https://github.com/analysys/presto-hbase-connector
presto hbase connector 组件基于Presto Connector接口规范实现,用来给Presto增加查询HBase的功能。相比其他开源版本的HBase Connector,我们的性能要快10到100倍以上。
https://github.com/analysys/presto-hbase-connector
Last synced: 6 months ago
JSON representation
presto hbase connector 组件基于Presto Connector接口规范实现,用来给Presto增加查询HBase的功能。相比其他开源版本的HBase Connector,我们的性能要快10到100倍以上。
- Host: GitHub
- URL: https://github.com/analysys/presto-hbase-connector
- Owner: analysys
- License: apache-2.0
- Created: 2019-03-08T02:03:09.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2023-01-02T21:54:46.000Z (over 3 years ago)
- Last Synced: 2024-11-22T02:35:10.308Z (over 1 year ago)
- Language: Java
- Homepage:
- Size: 277 KB
- Stars: 240
- Watchers: 20
- Forks: 100
- Open Issues: 25
-
Metadata Files:
- Readme: README-ch.md
- License: LICENSE
Awesome Lists containing this project
- awesome-java - Presto HBase Connector
- awesome-hbase - Presto - Presto-HBase connector. (Projects / Integrations)
README
# 易观presto-hbase-connector组件
组件基于Presto Connector接口规范实现,用来给Presto增加查询HBase的功能。
相比其他开源版本的HBase Connector,我们的性能要快10到100倍以上。
## 性能对比
| 环境 | 明细 |
| ------ | --------------------------------------------------------- |
| 数据量 | 事件表500万条数据,90个字段 |
| 节点数 | 3 |
| 硬件 | 16逻辑核 64G内存(其中Presto和HBase各占16G内存) 4T*2硬盘 |
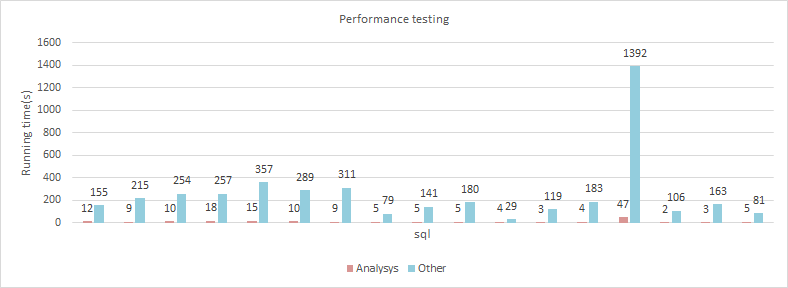
详细测试结果参见:https://github.com/analysys/public-docs/blob/master/Attachment5(Presto-HBase-Connector-PerformanceTesting).xlsx
## 功能点对比
| 功能点 | 易观 | 其他 |
| ------------------- | -------- | ------ |
| 加盐查询 | 支持 | 不支持 |
| 拼接StartKey/EndKey | 支持 | 不支持 |
| 批量Get查询 | 支持 | 不支持 |
| 谓词下推(Filter) | 支持 | 不支持 |
| ClientSideScan | 支持 | 支持 |
| Insert | 支持 | 支持 |
| Delete | 支持 | 支持 |
| 建表语句 | 后续支持 | 支持 |
## 使用条件
1. Mac OS X 或者 Linux
2. Java 8 Update 161 或更高 (8u161+), 64-bit.
3. Maven 3.3.9+ (编译)
4. PrestoSql 315+
## 构建组件
mvn clean package
## 组件安装
##### 1.配置hbase.properties
在{Presto_Config_Dir}/catalog目录下创建hbase.properties文件。配置完成后同步到所有worker节点。
以下是一个比较简单的配置样例,供大家参考:
```
connector.name=hbase
zookeeper-quorum=localhost:2181
zookeeper-client-port=2181
zookeeper-znode-parent=/hbase
hbase-cluster-distributed=true
presto-server-port=8285
random-schedule-redundant-split=false
meta-dir=/etc/presto/chbase
```
参数说明如下:
* connector.name
该配置固定设置为hbase。
* zookeeper-quorum
相当于HBase API的hbase.zookeeper.quorum参数。
* zookeeper-client-port
相当于HBase API的hbase.zookeeper.property.clientPort参数。
* hbase-cluster-distributed
相当于HBase API的hbase.cluster.distributed参数。
* presto-workers-name
presto worker的hostname,以英文逗号间隔。
如果split-remotely-accessible配置为false,则该参数可以不设置。
* presto-server-port
与{Presto_Config_Dir}/config.properties配置文件的http-server.http.port参数。
* random-schedule-redundant-split
Presto默认采用按可用Worker的顺序,依次分配Split的方式调度Split。
这样容易导致多表查询时,第余数个Split集中调度到可用Worker列表开头的几台机器上。
将这个参数设置为true可以改为将第余数个Split随机调度到一个Worker上执行。
* meta-dir
存放HBase表元数据信息的目录。
* zookeeper-znode-parent
等同于hbase-site.xml的zookeeper.znode.parent参数。
* enable-clientSide-scan
是否启用HBase的ClientSide查询模式。默认为不启用,false。
* clientside-querymode-tablenames
使用ClientSide模式进行查询的表名,多表用英文逗号间隔。
##### 2.配置namespace
完成hbase.properties的配置之后,需要在{meta-dir}目录创建HBase的namespace目录结构
- {meta-dir}目录用来存放表的元数据信息。
- 该目录下,首先按照hbase的namespace名创建目录。
- 每一张表会有一个单独的json文件来保存它的表结构信息,json文件以{表名}.json来命名。
- 不同namespace的表分别存放在各自的namespace目录下。
目录结构的样例如下:
```
--meta-dir:
--namespace_a:
table_a1.json
table_a2.json
--namespace_b:
table_b1.json
table_b2.json
--default:
table_c.json
```
这个例子中分别定义了namespace_a:table_a1、namespace_a:table_a2、namespace_b:table_b1、namespace_b:table_b2以及default命名空间下的 table_c这5张表。
##### 3.配置表结构json
namespace目录创建完成之后,我们需要配置表结构json文件,下面讲解一下json文件中的属性:
表json:
| 属性名 | 描述 |
| -------------------- | ------------------------------------------------------------ |
| tableName | 表名 |
| schemaName | Namespace |
| rowKeyFormat | RowKey是由哪些字段组成,用英文逗号分隔。字段组成有序。 |
| rowKeySeparator | 组成RowKey的字段之间的分隔符,默认是\001 |
| rowKeyFirstCharRange | 如果RowKey是散列的,可以指定RowKey首字母的取值范围,这样可以以多个split并发的方式大幅提升性能。首字母的取值范围可以是a\~z,A\~Z,0\~9,相互之间用英文逗号间隔,例如:a\~b,D\~K,3\~5,或者3\~5,c\~f等等 |
| describe | 表格描述 |
| columns | 字段列表 |
columns json:
| 属性名 | 描述 |
| ---------- | ------------------------------------------------------------ |
| family | 列族名 |
| columnName | 字段名 |
| isRowKey | 是否行键 |
| type | 字段类型(大小写不敏感): string、int、bigint、double、boolean(用int存储,0代表false,1代表false)、array< string > |
| comment | 字段备注 |
说明:isRowKey为true,表示我们把表的行键抽象成为了一个具体的字段。无论是查询、写入还是其他各种复杂操作,他在表面上与一个普通的字段没有任何区别,只不过在底层他作为表的行键有着其特殊的含义。
RowKey字段的类型必须为varchar。
以下是一个简单的json文件示例:
```
{
"tableName": "t_event_test",
"schemaName": "db_test",
"rowKeyFormat": "xwhat,xwho",
"describe": "Table for test!",
"rowKeySeparator": "-",
"rowKeyFirstCharRange": "a~z,0~9",
"columns": [{
"family": "",
"columnName": "rowkey",
"comment": "The RowKey column of table!",
"type": "varchar",
"isRowKey": true
}, {
"family": "f",
"columnName": "xwho",
"comment": "Column for test!",
"type": "varchar",
"isRowKey": false
}, {
"family": "f",
"columnName": "ds",
"comment": "Column for test!",
"type": "varchar",
"isRowKey": false
}]
}
```
根据表的namespace找到它在{meta-dir}中对应的目录,按照上述说明创建以表名命名的json文件。
##### 4.编译组件jar包
完成上述步骤之后,接下来需要编译组件jar包
```
// 下载组件源码
// 使用maven构建组件的jar包
mvn clean package
```
##### 5.部署组件jar包
在{plugin.dir}目录下创建插件目录hbase(目录名称可任意设置)。
将构建好的presto0.20-hbase-{version.num}.jar拷贝到该目录下,并同步到所有的worker节点上。
##### 6.重启presto集群
## Insert操作
在dev_0.1.1版本支持了写入操作。写入操作需要用户以字段拼接或者固定值的方式,指定数据的row_key。如下:
```sql
insert into hbase.db_test.test_event(row_key, xwho, distinct_id, ds, xwhen, xwhat, attri_1) select '01-test_rowkey' as row_key, xwho, distinct_id, ds, xwhen, xwhat, attri_1 from hbase.db_test.test_event_v2 where xwhen=1562057346821;
insert into hbase.db_test.test_event(row_key, xwho, distinct_id, ds, xwhen, xwhat, attri_1) select concat('01-', xwho, '-', xwhat, '-', xwhen) as row_key, xwho, distinct_id, ds, xwhen, xwhat, attri_1 from hbase.db_test.test_event_v2 where xwhat='login';
```
## Delete操作
在meta_0.1.1版本支持了删除操作。删除操作不需要用户在sql中指明数据的row_key的值,但是要求所操作的表在定义其元数据的json文件中,必须设置了row_key字段。connector在筛选出所要删除的数据时,会获取到数据的row_key,然后根据row_key的值删除指定的数据。sql示例如下:
```sql
delete from hbase.db_test.test_event where xwhen >= 1562139516028;
```
## 查询优化
##### 1.使用盐值
盐值就是指给每个RowKey增加一组可逆向还原的随机数字作为前缀。这样可以将数据分散到多个region存储,查询时也可以通过多线程并发查找。在presto中就可以利用这个机制将数据切分成多个split并发查找。经过验证,使用盐值可以使性能提升几十倍以上。
在组件中使用盐值需要在json文件中设置以下两个属性:
- seperateSaltPart
```
RowKey是否使用了单独的盐值作为前缀。如果RowKey以单独的盐值部分加上{rowKeySeparator}开头,则配置为true。从0.1.5版本开始盐值只能由一位取值范围在a~z,A~Z,0~9的字符组成。
```
* rowKeyFirstCharRange
当RowKey的首个字符是按照MD5或者其他算法散列时,可以通过这个属性说明首个字符的取值范围。connector会根据他的取值范围生成多个split并发执行。首字母的取值范围暂时只支持a~z,A~Z,0~9,相互之间用英文逗号间隔,例如:
a~b,D~K,3~5
3~5,c~f
A~Z,p~u
当该属性配置为a~b,D~F,6~8时,会依次生成8对startKey和endKey。
每一对startKey和endKey会交给一个split去做数据扫描。如下:
(a,a|)
(b,b|)
(D,D|)
(E,E|)
(F,F|)
(6,6|)
(7,7|)
(8,8|)
有时如果拆出的split过多,会自动进行范围的合并,以避免split过多性能反而下降,例如:
(a,b|)
(D,F|)
(6,8|)
* rowKeySeparator
组成RowKey的字段之间的分隔符,默认是\001
##### 2.根据RowKey的组成拼接StartKey和EndKey
这是指根据RowKey是由哪些字段组成的,以及当前查询的谓词来拼接查询StartKey和EndKey。
例如,当RowKey的构成如下:
```
xwhat-xwho
```
而SQL是:
```
select xwhat, xwho, date, xwhen from t_event_test where xwhat='login' and xwho in ('drew', 'george');
```
这样就会生成如下两对StartKey和EndKey:
```
(login-drew, login-drew|)
(login-george, login-george|)
```
要实现这样的查询优化机制,我们需要配置以下两个参数:
* rowKeyFormat
定义RowKey是由哪些字段有序组成。以刚才的例子来说,这里应该配置为"xwhat,xwho"
* rowKeySeparator
RowKey的不同组成部分之间的分隔符,默认是\001。以刚才的例子来说,这里应该配置为"-"
如果想查看sql具体切分出了哪些split,可以将日志级别设置为info,在server.log中查看。
##### 3.批量get
批量get就是HBase的API中将所要查询的多个RowKey封装成一个List< Get >,然后请求这个列表以获取数据的查询方式。
这种查询方式使用起来非常便利,可以直接将要查询的RowKey作为等值匹配的查询条件放到SQL中即可。
```
select * from t_event_test where rk in ('rk1', 'rk2', 'rk3');
```
当系统解析谓词时,会根据字段名是否与RowKey字段一致判断是否执行这一查询模式。
使用这个查询模式,要求必须在表的json文件中通过isRowKey指定RowKey字段。
注意:因为我们定义的RowKey字段是虚拟字段,所以对它做除等值查询之外的其他类型的查询都是没有逻辑意义的。
##### 4.ClientSideRegionScanner
ClientSideRegionScanner是HBase在0.96版本新增的Scanner,他可以在Client端直接扫描HDFS上的数据文件,不需要发送请求给RegionServer,再由RegionServer扫描HDFS上的文件。
这样减少了RegionServer的负担,并且即使RegionServer处于不可用状态也不影响查询。同时,因为是直接读取HDFS,所以在负载较为均衡的集群中,可以基本实现本地读策略,避免了很多网络负载。
下图是本组件使用ClientSideRegionScanner与普通RegionScanner的性能对比,通过比较可以得出,大部分查询都有了30%以上的提升,尤其是接近全表扫描的查询性能提升更为明显:
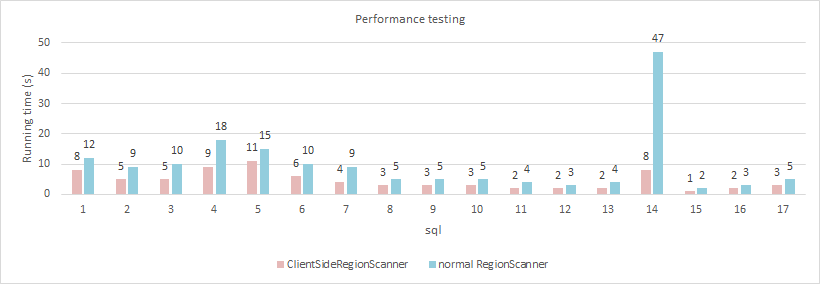
详细测试结果参见:https://github.com/analysys/public-docs/blob/master/Attachment6(Presto-HBase-Connector-PerformanceTesting-ClientSide).xlsx
使用ClientSide查询需要设置以下三个参数:
* hbase-rootdir
这个参数与hbase-site.xml的hbase.rootdir保持一致即可。
* enable-clientSide-scan
是否开启ClientSide查询模式。
* clientside-querymode-tablenames
定义哪些表需要使用ClientSide查询,表名之间用英文','间隔,例如:
```
namespace_a:table_a,namespace_a:table_b,namespace_b:table_c
```
如果所有表都要使用ClientSide查询,可以配置成*。
除以上三个参数之外,打包时还需要将运行环境中hadoop的core-site.xml和hdfs-site.xml两个配置文件拷贝到project的src/main/resources目录下
需要注意的是,ClientSideRegionScanner的查询是依赖Snapshot的,所以为了查询能获取到最新的数据,每次查询时都会自动创建一个命名规则如下的Snapshot:
```
"ss-" + schemaName + "." + tableName + "-" + System.nanoTime()
```
HBase最大可支持的Snapshot数为65536个,所以在使用ClientSideRegionScanner时最好能够做到定时清理过期Snapshot。
## 问题解决
##### 1.如何让ClientSideRegionScanner可以查询Snappy压缩格式的HBase表?
你需要解决以下几个问题:
###### 1) SnappyCodec找不到的问题
这是因为在Presto的classPath中缺少hadoop-common-2.7.3.jar这个jar包。因为我们是基于ambari搭建的presto,所以需要将这个jar包拷贝到/usr/lib/presto/lib目录下。
###### 2) SnappyCodec无法转换为CompressionCodec的问题
经过定位发现Presto加载插件的类是采用自定义的PluginClassLoader,而SnappyCodec是采用AppClassLoader加载的。二者classLoader不同导致父类和子类不具备父子继承关系。
修改hbase-common-1.1.2.jar中代码,将SnappyCodec改为使用PluginClassLoader的方式加载解决了这个问题。需要修改的代码为hbase-common模块的org.apache.hadoop.hbase.io.compress.Compression类,修改方法如下:
```
/**
* Returns the classloader to load the Codec class from.
*/
private static ClassLoader getClassLoaderForCodec() {
/*修改前:
ClassLoader cl = Thread.currentThread().getContextClassLoader();
if (cl == null) {
cl = Compression.class.getClassLoader();
}*/
// 修改后:
ClassLoader cl = Compression.class.getClassLoader();
if (cl == null) {
cl = Thread.currentThread().getContextClassLoader();
}
if (cl == null) {
cl = ClassLoader.getSystemClassLoader();
}
if (cl == null) {
throw new RuntimeException("A ClassLoader to load the Codec could not be determined");
}
```
用修改后的代码重新install maven仓库,再重新打组件jar包即可。
###### 3) java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCodeLoader.buildSupportsSnappy()Z
这是需要在jvm中增加hadoop的native snappy库。可以在presto的jvm.config中,增加如下配置:
```
-Djava.library.path={path to hadoop native lib}
```
###### 4) java.io.IOException: java.lang.NoSuchMethodError: com.google.common.base.Objects.toStringHelper(Ljava/lang/Object;)Lcom/google/common/base/Objects$ToStringHelper;
这是因为guava在v20.0以上的版本去掉了com.google.common.base.Objects中实现的内部类ToStringHelper,以及几个toStringHelper的方法。
可以从低版本中将这些删除的代码增加到高版本的guava源码中,重新编译更新maven库中的guava-24.1-jre.jar之后,再重新构建presto-hbase.jar包。
并将guava-24.1-jre.jar上传到PrestoWorker的lib目录中。
或者使用maven的shade插件来解决这类jar包冲突的问题。
###### 5) Stopwatch的构造函数找不到
将guava的com.google.common.base.Stopwatch类中的构造函数改为public即可。
或者使用shade来解决这类jar包冲突的问题。
###### 6)Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=presto, access=WRITE, inode="/apps/hbase/data/data/db_moredatatest/multifamily_90cq_7cf_500w_snappy2/dee9b34c5cd8ee34f74ff5fc5446432a/.tmp":hbase:hdfs:drwxr-xr-x
权限不足,因为hbase对自身的数据文件权限都是hbase用户之下,而我们通过presto查询使用的是presto用户,需要给presto用户授予读取权限。
##### 2.如何在Idea中debug开发ClientSideRegionScanner查询以Snappy格式进行压缩的HBase表?
你需要解决以下几个问题:
###### 1) 找不到类CanUnbuff
在presto-hbase-connector模块中增加如下dependency:
```
com.facebook.presto.hadoop
hadoop-apache2
2.7.4-1
```
###### 2) 使用hbase-shaded-client和hbase-shaded-server依赖
###### 3) 参考“SnappyCodec无法转换为CompressionCodec的问题”部分,修改hbase-common模块的代码,并重新编译更新maven库。其中hbase-shade-client、hbase-shade-server和hbase-common这三个模块必须重新编译。
###### 4) 在idea的run->Edit Configuration中配置-Djava.library.path到PrestoServer的VM options中。java.library.path就是hadoop的native snappy库路径。
## 更新说明
##### 1. meta-0.1.1
- 支持ClientSide查询功能。
##### 2. meta-0.1.2
- 实现写入和删除的功能。
- 解决使用ClientSide方式查询default命名空间下的表报错表名不一致的问题。
- 将参数enable-clientSide-scan默认设置为false。将参数hbase-rootdir的值设置为可空。
- 增加参数zookeeper-znode-parent。
##### 3. meta-0.1.3
- 将connector迁移到PrestoSql-315版本。
- 提供一个基于PrestoDb-0.221实现的可用版本,分支名为dev_prestodb-0.221_0.1.2。
- 修改doc文档。
##### 4. meta-0.1.4
- 迁移connector api到non-legacy的新版本
##### 5. meta-0.1.5
- 重新调整切分split的逻辑,去掉参数rowKeySaltUpperAndLower,改为rowKeyFirstCharRange。使得即使RowKey没有盐值部分,且没有可用来拼接StartKey的谓词时,只要RowKey首字符是散列的,仍然可以切分出多个split以增加查询并行度。