https://github.com/ansh-info/Hadoop-Pipeline
An end-to-end data engineering pipeline to collect, store, process, and analyze property and crime data using Hadoop, Docker, MySQL, Tailscale, and Selenium
https://github.com/ansh-info/Hadoop-Pipeline
docker docker-compose hadoop jupyter-notebook mapreduce python selenium sql tailscale
Last synced: 10 months ago
JSON representation
An end-to-end data engineering pipeline to collect, store, process, and analyze property and crime data using Hadoop, Docker, MySQL, Tailscale, and Selenium
- Host: GitHub
- URL: https://github.com/ansh-info/Hadoop-Pipeline
- Owner: ansh-info
- Created: 2024-08-13T12:50:23.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2024-09-13T20:05:01.000Z (almost 2 years ago)
- Last Synced: 2024-09-28T02:01:15.228Z (almost 2 years ago)
- Topics: docker, docker-compose, hadoop, jupyter-notebook, mapreduce, python, selenium, sql, tailscale
- Language: Python
- Homepage:
- Size: 17.1 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Property and Locality Data Analysis
## Introduction
This project involves setting up a data engineering pipeline to collect, store, process, and analyze Property and Locality data using Hadoop, Docker, MySQL, Tailscale, and Selenium.
## Project Overview
- **Objective:** Analyze Property and Locality data to derive meaningful insights.
- **Scope:** Collect data through web scraping, store in HDFS, process using Hadoop, and analyze with MySQL.
# Video
Here is a demo video of the Pipeline:
[](https://www.youtube.com/watch?v=0sdQdd7E67o)
## Setup and Environment
### Virtual Machines Setup
- **Step:** Installed Ubuntu on VirtualBox for each VM.
- **Action:** Configured each VM with necessary packages including Docker and Docker Compose.
### Networking with Tailscale
- **Step:** Installed and configured Tailscale on all VMs.
- **Action:** Created a secure virtual network to enable communication between VMs.
### Docker Swarm Initialization
- **Step:** Initialized Docker Swarm on the master node and joined worker nodes.
- **Action:** Used Docker Swarm for container orchestration.
### Image of Setup Process

## Data Collection
### Web Scraping with Selenium
- **Step:** Installed Selenium and Chrome WebDriver.
- **Action:** Developed scripts to scrape Property and Locality data from various websites.
### Image of Collection Process

## Data Storage in HDFS
- **Step:** `cd spark cluster` folder to use, A ready to go Big Data cluster (Hadoop + Hadoop Streaming + Spark + PySpark + Jupyter Notebook) with Docker and Docker Swarm!
Configured HDFS on the Hadoop cluster provided by `Prof. Dr.-Ing.` [Binh Vu](https://github.com/binhvd). Check the README.md file in the spark cluster folder to begin with the setup process`
- **Action:** Stored scraped data in HDFS with appropriate partitioning and replication.
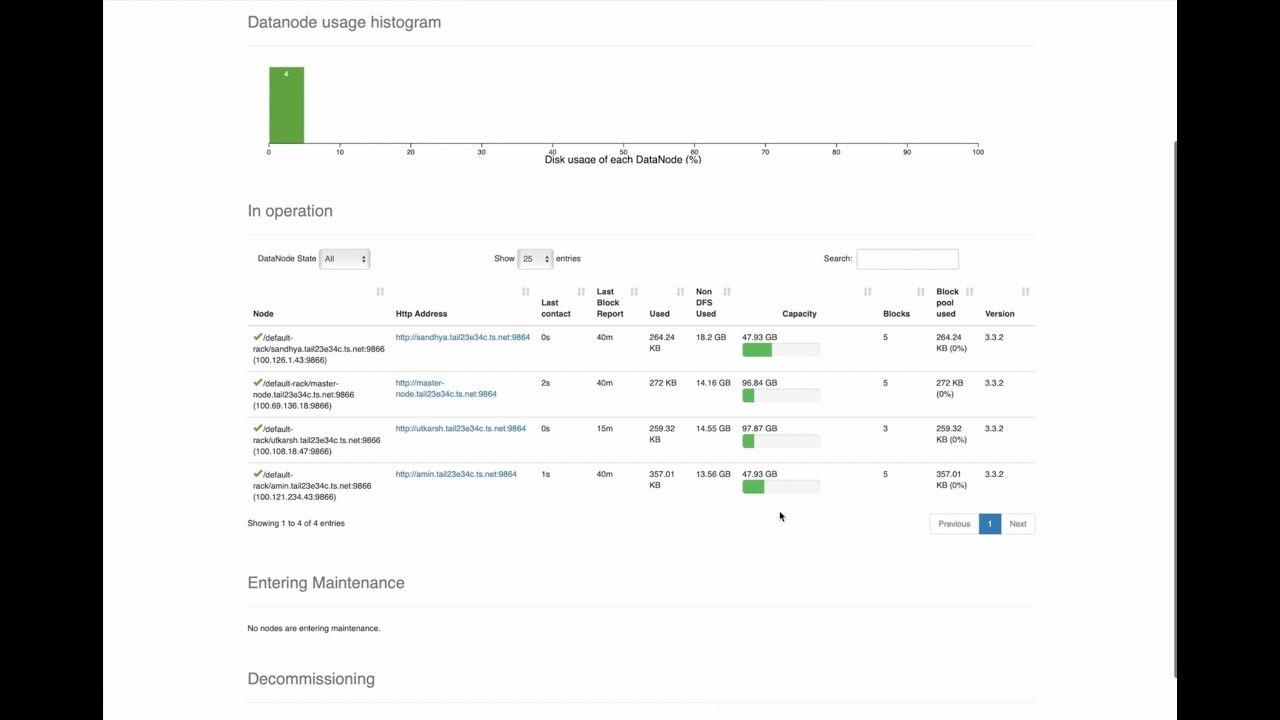
### Image of Data Storage in HDFS Process

## Data Processing
### Hadoop Job Development
- **Step:** Developed and executed Hadoop jobs for data cleaning and transformation.
- **Action:** Used MapReduce for distributed processing.
### Image of Data Processing Process

## Failure Test
- **Step:** Conducted data read/write operations while intentionally shutting down a worker node.
- **Action:** Verified system resilience and fault tolerance.
### Image of Failure Test Process - node down

### Image of Failure Test Process - ingestion to mysql

## Data Ingestion into MySQL
### Database Design
- **Step:** Created a relational database schema in MySQL.
- **Action:** Developed scripts to ingest data from HDFS to MySQL.
### Image of Database Schema

## Business Insights
### Query Development
- **Step:** Developed SQL queries to extract insights from the database.
- **Action:** Generated graphs and tables to present the results.
### Image of Business Insights Visualization

## Acknowledgements
- **Note:** A special thank you to `Prof. Dr.-Ing.` [Binh Vu](https://github.com/binhvd) for providing the ready-to-go Spark cluster image used in this project.
---