https://github.com/ameobea/sprout
AI-powered anime recommendation website for MyAnimeList + AniList with other tools, visualizations, and profile analytics
https://github.com/ameobea/sprout
anilist anilist-api myanimelist myanimelist-api recommender-system sveltekit tensorflowjs
Last synced: over 1 year ago
JSON representation
AI-powered anime recommendation website for MyAnimeList + AniList with other tools, visualizations, and profile analytics
- Host: GitHub
- URL: https://github.com/ameobea/sprout
- Owner: Ameobea
- Created: 2022-04-18T20:34:02.000Z (about 4 years ago)
- Default Branch: main
- Last Pushed: 2024-09-08T23:13:51.000Z (almost 2 years ago)
- Last Synced: 2025-03-16T10:11:10.746Z (over 1 year ago)
- Topics: anilist, anilist-api, myanimelist, myanimelist-api, recommender-system, sveltekit, tensorflowjs
- Language: Jupyter Notebook
- Homepage: https://anime.ameo.dev
- Size: 1.93 MB
- Stars: 56
- Watchers: 4
- Forks: 3
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Sprout
[](https://anime.ameo.dev)
Sprout is an anime recommendation website that uses a neural network to suggest animes to watch based on watch history and past ratings. It can pull public profiles directly from [MyAnimeList](https://myanimelist.net/) or [AniList](https://anilist.co/), and it also has an [interactive recommender](https://anime.ameo.dev/interactive-recommender) where you can provide your ratings directly on the site.
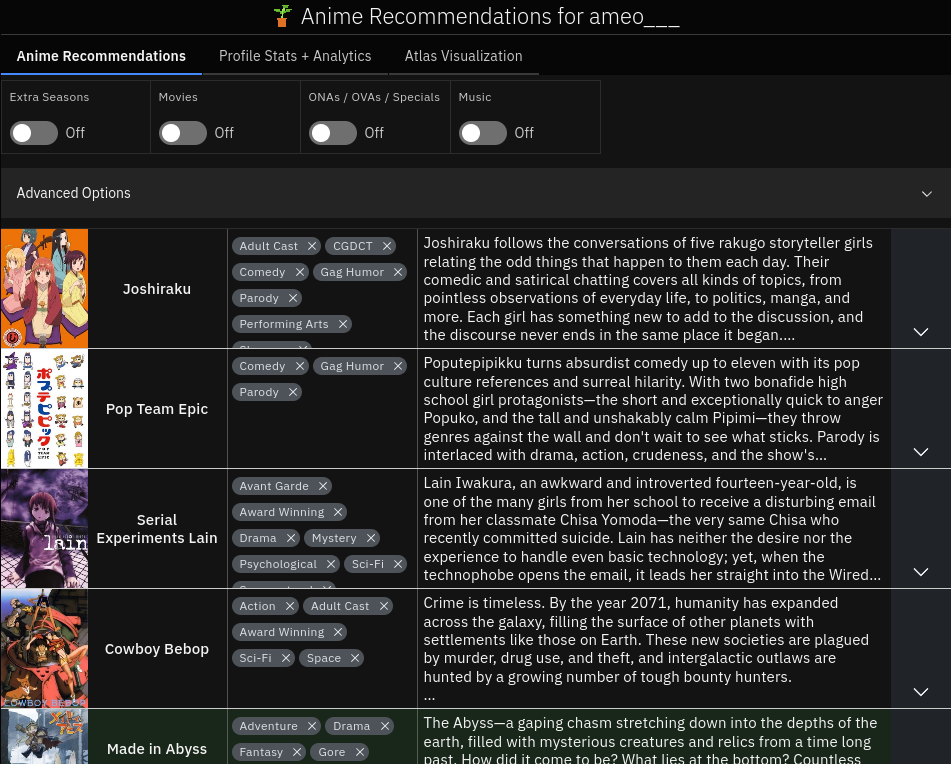
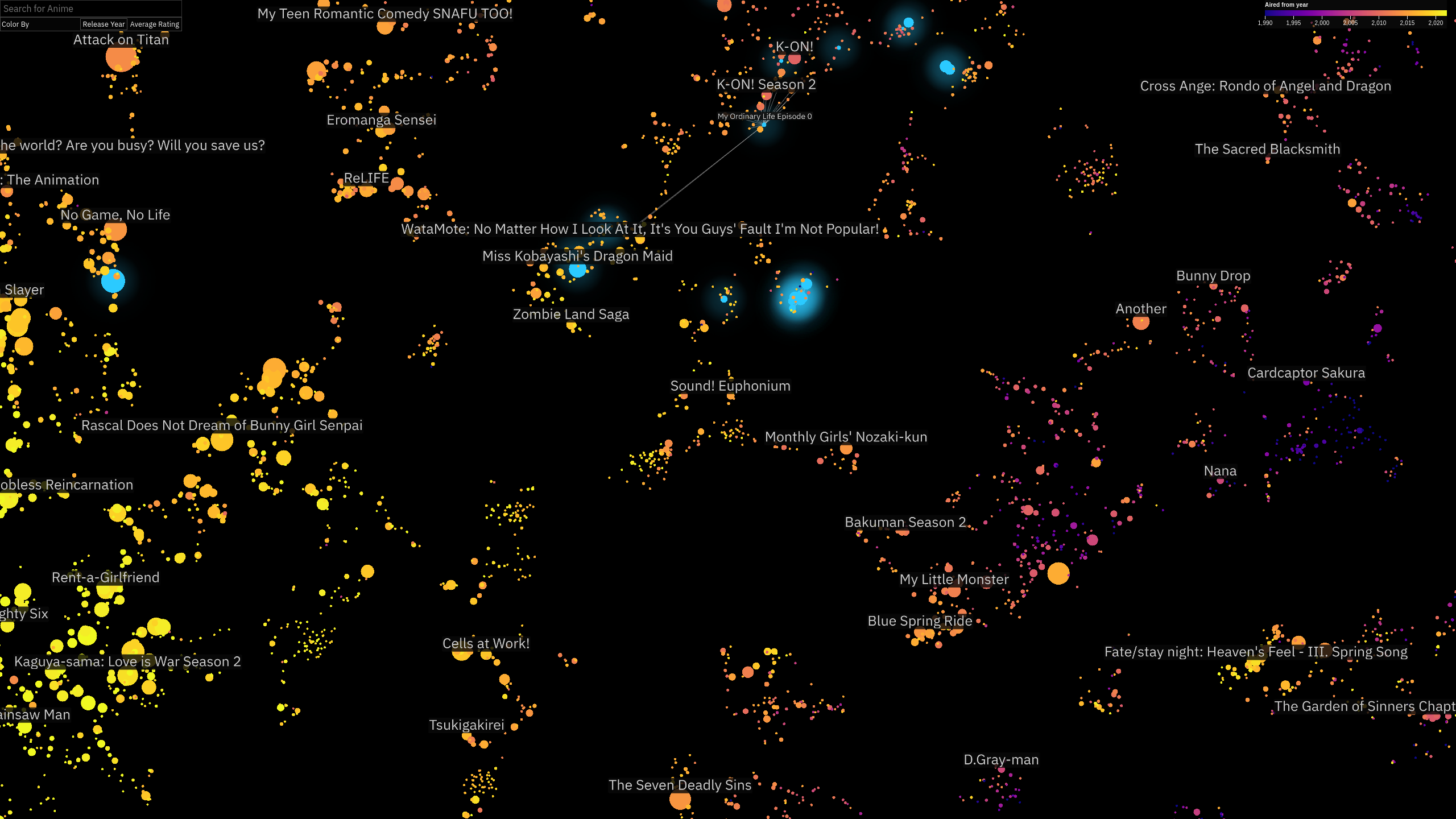
In addition to recommendations, it also has some profile analytics and an interactive visualzation of the whole world of anime, [Anime Atlas](https://anime.ameo.dev/pymde_4d_40n):
## Tech
The site is written in TypeScript and built with [SvelteKit](https://kit.svelte.dev/) using the Node.JS adapter.
### Recommendation Model
The recommendation model was trained completely in the browser using [Tensorflow.JS](https://www.tensorflow.org/js/). It is a rather large model of ~100M parameters but uses a very simple architecture. It was trained to learn associations between anime as well as other patterns in user profiles and anime preferences using data collected from a very large number of MyAnimeList profiles.
The design is similar to a [denoising autoencoder](https://paperswithcode.com/method/denoising-autoencoder). User profiles were provided as input with some percentage of ratings held out, and the model was trained to predict the full profile.
The model is served using Tensorflow.JS as well and runs on the CPU. To determine which ratings in a users' profile contribute most to individual recommendations, the model is re-run many times while holding out each rating to see which causes the recommendation's score to go down the most.
I've written a bit more about the model's design, architecture, and training process in this Reddit comment and thread:
### Atlas
The atlas was created by producing an embedding out of a weighted co-occurence graph of anime<->anime pairs based on their presences and ratings in users' profiles. If a user watched two anime and rated both highly, that edge in the graph gains more weight. The embedding is produced using [PyMDE](https://pymde.org/) and then projected down to 2D using t-SNE.
See the `notebooks` directory for experiments, research, and notebooks used for the embedding generation process.
The web portion of the atlas is built with [PixiJS](https://pixijs.com/), a WebGL-powered 2D graphics framework for interactive web apps.