https://github.com/apache/kylin
Apache Kylin
https://github.com/apache/kylin
kylin
Last synced: 8 months ago
JSON representation
Apache Kylin
- Host: GitHub
- URL: https://github.com/apache/kylin
- Owner: apache
- License: apache-2.0
- Created: 2015-01-03T08:00:05.000Z (over 11 years ago)
- Default Branch: kylin5
- Last Pushed: 2025-10-20T06:00:44.000Z (9 months ago)
- Last Synced: 2025-11-12T21:36:04.567Z (8 months ago)
- Topics: kylin
- Language: Java
- Homepage:
- Size: 547 MB
- Stars: 3,759
- Watchers: 256
- Forks: 1,521
- Open Issues: 80
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- likes - apache/__kylin__
- awesome-dataops - Apache Kylin - An open source, distributed analytical data warehouse for big data. (Data Warehouse / Data Table Format)
- awesome-java - Apache Kylin
README
# Apache Kylin
[](https://www.apache.org/licenses/LICENSE-2.0.html)
[](https://github.com/apache/kylin/releases)
[](https://github.com/apache/kylin/commits/kylin5/)
[](https://kylin.apache.org/docs/overview)
[![Website]()](https://kylin.apache.org/)
[![Download]()](https://kylin.apache.org/docs/download)
---
Apache Kylin is a leading open source OLAP engine for Big Data capable for sub-second query latency on trillions of records. Since being created and open sourced by eBay in 2014, and graduated to Top Level Project of Apache Software Foundation in 2015.
Kylin has quickly been adopted by thousands of organizations world widely as their critical analytics application for Big Data.
Kylin has following key strengths:
- High qerformance, high concurrency, sub-second query latency
- Unified big data warehouse architecture
- Seamless integration with BI tools
- Comprehensive and enterprise-ready capabilities

## What's New in Kylin 5.0
### 📊 1. Internal Table
Kylin now support internal table, which is designed for flexible query and lakehouse scenarios.
### 🦁 2. Model & Index Recommendation
With recommendation engine, you don't have to be an expert of modeling. Kylin now can auto modeling and optimizing indexes from you query history.
You can also create model by importing sql text.
### 👾 3. Native Compute Engine
Start from version 5.0, Kylin has integrated Gluten-ClickHouse Backend(incubating in apache software foundation) as native compute engine. And use Gluten mergetree as the default storage format of internal table.
Which can bring 2~4x performance improvement compared with vanilla spark. Both model and internal table queries can get benefits from the Gluten integration.
### 🧜🏻♀️ 4. Streaming Data Source
Kylin now support Apache Kafka as streaming data source of model building. Users can create a fusion model to implement streaming-batch hybrid analysis.
## Significant Change
### 🤖1. Metadata Refactory
In Kylin 5.0, we have refactored the metadata storage structure and the transaction process, removed the project lock and Epoch mechanism. This has significantly improved transaction interface performance and system concurrency capabilities.
To upgrade from 5.0 alpha, beta, follow the [Metadata Migration Guide](https://kylin.apache.org/docs/operations/system-operation/cli_tool/metadata_operation#migration)
The metadata migration tool for upgrading from Kylin 4.0 is not tested, please contact kylin user or dev mailing list for help.
### Other Optimizations and Improvements
Please refer to [Release Notes](https://kylin.apache.org/docs/release_notes/) for more details.
## Quick Start
### 🐳 Play Kylin in Docker
To explore new features in Kylin 5 on a laptop, we recommend pulling the Docker image and checking the [Apache Kylin Standalone Image on Docker Hub](https://hub.docker.com/r/apachekylin/apache-kylin-standalone) (For amd64 platform).
```shell
docker run -d \
--name Kylin5-Machine \
--hostname localhost \
-e TZ=UTC \
-m 10G \
-p 7070:7070 \
-p 8088:8088 \
-p 9870:9870 \
-p 8032:8032 \
-p 8042:8042 \
-p 2181:2181 \
apachekylin/apache-kylin-standalone:5.0.0-GA
```
---
### Introduction
Kylin utilizes multidimensional modeling theory to build star or snowflake schemas based on tables, making it a powerful tool for large-scale data analysis. The **model** is Kylin's core component, consisting of three key aspects: *model design*, *index design*, and *data loading*. By carefully designing the model, optimizing indexes, and pre-computed data, queries executed on Kylin can avoid scanning the entire dataset, potentially reducing response times to mere seconds, even for petabyte-scale data.
+ **Model design** refers to establishing relationships between data tables to enable fast extraction of key information from multidimensional data. The core elements of model design are computed columns, dimensions, measures, and join relations.
+ **Index design** refers to creating indexes (CUBEs) within the model to precompute query results, thereby reducing query response time. Well-designed indexes not only improve query performance but also help minimize the storage and data-loading costs associated with precomputation.
+ **Data loading** refers to the process of importing data into the model, enabling queries to utilize the pre-built indexes rather than scanning the entire dataset. This allows for faster query responses by leveraging the model's optimized structure.
### Core Concepts
- **Dimension**: A perspective of viewing data, which can be used to describe object attributes or characteristics, for example, product category.
- **Measure**: An aggregated sum, which is usually a continuous value, for example, product sales.
- **Pre-computation**: The process of aggregating data based on model dimension combinations and of storing the results as indexes to accelerate data query.
- **Index**: Also called CUBE, which is used to accelerate data query. Indexes are divided into:
- **Aggregate Index**: An aggregated combination of multiple dimensions and measures, and can be used to answer aggregate queries such as total sales for a given year.
- **Table Index**: A multilevel index in a wide table and can be used to answer detailed queries such as the last 100 transactions of a certain user.
---
### Why Use Kylin
+ **Low Query Latency vs. Large Volume**
When analyzing massive data, there are some techniques to speed up computing and storage, but they cannot change the time complexity of query, that is, query latency and data volume are linearly dependent.
If it takes 1 minute to query 100 million entries of data records, querying 10 billion data entries will take about 1 hour and 40 minutes. When companies want to analyze all business data piled up over the years or to add complexity to query, say, with more dimensions, queries will be running extremely slow or even time out.
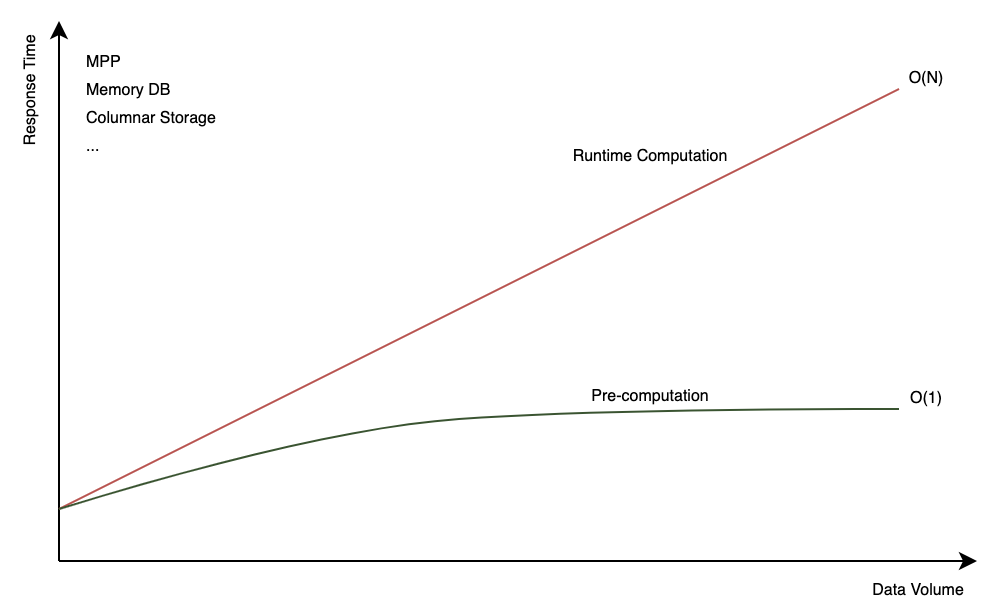
+ **Pre-computation vs. Runtime Computation**
Pre-computation and runtime computation are two approaches to calculating results in data processing and analytics. **Pre-computation** involves calculating and storing results in advance, so they can be quickly retrieved when a query is run. In contrast, **runtime computation** dynamically computes results during query execution, processing raw data and applying aggregations, filters, or transformations as needed for each query.
Kylin primarily focuses on **pre-computation** to enhance query performance. However, we also offer advanced features that partially support runtime computation. For more details, please refer to [Table Snapshot](https://kylin.apache.org/docs/model/snapshot/), [Runtime Join](https://kylin.apache.org/docs/model/features/runtime_join), and [Internal Table](https://kylin.apache.org/docs/internaltable/intro).
+ **Manual Modeling vs. Recommendation**
Before Kylin 5.0, model design had to be done manually, which was a tedious process requiring extensive knowledge of multidimensional modeling. However, this changed with the introduction of Kylin 5.0. We now offer a new approach to model design, called **recommendation**, which allows models to be created by importing SQL, along with an automatic way to remove unnecessary indexes. Additionally, the system can leverage query history to generate index recommendations, further optimizing query performance. For more details, please refer to [Recommendation](https://kylin.apache.org/docs/model/rec/intro).
+ **Batch Data vs. Streaming Data**
In the OLAP field, data has traditionally been processed in batches. However, this is changing as more companies are now required to handle both batch and streaming data to meet their business objectives. The ability to process data in real-time has become increasingly critical for applications such as real-time analytics, monitoring, and event-driven decision-making.
To address these evolving needs, we have introduced support for streaming data in the new version. This allows users to efficiently process and analyze data as it is generated, complementing the traditional batch processing capabilities. For more details, please refer to [Streaming](https://kylin.apache.org/docs/model/streaming/intro).