https://github.com/andrewwint/baton
Manager-led orchestration for Claude Code. Routes development through bounded, parallel lanes with approval gates, an auditable trail, and independent verification that catches defects green tests miss. Built for consistency, not to make the model smarter. Optional Agent SDK runtime.
https://github.com/andrewwint/baton
agent-orchestration ai-agents claude claude-agent-sdk claude-code code-review developer-tools subagents typescript
Last synced: about 24 hours ago
JSON representation
Manager-led orchestration for Claude Code. Routes development through bounded, parallel lanes with approval gates, an auditable trail, and independent verification that catches defects green tests miss. Built for consistency, not to make the model smarter. Optional Agent SDK runtime.
- Host: GitHub
- URL: https://github.com/andrewwint/baton
- Owner: andrewwint
- License: mit
- Created: 2026-06-16T11:03:06.000Z (13 days ago)
- Default Branch: main
- Last Pushed: 2026-06-23T20:24:22.000Z (5 days ago)
- Last Synced: 2026-06-23T22:19:26.741Z (5 days ago)
- Topics: agent-orchestration, ai-agents, claude, claude-agent-sdk, claude-code, code-review, developer-tools, subagents, typescript
- Language: JavaScript
- Size: 831 KB
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Agents: AGENTS.md
Awesome Lists containing this project
README
# Baton
_Consistently disciplined: it hunts blind spots in code and tests on the high-risk work that warrants it. The trade-off is more tokens and time, not a smarter model._
Baton is a lean, manager-led orchestration skill for **Claude Code**, with an optional TypeScript runtime on the [Claude Agent SDK](https://code.claude.com/docs/en/agent-sdk/overview). A single coordinator routes development work through bounded subagent lanes (triage, discovery, planning, implementation, verification, recovery), owning integration, approval gates, and an auditable run trail. The point is consistency and independent verification that catches what green tests miss, not a smarter model. **Lean by default** for solo work; encode your team's review, deploy, and acceptance steps in `references/` once, and Baton repeats them across every project.
## Executive summary
**Baton** is a skill for Claude Code (an AI that writes code), following the open [Agent Skills](https://agentskills.io/home) standard.
Think of a relay race. The work is the baton, passed cleanly from one runner to the next:
- one **looks around the code** to learn how it works
- one **makes a plan**
- one **writes the code**
- one **checks the work** and looks for mistakes the tests miss
- one **looks things up** when the team gets stuck
A **coordinator** hands the baton to each runner, keeps them out of each other's way, and brings the work back together. It asks you first before anything big or hard to undo, like sharing code or deleting files. You stay in charge, and it keeps short notes on what it did.
You can teach Baton your own rules (your review steps, deploy checks, ticket conventions) by adding a few files, so the same process repeats on every project. Simple for one person, and it still fits a big team.
Baton uses more of the AI's effort than a single prompt, because it runs several helpers per job. In return you get a steady, checked process on every run, and you do not have to keep track of every handoff yourself.
## Auditable by default
Every substantial run leaves a structured trail you can read after the fact: the default, not a setting you switch on. The runtime writes a `RunRecord` (run id, task, the lanes that ran and their outcomes, verification evidence, approval decisions, model and cost) plus a `summary.md` under `.agents/runs//` on every completed run; the interactive manager keeps the same proportional trail by the skill's run-artifacts discipline. It is local working state, never committed product source. For consequential or regulated work, _what was planned, changed, verified, and approved, and by which lane_ is the point as much as the result. Override the location with `BATON_LEDGER_DIR`, or turn persistence off with `=off`.
Together, the trail, the approval gates, and a local-only / data-residency posture ([`docs/MCP.md`](docs/MCP.md#for-regulated--local-only-environments)) are the evidence a regulated reviewer asks for: surfaced by design, not asserted as a certification Baton doesn't hold.
## Shift-left by design
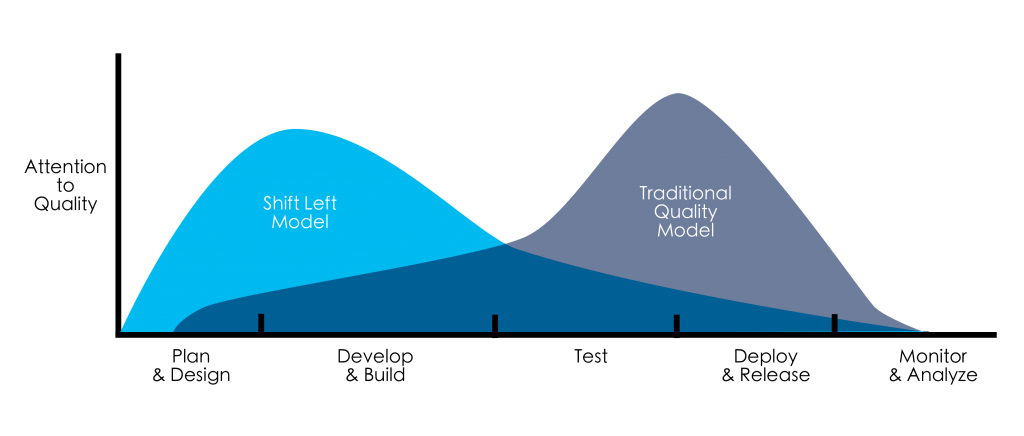
Baton's loop is shaped like the shift-left curve: it concentrates attention on quality **early**, with discovery before touching code, a planning pass, reading the surrounding code to match its conventions, and verification before work is called done. The economics are the classic ones: a defect caught at _Plan_ or _Develop_ is far cheaper than the same defect caught at _Test_, _Deploy_, or in production.
That early investment is a **cost**. It is only worth it when there's an expensive "late" to prevent, which is why it fits consequential work. The point isn't _more turns up front_; it's **earlier attention, in proportion to risk**. The edge over a bare model isn't that Baton can plan ahead (any capable model can); it's that Baton shifts left **reliably, on every routed run**, instead of only when the task and model happen to prompt it.
Scope note: out of the box Baton is shift-**left**. It owns **Plan → Develop → Test** and _gates_ (rather than runs) anything outward-facing. The right side isn't a hard wall, though. Encode your **Deploy & Release** process in [`references/`](.claude/skills/baton/references/), along with point-in-time **Monitor & Analyze** checks (post-deploy health, smoke tests, acceptance), and Baton will sequence, gate, and verify those steps as part of the loop. What stays out is _execution_, not coverage: Baton still won't fire an irreversible deploy without your approval or act as a live production monitor. It drives the process you define and leaves the trigger to you or your pipeline.
## When Baton helps (measured)
A Baton-vs-baseline bench (`testing/fixtures/`, skill-on vs. `--no-skill`) ran four times across model tiers and difficulty, and **every run washed**: structured and unstructured tied, at higher cost for Baton. Baton does **not** make the model smarter. The observed split:

- **Basic tasks (small, self-contained coding fixtures: implement a function to pass a failing test, fix a localized bug, add a feature without breaking a sibling):** no better than plain AI, and Baton costs more (it runs extra helper lanes). If a change is cheap to get wrong, run it direct.
- **End-to-end development (a CQRS service, an OIDC login service, a Strands/AgentCore agent, and a NestJS security remediation):** where Baton earns its keep. A separate review pass and real-world testing caught bugs the unit tests had passed, including a critical forgeable-login defect on the OIDC service that all 110 of its tests passed over, and an OS command-injection RCE on the NestJS service that a 437-alert dependency scan never flagged.
- **The space between:** not benchmarked, an area for future investigation.
The gain comes from the extra checking, not the size of the work (a bigger but self-contained test still washed). What Baton adds is **reliability**: it always verifies, gates outward-facing actions, splits review into its own lane, and keeps an auditable run trail, where a bare model does these only when the task and model happen to favour it. Whether that beats a careful engineer plus one sharp review on cost is still untested. Full reasoning in [`docs/research-basis.md`](docs/research-basis.md#where-we-drifted--and-whats-still-open); the field runs in [`docs/field-notes.md`](docs/field-notes.md).
## What it's good for
Baton earns its cost on consequential, multi-step work. The shapes that show up in real runs:
- **Security remediation.** Point Baton at a security backlog (e.g. findings from a Snyk MCP server) and it triages by severity, routes each fix through a gated lane, and verifies the patch didn't break a sibling. Baton's orchestrator pattern grew out of exactly this finding-to-fix work. In one run, tracing reachability this way surfaced an OS command-injection RCE that a 437-alert dependency scan and the test suite both missed ([field notes](docs/field-notes.md)).
- **Auth and login services.** Build or change an OIDC login flow (e.g. Okta), a known-hard and security-critical integration, with an independent, adversarial review of the paths that invite a forged login. On one such service, a cold review caught a forgeable-login defect that all 110 of its tests had passed. ([field notes](docs/field-notes.md))
- **Cloud API services (CQRS, IaC).** Stand up a CQRS service and its AWS/CDK infrastructure spec-first, verified before anything is called done. ([field notes](docs/field-notes.md))
- **End-to-end AI agents.** Deliver a Strands / Bedrock AgentCore agent from spec to deployable, with a compliance-ready data model (jurisdiction, consent, suppression) from day one, the regulated shape Baton is built for. ([field notes](docs/field-notes.md))
## Built on LLM-as-Judge, hardened
Baton's verification _is_ the **LLM-as-Judge** pattern, with its known failure modes engineered against, and wrapped in a gated loop instead of left as a passive grader at the end:
- **Execution-grounded, not text-scoring.** The verify lane runs the build, tests, and lint, and writes its own adversarial checks; the verdict rests on observed behavior, not the model's read of the diff.
- **Independent by brief.** A judge handed the author's framing inherits the author's blind spots, so on high-stakes surfaces at least one reviewer is briefed _cold_: only the spec and the diff, none of the author's hypotheses. The estimate is out-of-sample, not a rubber stamp.
- **Adversarial, not a score.** The reviewer's job is to _break_ the change (find the fail-open, the bypass, the race), not rate it 1–5.
- **Human-anchored.** The spec and acceptance criteria are the ground truth; the reviewer is an instrument to surface defects you confirm, never the source of truth. Model grading model with no external anchor is the circularity Baton avoids.
- **A gate, not a dashboard.** A finding routes to recovery (bounded to ~2 attempts) or escalates to you; it controls whether the work moves forward.
Honest limits: it is still LLM judgment, and the cold read _reduces_ shared blind spots, it doesn't remove them, and it can miss or invent a defect. This is why Baton _washes on small tasks_ (a lone judge is plenty there) and only earns its cost where the work is consequential enough that an independent, executed check pays for itself.
## Where it's not worth it
A good tool should tell you when to skip it. Baton does extra work: it runs several helpers and checks each step, so it takes more time and costs more. That is worth it on big or risky jobs. It is not worth it here:
- **Small, low-risk jobs.** A typo, a one-line fix, a throwaway script. Just ask the AI directly. It is faster and cheaper, and Baton sends small jobs straight through on its own anyway.
- **No plan written down.** Baton only helps when you give it a clear plan and clear rules. Skip that and you get the extra steps but not the payoff. **Better pattern: plan first, then let Baton build and check against the plan.** For a durable, in-repo spec, use a planning tool like [Spec Kit](https://github.com/github/spec-kit), [BMAD-METHOD](https://github.com/bmad-code-org/BMAD-METHOD), or [OpenSpec](https://github.com/Fission-AI/OpenSpec) (recommended, since it is what Baton itself uses). For a lighter, zero-install option, Claude Code's built-in plan mode (in the terminal via `/plan` or Shift+Tab, and in the IDE extension's mode selector) drafts a plan you approve before the build; it saves the plan under `~/.claude/plans/` rather than in the repo.
**Simple rule: match the tool to the risk.** Low risk, ask the AI directly. High risk or many steps, plan it first, then run Baton to build, check, and keep a record. Either way, Baton makes the work careful and consistent. It does not make the code smarter.
## How the loop works
Substantial work runs the loop; trivial work skips it and runs direct.
```
intake → triage ─┬─ direct ───→ make the change · verify · done
│
└─ delegated → plan → implement → verify ─┬─ pass → approve → close out
(lanes) │
└─ fail → recover ───┐
≈2 focused tries │
on the failing │
surface, then ◀───┘
escalate to you
```
Lanes are bounded runners with **disjoint write scopes** that report back to the one coordinator, never to each other:
`discovery·Explore` · `planning·Plan` · `implementation·implementer` · `review·code-reviewer` · `research·researcher`
The coordinator owns integration, approval, and the run trail. The `recover` bound (~2 focused attempts, then escalate) is evidence-informed; see [Why it's built this way](#why-its-built-this-way).
Under the hood this runs on Claude Code's native subagent system; Baton is the playbook for it, not a separate engine. Claude Code spawns and runs the lanes; Baton decides when to spawn which, and gates the result.
| Claude Code provides | Baton adds |
| --------------------------------------------------------- | ---------------------------------------------------------------- |
| The Agent tool (spawns subagents) | When to spawn, and which lane |
| Built-in `Explore` / `Plan` lanes | The loop (intake → triage → plan → implement → verify → recover) |
| Custom agent definitions, a model per agent | The lane taxonomy and disjoint write scopes |
| `run_in_background`, worktree isolation, plan mode, hooks | Approval gates, the adversarial verify discipline, the run trail |
## Examples (simple → complex)
Invoke it in Claude Code with `/baton `:
```text
# trivial: runs direct, no lanes, no ceremony
/baton fix the typo in the README
# one delegated lane: implement, with review split out
/baton plan and implement this feature, splitting verification into its own lane
# discovery-first: reduce guessing before touching code
/baton do a discovery pass on this repo before we touch the auth flow
# read-only gate: review without letting it change code
/baton have a reviewer check this diff and run the tests; it must not edit anything
# fully routed: design, parallel implementation, review at the end
/baton route this change: design in one lane, implementation in another, review at the end
```
## Recommended workflow
For consequential work, the practice that holds up in real use is:
1. **Plan the feature and the implementation together.** Decide what the feature does and how it will be built in one planning pass: module boundaries, the conventions and contracts it must match, and a sliced work plan. Planning the build alongside the feature is what lets discovery surface the unstated rules (error types, naming, idempotency) before any code is written.
2. **Implement against that plan**, matching the surrounding code.
3. **Review with an independent, focused pass.** A single review on clean inputs misses what a differently-briefed one catches. The strongest pattern is a focused review from a **separate coding-agent session** (a fresh context with its own brief), not just the lane that implemented the change. In practice this means: hand a reviewer a scoped brief (target, what is already covered, what to pressure-test) and have it verify behaviorally, executing adversarial and edge inputs rather than re-reading the diff.
Baton runs this as its loop (plan, implement, verify), but the independent-review step pays off most when the reviewer is genuinely separate. If your project has a dedicated review skill installed (for example `/code-review`, `/security-review`), route consequential reviews to it from your project's root `AGENTS.md`; the manager reads that as repo guidance and follows it. The built-in `code-reviewer` lane is the portable floor.
## What's in here
The skill is **entirely self-contained**. Everything lives in a single folder (`.claude/skills/baton/`); all paths below are relative to that root.
### Core orchestration and rules
- `SKILL.md`: the orchestrator skill (owns the loop, delegation rules, and lane map).
- `references/README.md`: the org SDLC extension point (Workflow, Platform, Acceptance, and Security rules).
- `evals/evals.json`: the 12 capability evaluation cases.
### Canonical subagent lanes
Only the implementer can edit files (it holds `Edit`/`Write` and a bounded write scope). The other three have no file-editing tools; they read, search, and run verification commands (`Bash` for build, test, and lint), and are prompted not to mutate the repo.
- `agents/triage.md`: size and risk evaluation to determine task disposition (no edits).
- `agents/implementer.md`: bounded implementation lane with a disjoint write scope (the only lane that edits).
- `agents/code-reviewer.md`: verification and adversarial review; runs checks, does not edit.
- `agents/researcher.md`: focused research and recovery investigation.
### Headless runtime engine (optional, opt-in)
Requires Node. Set up with `npm install` and run for local batch, CI/CD, or cloud use, with an on-by-default run trail (the ledger) auditing every run. Full setup, modes, and tuning are in [`docs/usage.md`](docs/usage.md).
- `runtime/src/orchestrator.ts`: the coordinator `query()` execution loop.
- `runtime/src/lanes.ts`: loads `agents/*.md` as programmatic `AgentDefinitions`.
- `runtime/src/offline.ts`: deterministic, offline repo detection (no model calls).
- `runtime/src/ledger.ts`: the on-by-default run log (`run.json` and `summary.md` under `.agents/runs/`; override the location with `BATON_LEDGER_DIR`, disable with `=off`).
- `runtime/src/mcp.ts`: the optional MCP passthrough loader.
- `runtime/.mcp.example.json`: a sample `.mcp.json` (Serena + Playwright, both local).
- `tools/` (repo root, **outside** the shipped skill): `install.sh` and the eval / smoke / bench / fault-catch runners (`run-evals.mjs`, `validate-evals.mjs`, …). Kept out of the skill so it is not scanned or installed with it; the runners drive the built runtime at `.claude/skills/baton/runtime/`.
## Lean footprint, deliberate spend
Baton needs no server, no database, no external control plane, and no new runtime to learn. It is a markdown skill (paired with an optional Node runtime), copied directly into your repository. That is the entire footprint.
It is also nearly free to carry in working memory. Loaded, the skill is roughly 2,000 tokens, and the four lane prompts add only a few hundred between them. Each lane's full instructions live inside its own context window _only while it runs_, so they never bloat the main coordinator's view. You can verify this in ten seconds with `/context` during a session. The token weight is the development work itself; the loop spends more, deliberately, on independent verification and a gated, auditable trail. It is a choice for lean scaffolding, not a cheaper run.
## Install
First, get Baton: clone the repo, then copy the skill folder out of it into your own project:
```bash
git clone https://github.com/andrewwint/baton && cd baton
```
**Per project.** Copy the folder into the repo you're working in:
```bash
cp -r .claude/skills/baton /.claude/skills/
```
The `/baton` command is then available in that repo.
**Global (all projects).** Install once into your personal Claude config:
```bash
cp -r .claude/skills/baton ~/.claude/skills/ # skill: available everywhere
bash tools/install.sh ~ # lanes → ~/.claude/agents/
```
| What | Where it goes | Notes |
| --------------------- | ----------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Skill** (`/baton`) | `.claude/skills/baton/` (project) or `~/.claude/skills/` (global) | Global is found in every project; on a name clash, the personal copy wins. |
| **Lanes** (subagents) | `.claude/agents/` (project) or `~/.claude/agents/` (global) | Needed for **interactive** use only. Subagents don't resolve from inside a skill folder; the runtime registers them in-process, so headless doesn't need this. |
## Using it
**Interactive Claude Code (the main way).** Install the skill (above), then invoke it in any project:
```text
/baton
```
The main conversation becomes the coordinator and runs the loop. For most people, that's the whole product, with no setup beyond the install.
### Headless runtime (optional)
A bundled TypeScript runtime runs the same loop without an interactive session, for local batch, CI/CD, or cloud use. You do not need it for normal interactive work. Setup, execution modes, cost and model tuning, the run trail, and optional MCP navigation are in [`docs/usage.md`](docs/usage.md).
## Make it yours
Baton is generic out of the box. Two folders are meant to be **adapted to your context**:
- **`references/`**: your org's SDLC, like ticketing/PR conventions, platform/deploy, acceptance gates, security posture. The coordinator consults the relevant one on demand; with none, it stays generic. See [`references/README.md`](.claude/skills/baton/references/README.md).
- **`evals/`**: Baton's 12 built-in capability cases encode what good orchestration _looks like_ (route vs. act direct, read-only review lanes, gated outward actions, recover-not-declare-done). Check structure with `npm run validate-evals` (no key); run live, LLM-judged, with `npm run evals`. **Add your own SDLC cases** in a `baton.evals.json` at your repo root (or point `BATON_EVALS` at any path): the runners merge it with the built-ins (new ids append, a matching id overrides), so your cases stay _yours_ and survive a skill update. Tie them to your `references/` gates (e.g. assert "checks `Acceptance.md` before declaring done") so "done" means what it means for your team. The repo's own [`baton.evals.json`](baton.evals.json) is a working example.
The live eval suite is **exploratory**: abstract prompts on empty workspaces don't yield a clean pass/fail, so treat `validate-evals` (structural) as the CI gate and live runs as a sanity check until you add fixtures for your own cases. The eval JSON shape is **internal dev tooling, not part of Baton's 1.0 contract**: it may change between versions, so treat it as a convenience, not an external API to build against.
## Security & trust
Baton orchestrates an AI agent, and is plain about what that means:
- **It runs an agent with real tools.** Interactively it uses Read/Edit/Write/Bash within Claude Code's permission model; the headless runtime defaults to `acceptEdits` (edits apply without prompts) so it can work unattended. Run it on code you're willing to let an agent change.
- **Hardening headless / CI runs.** Because the runtime defaults to `acceptEdits`, run it where unattended edits are safe: a sandboxed container or ephemeral CI job, on a fresh checkout or a git worktree it cannot escape. Give it a dedicated, least-privilege `ANTHROPIC_API_KEY` (or provider role) scoped to the pipeline, and rotate it. Even headless, outward-facing actions stay refused: the runtime does the reversible work and reports pushes, PRs, and deletions as follow-ups rather than performing them.
- **Outward-facing actions are approval-gated.** Push, PRs, ticket changes, deletions, and destructive rollbacks wait for your explicit OK, and you stay the credited author.
- **MCP servers you configure launch local commands** (e.g. Serena) with your privileges, so put only servers you trust in the project's `.mcp.json`. Baton discovers and allowlists exactly what it declares; off when none are configured.
- **No telemetry.** Baton makes model calls (and any MCP server you add) and writes a local run ledger; nothing else leaves your machine.
## Composing with other Claude Code features
Baton stays loosely coupled: it depends on no other skill, and composition is steered from your project, not baked into Baton:
- **Specialist skills.** Baton prescribes nothing about other skills. If you want the coordinator to route a lane to a skill you've installed (e.g. `code-review`, `security-review`, `deep-research`), say so in your project's root `AGENTS.md`; the manager reads it as repo guidance and follows it (long-running ones as background lanes).
## How this differs from an autonomous goal loop
The core difference is simple: an autonomous tool like Claude Code's `/goal` is a completion loop. It trusts a success condition and runs until it hits it. Baton is a gated, audited process that distrusts the green test suite and keeps you in control.
| Feature | Claude Code `/goal` | Baton |
| :---------------------- | :------------------------------------------------------ | :----------------------------------------------------------------------- |
| **Optimizes for** | Hands-off convergence on a stated condition | Consistency and catching hidden issues |
| **The checking helper** | A smaller evaluator asking: _"Are we done yet?"_ | A separate, same-tier reviewer trying to break the work |
| **What it checks** | Did the condition become true? (Tests pass, lint clean) | Is it actually correct, including cases tests missed? |
| **Method** | One agent looping and grading its own progress | Disjoint lanes; the reviewer acts as an independent adversarial observer |
| **Outward actions** | Autonomous by design (_"run on a branch"_) | Gated entirely on your explicit approval |
| **Shape** | **Outcome-driven** (reach the goal however) | **Process-driven** (discovery, plan, verify, audit trail) |
The independence is the point: an agent grading its own work shares the assumptions that produced the bug and tends to confirm it, while a separate reviewer in its own context, told to break the work, does not carry that bias.
Two distinctions stand out:
1. **The target definition:** `/goal` stops at the line you draw, usually using passing tests as the proxy; Baton checks whether that line was put in the right place.
2. **Where you step in:** Baton is human-gated at the finish lines, not at every step. It investigates, edits, and verifies on its own, stopping only before outward-facing actions like a push or a live deploy.
In short, `/goal` sprints to the whistle and trusts it. Baton runs a disciplined relay and keeps a judge who can wave off a result the scoreboard called good. Use `/goal` for a clear target you can fully specify; use Baton for development work where a green test suite should never be the last word.
## Why it's built this way
Key design choices (manager-led lanes, behavioral verification, the ~2-round recovery bound, the low-cost-model default) draw on published code-translation research, **by analogy** rather than proof, with Baton's own evals and live runs as the primary evidence. The decision-by-decision mapping of what we took, adapted, and left open is in [`docs/research-basis.md`](docs/research-basis.md).
**A run is only as good as what you feed it.** The loop runs the same way every time, but quality tracks the inputs: the acceptance criteria, the standards you encode (`references/`, lane prompts), and above all the sharpness of the review brief. A vague brief still produces a tidy, green, archived run that can ship a defect; a sharp adversarial brief is what makes the same loop catch real bugs. Baton makes discipline repeatable and auditable.
See [SKILL.md](.claude/skills/baton/SKILL.md) for the full loop, delegation policy, and lane map.
## Status
**1.0.0: stable contract** (semver from here; the frozen surface is in [CHANGELOG.md](CHANGELOG.md) and [docs/ROADMAP.md](docs/ROADMAP.md#road-to-10)). Contributing and ideas in [CONTRIBUTING.md](CONTRIBUTING.md). Real-world usage reports are especially welcome.
---
Powered by Claude.