few-shot prompting, where we provide an example of
what we want the LLM to do.
``` python
prompt = """Extract the names of people in the supplied sentences.
Separate names with commas and place on a single line.
# Example 1:
Sentence: James Gandolfini and Paul Newman were great actors.
People:
James Gandolfini, Paul Newman
# Example 2:
Sentence:
I like Cillian Murphy's acting. Florence Pugh is great, too.
People:"""
saved_output = llm.prompt(prompt, stop=['\n\n'])
```
Cillian Murphy, Florence Pugh
Additional prompt examples are [shown
here](https://amaiya.github.io/onprem/examples.html).
### Talk to Your Documents
Answers are generated from the content of your documents (i.e.,
[retrieval augmented generation](https://arxiv.org/abs/2005.11401) or
RAG). Here, we will use [GPU
offloading](https://amaiya.github.io/onprem/#speeding-up-inference-using-a-gpu)
to speed up answer generation using the default model. However, the
Zephyr-7B model may perform even better, responds faster, and is used in
our [example
notebook](https://amaiya.github.io/onprem/examples_rag.html).
``` python
from onprem import LLM
llm = LLM(n_gpu_layers=-1, store_type='sparse', verbose=False)
```
llama_new_context_with_model: n_ctx_per_seq (3904) < n_ctx_train (32768) -- the full capacity of the model will not be utilized
#### Step 1: Ingest the Documents into a Vector Database
As of v0.10.0, you have the option of storing documents in either a
dense vector store (i.e., Chroma) or a sparse vector store (i.e., a
built-in keyword search index). Sparse vector stores sacrifice a small
amount of inference speed for significant improvements in ingestion
speed (useful for larger document sets) and also assume answer sources
will include at least one word from the question. To select the store
type, supply either `store_type="dense"` or `store_type="sparse"` when
creating the [`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm).
As you can see above, we use a sparse vector store here.
``` python
llm.ingest("./tests/sample_data")
```
Creating new vectorstore at /home/amaiya/onprem_data/vectordb/sparse
Loading documents from ./tests/sample_data
Split into 354 chunks of text (max. 500 chars each for text; max. 2000 chars for tables)
Ingestion complete! You can now query your documents using the LLM.ask or LLM.chat methods
Loading new documents: 100%|██████████████████████| 6/6 [00:09<00:00, 1.51s/it]
Processing and chunking 43 new documents: 100%|██████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 116.11it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 354/354 [00:00<00:00, 2548.70it/s]
#### Step 2: Answer Questions About the Documents
``` python
question = """What is ktrain?"""
result = llm.ask(question)
```
ktrain is a low-code machine learning platform. It provides out-of-the-box support for training models on various types of data such as text, vision, graph, and tabular.
The sources used by the model to generate the answer are stored in
`result['source_documents']`:
``` python
print("\nSources:\n")
for i, document in enumerate(result["source_documents"]):
print(f"\n{i+1}.> " + document.metadata["source"] + ":")
print(document.page_content)
```
Sources:
1.> /home/amaiya/projects/ghub/onprem/nbs/tests/sample_data/ktrain_paper/ktrain_paper.pdf:
transferred to, and executed on new data in a production environment.
ktrain is a Python library for machine learning with the goal of presenting a simple,
unified interface to easily perform the above steps regardless of the type of data (e.g., text
vs. images vs. graphs). Moreover, each of the three steps above can be accomplished in
©2022 Arun S. Maiya.
License: CC-BY 4.0, see https://creativecommons.org/licenses/by/4.0/. Attribution requirements are
2.> /home/amaiya/projects/ghub/onprem/nbs/tests/sample_data/ktrain_paper/ktrain_paper.pdf:
custom models and data formats, as well. Inspired by other low-code (and no-code) open-
source ML libraries such as fastai (Howard and Gugger, 2020) and ludwig (Molino et al.,
2019), ktrain is intended to help further democratize machine learning by enabling begin-
ners and domain experts with minimal programming or data science experience to build
sophisticated machine learning models with minimal coding. It is also a useful toolbox for
3.> /home/amaiya/projects/ghub/onprem/nbs/tests/sample_data/ktrain_paper/ktrain_paper.pdf:
Apache license, and available on GitHub at: https://github.com/amaiya/ktrain.
2. Building Models
Supervised learning tasks in ktrain follow a standard, easy-to-use template.
STEP 1: Load and Preprocess Data. This step involves loading data from different
sources and preprocessing it in a way that is expected by the model. In the case of text,
this may involve language-specific preprocessing (e.g., tokenization). In the case of images,
4.> /home/amaiya/projects/ghub/onprem/nbs/tests/sample_data/ktrain_paper/ktrain_paper.pdf:
AutoKeras (Jin et al., 2019) and AutoGluon (Erickson et al., 2020) lack some key “pre-
canned” features in ktrain, which has the strongest support for natural language processing
and graph-based data. Support for additional features is planned for the future.
5. Conclusion
This work presented ktrain, a low-code platform for machine learning. ktrain currently in-
cludes out-of-the-box support for training models on text, vision, graph, and tabular
### Extract Text from Documents
The
[`load_single_document`](https://amaiya.github.io/onprem/ingest.base.html#load_single_document)
function can extract text from a range of different document formats
(e.g., PDFs, Microsoft PowerPoint, Microsoft Word, etc.). It is
automatically invoked when calling
[`LLM.ingest`](https://amaiya.github.io/onprem/llm.base.html#llm.ingest).
Extracted text is represented as LangChain `Document` objects, where
`Document.page_content` stores the extracted text and
`Document.metadata` stores any extracted document metadata.
For PDFs, in particular, a number of different options are available
depending on your use case.
**Fast PDF Extraction (default)**
- **Pro:** Fast
- **Con:** Does not infer/retain structure of tables in PDF documents
``` python
from onprem.ingest import load_single_document
docs = load_single_document('tests/sample_data/ktrain_paper/ktrain_paper.pdf')
docs[0].metadata
```
{'source': '/home/amaiya/projects/ghub/onprem/nbs/sample_data/1/ktrain_paper.pdf',
'file_path': '/home/amaiya/projects/ghub/onprem/nbs/sample_data/1/ktrain_paper.pdf',
'page': 0,
'total_pages': 9,
'format': 'PDF 1.4',
'title': '',
'author': '',
'subject': '',
'keywords': '',
'creator': 'LaTeX with hyperref',
'producer': 'dvips + GPL Ghostscript GIT PRERELEASE 9.22',
'creationDate': "D:20220406214054-04'00'",
'modDate': "D:20220406214054-04'00'",
'trapped': ''}
**Automatic OCR of PDFs**
- **Pro:** Automatically extracts text from scanned PDFs
- **Con:** Slow
The
[`load_single_document`](https://amaiya.github.io/onprem/ingest.base.html#load_single_document)
function will automatically OCR PDFs that require it (i.e., PDFs that
are scanned hard-copies of documents). If a document is OCR’ed during
extraction, the `metadata['ocr']` field will be populated with `True`.
``` python
docs = load_single_document('tests/sample_data/ocr_document/lynn1975.pdf')
docs[0].metadata
```
{'source': '/home/amaiya/projects/ghub/onprem/nbs/sample_data/4/lynn1975.pdf',
'ocr': True}
**Markdown Conversion in PDFs**
- **Pro**: Better chunking for QA
- **Con**: Slower than default PDF extraction
The
[`load_single_document`](https://amaiya.github.io/onprem/ingest.base.html#load_single_document)
function can convert PDFs to Markdown instead of plain text by supplying
the `pdf_markdown=True` as an argument:
``` python
docs = load_single_document('your_pdf_document.pdf',
pdf_markdown=True)
```
Converting to Markdown can facilitate downstream tasks like
question-answering. For instance, when supplying `pdf_markdown=True` to
[`LLM.ingest`](https://amaiya.github.io/onprem/llm.base.html#llm.ingest),
documents are chunked in a Markdown-aware fashion (e.g., the abstract of
a research paper tends to be kept together into a single chunk instead
of being split up). Note that Markdown will not be extracted if the
document requires OCR.
**Inferring Table Structure in PDFs**
- **Pro**: Makes it easier for LLMs to analyze information in tables
- **Con**: Slower than default PDF extraction
When supplying `infer_table_structure=True` to either
[`load_single_document`](https://amaiya.github.io/onprem/ingest.base.html#load_single_document)
or
[`LLM.ingest`](https://amaiya.github.io/onprem/llm.base.html#llm.ingest),
tables are inferred and extracted from PDFs using a TableTransformer
model. Tables are represented as **Markdown** (or **HTML** if Markdown
conversion is not possible).
``` python
docs = load_single_document('your_pdf_document.pdf',
infer_table_structure=True)
```
**Parsing Extracted Text Into Sentences or Paragraphs**
For some analyses (e.g., using prompts for information extraction), it
may be useful to parse the text extracted from documents into individual
sentences or paragraphs. This can be accomplished using the
[`segment`](https://amaiya.github.io/onprem/utils.html#segment)
function:
``` python
from onprem.ingest import load_single_document
from onprem.utils import segment
text = load_single_document('tests/sample_data/sotu/state_of_the_union.txt')[0].page_content
```
``` python
segment(text, unit='paragraph')[0]
```
'Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.'
``` python
segment(text, unit='sentence')[0]
```
'Madam Speaker, Madam Vice President, our First Lady and Second Gentleman.'
### Summarization Pipeline
Summarize your raw documents (e.g., PDFs, MS Word) with an LLM.
#### Map-Reduce Summarization
Summarize each chunk in a document and then generate a single summary
from the individual summaries.
``` python
from onprem import LLM
llm = LLM(n_gpu_layers=-1, verbose=False, mute_stream=True) # disabling viewing of intermediate summarization prompts/inferences
```
``` python
from onprem.pipelines import Summarizer
summ = Summarizer(llm)
resp = summ.summarize('tests/sample_data/ktrain_paper/ktrain_paper.pdf', max_chunks_to_use=5) # omit max_chunks_to_use parameter to consider entire document
print(resp['output_text'])
```
Ktrain is an open-source machine learning library that offers a unified interface for various machine learning tasks. The library supports both supervised and non-supervised machine learning, and includes methods for training models, evaluating models, making predictions on new data, and providing explanations for model decisions. Additionally, the library integrates with various explainable AI libraries such as shap, eli5 with lime, and others to provide more interpretable models.
#### Concept-Focused Summarization
Summarize a large document with respect to a particular concept of
interest.
``` python
from onprem import LLM
from onprem.pipelines import Summarizer
```
``` python
llm = LLM(default_model='zephyr', n_gpu_layers=-1, verbose=False, temperature=0)
summ = Summarizer(llm)
summary, sources = summ.summarize_by_concept('tests/sample_data/ktrain_paper/ktrain_paper.pdf', concept_description="question answering")
```
The context provided describes the implementation of an open-domain question-answering system using ktrain, a low-code library for augmented machine learning. The system follows three main steps: indexing documents into a search engine, locating documents containing words in the question, and extracting candidate answers from those documents using a BERT model pretrained on the SQuAD dataset. Confidence scores are used to sort and prune candidate answers before returning results. The entire workflow can be implemented with only three lines of code using ktrain's SimpleQA module. This system allows for the submission of natural language questions and receives exact answers, as demonstrated in the provided example. Overall, the context highlights the ease and accessibility of building sophisticated machine learning models, including open-domain question-answering systems, through ktrain's low-code interface.
### Information Extraction Pipeline
Extract information from raw documents (e.g., PDFs, MS Word documents)
with an LLM.
``` python
from onprem import LLM
from onprem.pipelines import Extractor
# Notice that we're using a cloud-based, off-premises model here! See "OpenAI" section below.
llm = LLM(model_url='openai://gpt-3.5-turbo', verbose=False, mute_stream=True, temperature=0)
extractor = Extractor(llm)
prompt = """Extract the names of research institutions (e.g., universities, research labs, corporations, etc.)
from the following sentence delimited by three backticks. If there are no organizations, return NA.
If there are multiple organizations, separate them with commas.
```{text}```
"""
df = extractor.apply(prompt, fpath='tests/sample_data/ktrain_paper/ktrain_paper.pdf', pdf_pages=[1], stop=['\n'])
df.loc[df['Extractions'] != 'NA'].Extractions[0]
```
/home/amaiya/projects/ghub/onprem/onprem/core.py:159: UserWarning: The model you supplied is gpt-3.5-turbo, an external service (i.e., not on-premises). Use with caution, as your data and prompts will be sent externally.
warnings.warn(f'The model you supplied is {self.model_name}, an external service (i.e., not on-premises). '+\
'Institute for Defense Analyses'
### Few-Shot Classification
Make accurate text classification predictions using only a tiny number
of labeled examples.
``` python
# create classifier
from onprem.pipelines import FewShotClassifier
clf = FewShotClassifier(use_smaller=True)
# Fetching data
from sklearn.datasets import fetch_20newsgroups
import pandas as pd
import numpy as np
classes = ["soc.religion.christian", "sci.space"]
newsgroups = fetch_20newsgroups(subset="all", categories=classes)
corpus, group_labels = np.array(newsgroups.data), np.array(newsgroups.target_names)[newsgroups.target]
# Wrangling data into a dataframe and selecting training examples
data = pd.DataFrame({"text": corpus, "label": group_labels})
train_df = data.groupby("label").sample(5)
test_df = data.drop(index=train_df.index)
# X_sample only contains 5 examples of each class!
X_sample, y_sample = train_df['text'].values, train_df['label'].values
# test set
X_test, y_test = test_df['text'].values, test_df['label'].values
# train
clf.train(X_sample, y_sample, max_steps=20)
# evaluate
print(clf.evaluate(X_test, y_test)['accuracy'])
#output: 0.98
# make predictions
clf.predict(['Elon Musk likes launching satellites.']).tolist()[0]
#output: sci.space
```
**TIP:** You can also easily train a wide range of [traditional text
classification
models](https://amaiya.github.io/onprem/pipelines.classifier.html) using
both Hugging Face transformers and scikit-learn as backends.
### Using Hugging Face Transformers Instead of Llama.cpp
By default, the LLM backend employed by **OnPrem.LLM** is
[llama-cpp-python](https://github.com/abetlen/llama-cpp-python), which
requires models in [GGUF format](https://huggingface.co/docs/hub/gguf).
As of v0.5.0, it is now possible to use [Hugging Face
transformers](https://github.com/huggingface/transformers) as the LLM
backend instead. This is accomplished by using the `model_id` parameter
(instead of supplying a `model_url` argument). In the example below, we
run the
[Llama-3.1-8B](https://huggingface.co/hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4)
model.
``` python
# llama-cpp-python does NOT need to be installed when using model_id parameter
llm = LLM(model_id="hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4", device_map='cuda')
```
This allows you to more easily use any model on the Hugging Face hub in
[SafeTensors format](https://huggingface.co/docs/safetensors/index)
provided it can be loaded with the Hugging Face `transformers.pipeline`.
Note that, when using the `model_id` parameter, the `prompt_template` is
set automatically by `transformers`.
The Llama-3.1 model loaded above was quantized using
[AWQ](https://huggingface.co/docs/transformers/main/en/quantization/awq),
which allows the model to fit onto smaller GPUs (e.g., laptop GPUs with
6GB of VRAM) similar to the default GGUF format. AWQ models will require
the [autoawq](https://pypi.org/project/autoawq/) package to be
installed: `pip install autoawq` (AWQ only supports Linux system,
including Windows Subsystem for Linux). If you do need to load a model
that is not quantized, you can supply a quantization configuration at
load time (known as “inflight quantization”). In the following example,
we load an unquantized [Zephyr-7B-beta
model](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) that will be
quantized during loading to fit on GPUs with as little as 6GB of VRAM:
``` python
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
bnb_4bit_use_double_quant=True,
)
llm = LLM(model_id="HuggingFaceH4/zephyr-7b-beta", device_map='cuda',
model_kwargs={"quantization_config":quantization_config})
```
When supplying a `quantization_config`, the
[bitsandbytes](https://huggingface.co/docs/bitsandbytes/main/en/installation)
library, a lightweight Python wrapper around CUDA custom functions, in
particular 8-bit optimizers, matrix multiplication (LLM.int8()), and 8 &
4-bit quantization functions, is used. There are ongoing efforts by the
bitsandbytes team to support multiple backends in addition to CUDA. If
you receive errors related to bitsandbytes, please refer to the
[bitsandbytes
documentation](https://huggingface.co/docs/bitsandbytes/main/en/installation).
### Connecting to LLMs Served Through REST APIs
**OnPrem.LLM** can be used with LLMs being served through any
OpenAI-compatible REST API. This means you can easily use **OnPrem.LLM**
with tools like [vLLM](https://github.com/vllm-project/vllm),
[OpenLLM](https://github.com/bentoml/OpenLLM),
[Ollama](https://ollama.com/blog/openai-compatibility), and the
[llama.cpp
server](https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md).
#### vLLM Example
For instance, using [vLLM](https://github.com/vllm-project/vllm), you
can serve an LLM as follows (replace the `--model` argument with model
you want to use):
``` sh
python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-0.5B-Instruct --dtype auto --api-key token-abc123
```
You can then connect OnPrem.LLM to the LLM by supplying the URL of the
server you just started:
``` python
from onprem import LLM
llm = LLM(model_url='http://localhost:8000/v1', api_key='token-abc123', model='Qwen/Qwen2.5-0.5B-Instruct')
# Note: The API key can either be supplied directly or stored in the OPENAI_API_KEY environment variable.
# If the server does not require an API key, `api_key` should still be supplied with a dummy value like 'na'.
# The model argument must exactly match what was supplied when starting the vLLM server.
```
That’s it! Solve problems with **OnPrem.LLM** as you normally would
(e.g., RAG question-answering, summarization, few-shot prompting, code
generation, etc.).
#### Ollama Example
After [downloading and installing Ollama](https://ollama.com/) and
pulling a model (eg., `ollama pull llama3.2`), you can use it in
OnPrem.LLM as follows:
``` python
from onprem import LLM
llm = LLM(model_url='http://localhost:11434/v1', api_key='NA', model='llama3.2')
output = llm.prompt('What is the capital of France?')
# OUTPUT:
# The capital of France is Paris.
```
If using OnPrem.LLM with Ollama or vLLM, then `llama-cpp-python` does
**not** need to be installed.
### Using OpenAI Models with OnPrem.LLM
Even when using on-premises language models, it can sometimes be useful
to have easy access to non-local, cloud-based models (e.g., OpenAI) for
testing, producing baselines for comparison, and generating synthetic
examples for fine-tuning. For these reasons, in spite of the name,
**OnPrem.LLM** now includes support for OpenAI chat models:
``` python
from onprem import LLM
llm = LLM(model_url='openai://gpt-4o', temperature=0)
```
/home/amaiya/projects/ghub/onprem/onprem/core.py:196: UserWarning: The model you supplied is gpt-4o, an external service (i.e., not on-premises). Use with caution, as your data and prompts will be sent externally.
warnings.warn(f'The model you supplied is {self.model_name}, an external service (i.e., not on-premises). '+\
This OpenAI [`LLM`](https://amaiya.github.io/onprem/llm.base.html#llm)
instance can now be used with as the engine for most features in
OnPrem.LLM (e.g., RAG, information extraction, summarization, etc.).
Here we simply use it for general prompting:
``` python
saved_result = llm.prompt('List three cute names for a cat and explain why each is cute.')
```
Certainly! Here are three cute names for a cat, along with explanations for why each is adorable:
1. **Whiskers**: This name is cute because it highlights one of the most distinctive and charming features of a cat—their whiskers. It's playful and endearing, evoking the image of a curious cat twitching its whiskers as it explores its surroundings.
2. **Mittens**: This name is cute because it conjures up the image of a cat with little white paws that look like they are wearing mittens. It's a cozy and affectionate name that suggests warmth and cuddliness, much like a pair of soft mittens.
3. **Pumpkin**: This name is cute because it brings to mind the warm, orange hues of a pumpkin, which can be reminiscent of certain cat fur colors. It's also associated with the fall season, which is often linked to comfort and coziness. Plus, the name "Pumpkin" has a sweet and affectionate ring to it, making it perfect for a beloved pet.
**Using Vision Capabilities in GPT-4o**
``` python
image_url = "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
saved_result = llm.prompt('Describe the weather in this image.', image_path_or_url=image_url)
```
The weather in the image appears to be clear and sunny. The sky is mostly blue with some scattered clouds, suggesting a pleasant day with good visibility. The sunlight is bright, illuminating the green grass and landscape.
**Using OpenAI-Style Message Dictionaries**
``` python
messages = [
{'content': [{'text': 'describe the weather in this image',
'type': 'text'},
{'image_url': {'url': image_url},
'type': 'image_url'}],
'role': 'user'}]
saved_result = llm.prompt(messages)
```
The weather in the image appears to be clear and sunny. The sky is mostly blue with some scattered clouds, suggesting a pleasant day with good visibility. The sunlight is bright, casting clear shadows and illuminating the green landscape.
**Azure OpenAI**
For Azure OpenAI models, use the following URL format:
``` python
llm = LLM(model_url='azure://', ...)
# is the Azure deployment name and additional Azure-specific parameters
# can be supplied as extra arguments to LLM (or set as environment variables)
```
### Structured and Guided Outputs
The
[`LLM.pydantic_prompt`](https://amaiya.github.io/onprem/llm.base.html#llm.pydantic_prompt)
method allows you to specify the desired structure of the LLM’s output
as a Pydantic model.
``` python
from pydantic import BaseModel, Field
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
from onprem import LLM
llm = LLM(default_model='llama', verbose=False)
structured_output = llm.pydantic_prompt('Tell me a joke.', pydantic_model=Joke)
```
llama_new_context_with_model: n_ctx_per_seq (3904) < n_ctx_train (131072) -- the full capacity of the model will not be utilized
{
"setup": "Why couldn't the bicycle stand alone?",
"punchline": "Because it was two-tired!"
}
The output is a Pydantic object instead of a string:
``` python
structured_output
```
Joke(setup="Why couldn't the bicycle stand alone?", punchline='Because it was two-tired!')
``` python
print(structured_output.setup)
print()
print(structured_output.punchline)
```
Why couldn't the bicycle stand alone?
Because it was two-tired!
You can also use **OnPrem.LLM** with the
[Guidance](https://github.com/guidance-ai/guidance) package to guide the
LLM to generate outputs based on your conditions and constraints. We’ll
show a couple of examples here, but see [our documentation on guided
prompts](https://amaiya.github.io/onprem/examples_guided_prompts.html)
for more information.
``` python
from onprem import LLM
llm = LLM(n_gpu_layers=-1, verbose=False)
from onprem.pipelines.guider import Guider
guider = Guider(llm)
```
With the Guider, you can use use Regular Expressions to control LLM
generation:
``` python
prompt = f"""Question: Luke has ten balls. He gives three to his brother. How many balls does he have left?
Answer: """ + gen(name='answer', regex='\d+')
guider.prompt(prompt, echo=False)
```
{'answer': '7'}
``` python
prompt = '19, 18,' + gen(name='output', max_tokens=50, stop_regex='[^\d]7[^\d]')
guider.prompt(prompt)
```
19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8,
{'output': ' 17, 16, 15, 14, 13, 12, 11, 10, 9, 8,'}
See [the
documentation](https://amaiya.github.io/onprem/examples_guided_prompts.html)
for more examples of how to use
[Guidance](https://github.com/guidance-ai/guidance) with **OnPrem.LLM**.
## Built-In Web App
**OnPrem.LLM** includes a built-in Web app to access the LLM. To start
it, run the following command after installation:
``` shell
onprem --port 8000
```
Then, enter `localhost:8000` (or `:8000` if running on
remote server) in a Web browser to access the application:
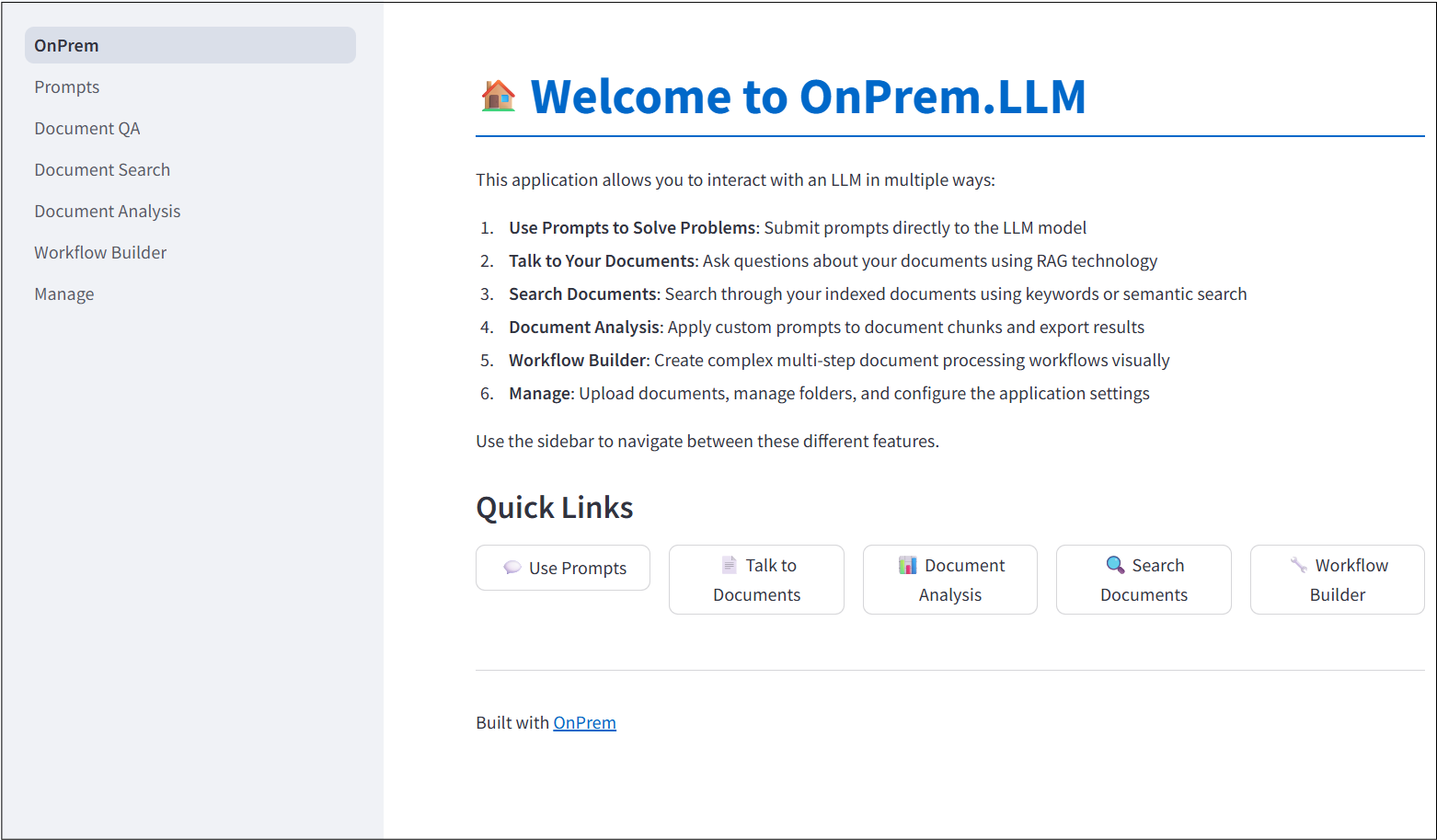
For more information, [see the corresponding
documentation](https://amaiya.github.io/onprem/webapp.html).
## FAQ
1. **How do I use other models with OnPrem.LLM?**
> You can supply the URL to other models to the `LLM` constructor,
> as we did above in the code generation example.
> As of v0.0.20, we support models in GGUF format, which supersedes
> the older GGML format. You can find llama.cpp-supported models
> with `GGUF` in the file name on
> [huggingface.co](https://huggingface.co/models?sort=trending&search=gguf).
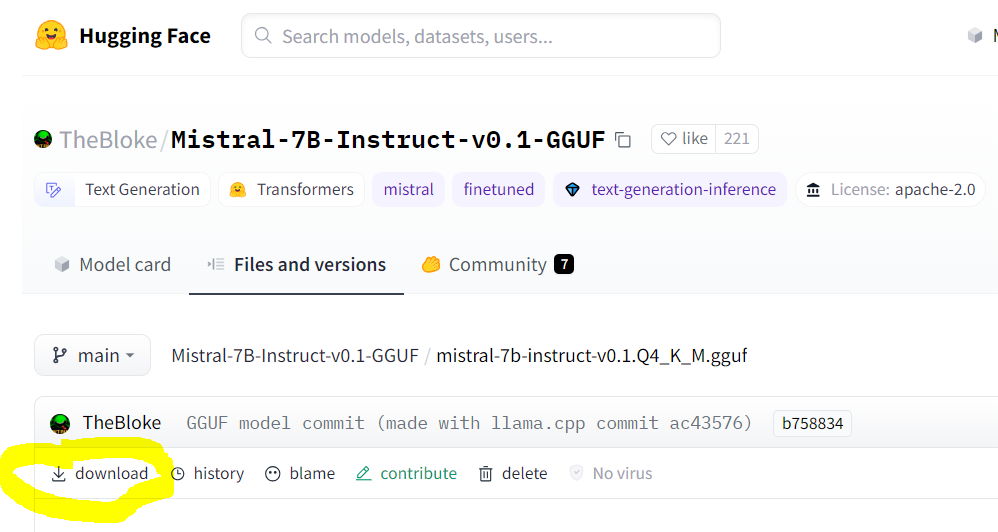
> Make sure you are pointing to the URL of the actual GGUF model
> file, which is the “download” link on the model’s page. An example
> for **Mistral-7B** is shown below:
> 
> Note that some models have specific prompt formats. For instance,
> the prompt template required for **Zephyr-7B**, as described on
> the [model’s
> page](https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF), is:
>
> `<|system|>\n\n<|user|>\n{prompt}\n<|assistant|>`
>
> So, to use the **Zephyr-7B** model, you must supply the
> `prompt_template` argument to the `LLM` constructor (or specify it
> in the `webapp.yml` configuration for the Web app).
>
> ``` python
> # how to use Zephyr-7B with OnPrem.LLM
> llm = LLM(model_url='https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/resolve/main/zephyr-7b-beta.Q4_K_M.gguf',
> prompt_template = "<|system|>\n\n<|user|>\n{prompt}\n<|assistant|>",
> n_gpu_layers=33)
> llm.prompt("List three cute names for a cat.")
> ```
2. **When installing `onprem`, I’m getting “build” errors related to
`llama-cpp-python` (or `chroma-hnswlib`) on Windows/Mac/Linux?**
> See [this LangChain documentation on
> LLama.cpp](https://python.langchain.com/docs/integrations/llms/llamacpp)
> for help on installing the `llama-cpp-python` package for your
> system. Additional tips for different operating systems are shown
> below:
> For **Linux** systems like Ubuntu, try this:
> `sudo apt-get install build-essential g++ clang`. Other tips are
> [here](https://github.com/oobabooga/text-generation-webui/issues/1534).
> For **Windows** systems, please try following [these
> instructions](https://github.com/amaiya/onprem/blob/master/MSWindows.md).
> We recommend you use [Windows Subsystem for Linux
> (WSL)](https://learn.microsoft.com/en-us/windows/wsl/install)
> instead of using Microsoft Windows directly. If you do need to use
> Microsoft Window directly, be sure to install the [Microsoft C++
> Build
> Tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/)
> and make sure the **Desktop development with C++** is selected.
> For **Macs**, try following [these
> tips](https://github.com/imartinez/privateGPT/issues/445#issuecomment-1563333950).
> There are also various other tips for each of the above OSes in
> [this privateGPT repo
> thread](https://github.com/imartinez/privateGPT/issues/445). Of
> course, you can also [easily
> use](https://colab.research.google.com/drive/1LVeacsQ9dmE1BVzwR3eTLukpeRIMmUqi?usp=sharing)
> **OnPrem.LLM** on Google Colab.
> Finally, if you still can’t overcome issues with building
> `llama-cpp-python`, you can try [installing the pre-built wheel
> file](https://abetlen.github.io/llama-cpp-python/whl/cpu/llama-cpp-python/)
> for your system:
> **Example:**
> `pip install llama-cpp-python==0.2.90 --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cpu`
>
> **Tip:** There are [pre-built wheel files for
> `chroma-hnswlib`](https://pypi.org/project/chroma-hnswlib/#files),
> as well. If running `pip install onprem` fails on building
> `chroma-hnswlib`, it may be because a pre-built wheel doesn’t yet
> exist for the version of Python you’re using (in which case you
> can try downgrading Python).
3. **I’m behind a corporate firewall and am receiving an SSL error when
trying to download the model?**
> Try this:
>
> ``` python
> from onprem import LLM
> LLM.download_model(url, ssl_verify=False)
> ```
> You can download the embedding model (used by `LLM.ingest` and
> `LLM.ask`) as follows:
>
> ``` sh
> wget --no-check-certificate https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/all-MiniLM-L6-v2.zip
> ```
> Supply the unzipped folder name as the `embedding_model_name`
> argument to `LLM`.
> If you’re getting SSL errors when even running `pip install`, try
> this:
>
> ``` sh
> pip install –-trusted-host pypi.org –-trusted-host files.pythonhosted.org pip_system_certs
> ```
4. **How do I use this on a machine with no internet access?**
> Use the `LLM.download_model` method to download the model files to
> `/onprem_data` and transfer them to the same
> location on the air-gapped machine.
> For the `ingest` and `ask` methods, you will need to also download
> and transfer the embedding model files:
>
> ``` python
> from sentence_transformers import SentenceTransformer
> model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
> model.save('/some/folder')
> ```
> Copy the `some/folder` folder to the air-gapped machine and supply
> the path to `LLM` via the `embedding_model_name` parameter.
5. **My model is not loading when I call `llm = LLM(...)`?**
> This can happen if the model file is corrupt (in which case you
> should delete from `/onprem_data` and
> re-download). It can also happen if the version of
> `llama-cpp-python` needs to be upgraded to the latest.
6. **I’m getting an `“Illegal instruction (core dumped)` error when
instantiating a `langchain.llms.Llamacpp` or `onprem.LLM` object?**
> Your CPU may not support instructions that `cmake` is using for
> one reason or another (e.g., [due to Hyper-V in VirtualBox
> settings](https://stackoverflow.com/questions/65780506/how-to-enable-avx-avx2-in-virtualbox-6-1-16-with-ubuntu-20-04-64bit)).
> You can try turning them off when building and installing
> `llama-cpp-python`:
> ``` sh
> # example
> CMAKE_ARGS="-DGGML_CUDA=ON -DGGML_AVX2=OFF -DGGML_AVX=OFF -DGGML_F16C=OFF -DGGML_FMA=OFF" FORCE_CMAKE=1 pip install --force-reinstall llama-cpp-python --no-cache-dir
> ```
7. **How can I speed up
[`LLM.ingest`](https://amaiya.github.io/onprem/llm.base.html#llm.ingest)?**
> By default, a GPU, if available, will be used to compute
> embeddings, so ensure PyTorch is installed with GPU support. You
> can explicitly control the device used for computing embeddings
> with the `embedding_model_kwargs` argument.
>
> ``` python
> from onprem import LLM
> llm = LLM(embedding_model_kwargs={'device':'cuda'})
> ```
> You can also supply `store_type="sparse"` to `LLM` to use a sparse
> vector store, which sacrifices a small amount of inference speed
> (`LLM.ask`) for significant speed ups during ingestion
> (`LLM.ingest`).
>
> ``` python
> from onprem import LLM
> llm = LLM(store_type="sparse")
> ```
>
> Note, however, that, unlike dense vector stores, sparse vector
> stores assume answer sources will contain at least one word in
> common with the question.