https://github.com/amgix/amgix-server
Amalgam Index (Amgix) is a modular distributed hybrid search system
https://github.com/amgix/amgix-server
api backend distributed-systems hybrid-search information-retrieval keyword-search mariadb microservices postgresql qdrant ranking retrieval search search-engine self-hosted semantic-search vector-search
Last synced: about 1 month ago
JSON representation
Amalgam Index (Amgix) is a modular distributed hybrid search system
- Host: GitHub
- URL: https://github.com/amgix/amgix-server
- Owner: amgix
- License: agpl-3.0
- Created: 2026-03-08T13:56:13.000Z (4 months ago)
- Default Branch: main
- Last Pushed: 2026-06-14T13:50:19.000Z (about 1 month ago)
- Last Synced: 2026-06-14T15:26:26.010Z (about 1 month ago)
- Topics: api, backend, distributed-systems, hybrid-search, information-retrieval, keyword-search, mariadb, microservices, postgresql, qdrant, ranking, retrieval, search, search-engine, self-hosted, semantic-search, vector-search
- Language: Python
- Homepage: https://amgix.io
- Size: 705 KB
- Stars: 6
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Cla: CLA.md
Awesome Lists containing this project
README
# **Amgix** - Open-Source Hybrid Search System
> **Amgix** (pronounced `a-MAG-ix`) - short for Amalgam Index
> *amalgam: a mixture or blend of different elements*
**Amgix is an open-source system that handles ingestion, embedding, and hybrid retrieval behind one REST API.** You do not need to stitch together queues, a vector database, and ranking or fusion logic in your application.
## How It Works
**0. Run Amgix One:**
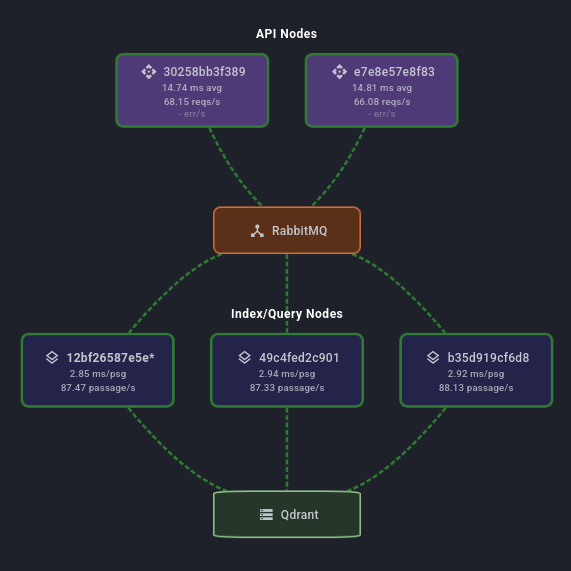
Amgix One packs the API, encoders, RabbitMQ, and Qdrant into one container — the easiest way to try Amgix or run it with modest requirements.
```bash
docker run -d -p 8234:8234 -v :/data amgixio/amgix-one:1
```
This persists data and caches Hugging Face models under `/data`.
Use the short tag `1` for the latest 1.x release, or a specific version from [Releases](https://github.com/amgix/amgix-server/releases) (e.g. `amgixio/amgix-one:v1.0.0`). For GPU support use `amgixio/amgix-one:1-gpu` (requires NVIDIA Container Toolkit).
**1. Define your collection:**
```json
POST /v1/collections/products
{
"vectors": [
{"name": "keyword", "type": "keyword", "index_fields": ["name", "content"]},
{"name": "semantic", "type": "dense_model", "model": "sentence-transformers/all-MiniLM-L6-v2", "index_fields": ["content"]}
]
}
```
**2. Upload your data:**
```json
POST /v1/collections/products/documents/bulk
{
"documents": [
{
"id": "part-001",
"timestamp": "2026-03-15T00:00:00Z",
"name": "Roller 12LP'-x03/5-XL",
"content": "Precision pinch roller assembly for manufacturing."
},
{
"id": "part-002",
"timestamp": "2026-03-15T00:00:00Z",
"name": "Bearing 12LP'-y03/5-XL",
"content": "Deep groove ball bearing, double shielded."
},
{
"id": "part-003",
"timestamp": "2026-03-15T00:00:00Z",
"name": "Belt 12LP'-x03/8-MD",
"content": "Synchronous timing belt for power transmission."
}
]
}
```
**3. Search:**
```json
POST /v1/collections/products/search
{
"query": "12lpy03"
}
```
*Amgix's built-in keyword tokenizer handles missing punctuation to correctly return the Bearing (`12LP'-y03/5-XL`).*
```json
POST /v1/collections/products/search
{
"query": "motor energy transfer loop"
}
```
*Even without keyword overlap, Amgix's semantic vector understands the concept and returns the Belt (`Synchronous timing belt for power transmission`).*
---
## Why Amgix
Because integrating modern search into applications is hard. You usually have to:
1. Stitch together multiple systems for retrieval, embeddings, and indexing.
2. Build indexing and re-indexing pipelines that handle deduplication and failures.
3. Build and maintain embedding pipelines for semantic search.
4. Combine keyword and semantic results into one ranking.
5. Tune relevance for real queries, filters, typos, and identifier-heavy data.
6. Keep the whole thing in sync, reliable, and scalable.
Amgix was built to solve these headaches. Instead of stitching together your own infrastructure, you get a single unified stack with:
- **Built-in ingestion queues:** Async processing with automatic retries and deduplication.
- **Adaptive model orchestration:** Models load and rebalance across nodes automatically based on demand.
- **Server-side fusion:** One API call handles query vectorization, semantic search, keyword search (including our custom tokenizer for messy identifier data), and ranking.
- **Backend Agnostic:** Run on Postgres, MariaDB, or Qdrant without changing your code.
---
Visit [Documentation](https://docs.amgix.io/)
Clients: [Python](https://github.com/amgix/amgix-client-python/), [Typescript](https://github.com/amgix/amgix-client-typescript/)
Site: [amgix.io](https://amgix.io/)