https://github.com/arklexai/arksim
Find your agents errors be fore your real users do
https://github.com/arklexai/arksim
agents ai chatbot conversational-ai evaluation llm open-source python simulation testing
Last synced: 2 months ago
JSON representation
Find your agents errors be fore your real users do
- Host: GitHub
- URL: https://github.com/arklexai/arksim
- Owner: arklexai
- License: apache-2.0
- Created: 2026-02-27T13:45:12.000Z (4 months ago)
- Default Branch: main
- Last Pushed: 2026-04-21T14:15:20.000Z (3 months ago)
- Last Synced: 2026-04-21T15:35:57.469Z (3 months ago)
- Topics: agents, ai, chatbot, conversational-ai, evaluation, llm, open-source, python, simulation, testing
- Language: Python
- Homepage: https://docs.arklex.ai
- Size: 3.18 MB
- Stars: 158
- Watchers: 2
- Forks: 15
- Open Issues: 14
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
- Codeowners: .github/CODEOWNERS
- Security: SECURITY.md
- Notice: NOTICE
Awesome Lists containing this project
README
⛵️ ArkSim
Simulate multi-turn conversations with your AI agent. Find failures before production.











Documentation · Examples · Report a Bug
https://github.com/user-attachments/assets/78706f27-cf49-41c1-8019-9dcbb8abc625
## What is ArkSim?
Agents fail in ways that only show up mid-conversation. They misinterpret intent three turns in, call the wrong tool, or hallucinate a policy that does not exist. Single-turn testing misses all of this.
ArkSim generates LLM-powered synthetic users that hold realistic multi-turn conversations with your agent. Each user has a distinct profile, goal, and knowledge level. They push back, ask follow-ups, and behave like real users would.
You define scenarios, ArkSim simulates conversations, then evaluates every turn across metrics like helpfulness, faithfulness, and goal completion. The output is an interactive report showing exactly where your agent broke and why.

## Quickstart
### Have an agent? Test it in 3 commands:
```bash
pip install arksim
export OPENAI_API_KEY="your-key"
arksim init
# Edit my_agent.py with your agent logic, then run:
arksim simulate-evaluate config.yaml
```
This generates `config.yaml`, `scenarios.json`, and a starter `my_agent.py`.
For HTTP or A2A agents: `arksim init --agent-type chat_completions` or `arksim init --agent-type a2a`.
For Anthropic or Google as the evaluation LLM: `pip install "arksim[anthropic]"` or `pip install "arksim[google]"`.
### Just exploring? Try an example:
```bash
pip install arksim
export OPENAI_API_KEY="your-key"
arksim examples
cd examples/e-commerce
arksim simulate-evaluate config.yaml
```
### What you'll see
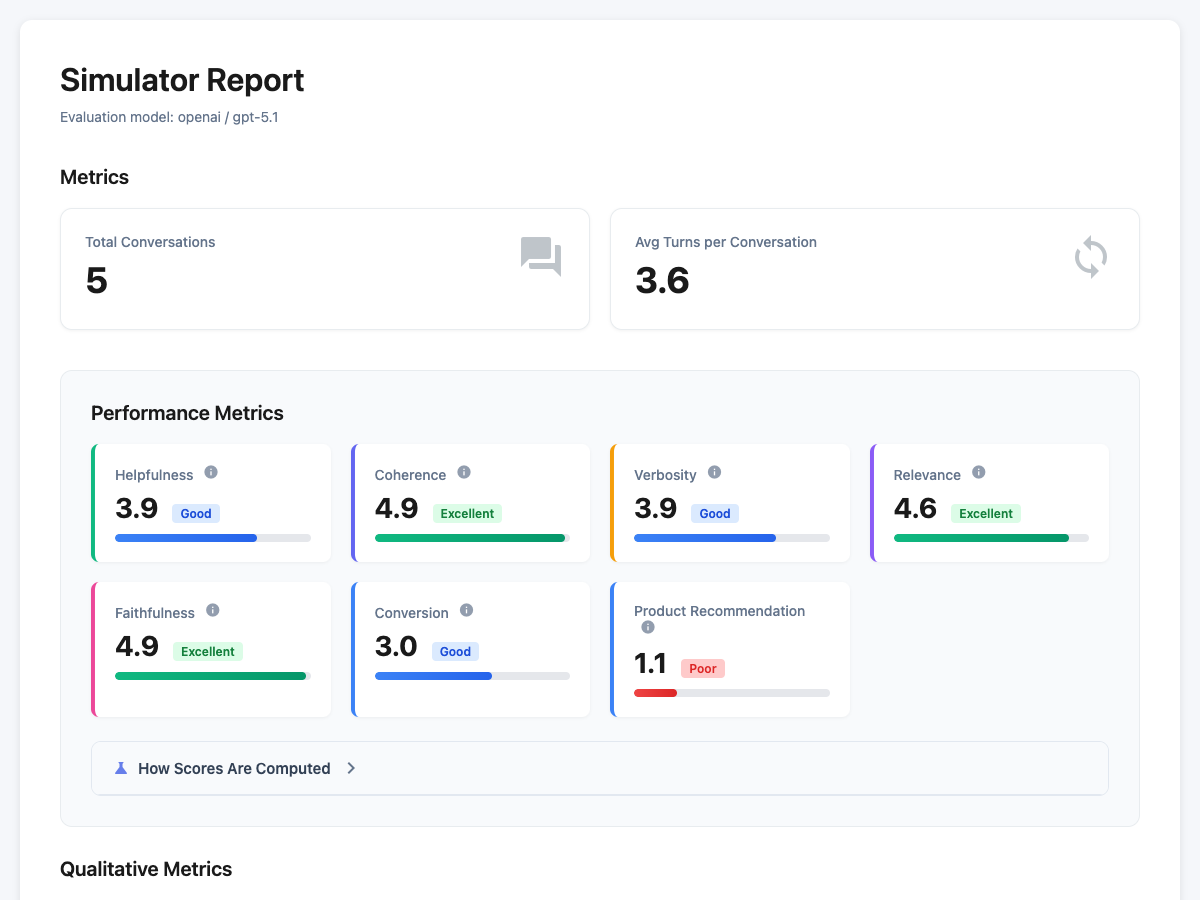
The report tells you where your agent is strong and where it breaks. You get per-metric scores, categorized failures, and full conversation transcripts so you can read the exact turns where things went wrong.
## Test Your Own Agent
### Python class (default)
`arksim init` generates a `my_agent.py` with a BaseAgent subclass. Replace the `execute()` body with your agent logic:
```python
from arksim.simulation_engine.agent.base import BaseAgent
from arksim.simulation_engine.tool_types import AgentResponse
class MyAgent(BaseAgent):
async def get_chat_id(self) -> str:
return "unique-id"
async def execute(self, user_query: str, **kwargs: object) -> str | AgentResponse:
# Replace with your agent logic
return "agent response"
```
### Chat Completions endpoint
```yaml
agent_config:
agent_type: chat_completions
agent_name: my-agent
api_config:
endpoint: http://localhost:8000/v1/chat/completions
```
### A2A protocol
```yaml
agent_config:
agent_type: a2a
agent_name: my-agent
api_config:
endpoint: http://localhost:9999/agent
```
A2A agents can also surface tool calls for evaluation via the arksim [tool call capture extension](https://docs.arklex.ai/main/tool-call-capture). See `examples/customer-service/a2a_server/` for a runnable reference server.
Write scenarios that match your agent's domain. See the [Scenarios documentation](https://docs.arklex.ai/main/build-scenario) for how to define goals, user profiles, and knowledge.
## Why ArkSim?
- **Simulation, not just evaluation.** Most tools score conversations you already have. ArkSim generates them with synthetic users who push back, ask follow-ups, and behave unpredictably.
- **Multi-turn by default.** Every test is a full conversation, not a single prompt. Context loss, tool misuse, and contradictions only show up across turns.
- **Any agent, any framework.** Works with [14+ frameworks](#integrations) through Chat Completions, A2A, or direct Python import.
- **Runs in CI.** Add it as a quality gate on every PR. Exits non-zero when your agent drops below threshold.
- **Fully open source.** Runs on your infrastructure. Your data never leaves.
## Integrations
| Framework | Provider |
|-----------|----------|
| [Claude Agent SDK](https://github.com/arklexai/arksim/tree/main/examples/integrations/claude-agent-sdk) | Anthropic |
| [OpenAI Agents SDK](https://github.com/arklexai/arksim/tree/main/examples/integrations/openai-agents-sdk) | OpenAI |
| [Google ADK](https://github.com/arklexai/arksim/tree/main/examples/integrations/google-adk) | Google |
| [LangChain](https://github.com/arklexai/arksim/tree/main/examples/integrations/langchain) | LangChain |
| [LangGraph](https://github.com/arklexai/arksim/tree/main/examples/integrations/langgraph) | LangChain |
| [CrewAI](https://github.com/arklexai/arksim/tree/main/examples/integrations/crewai) | CrewAI |
| [Dify](https://github.com/arklexai/arksim/tree/main/examples/integrations/dify) | Dify |
| [AutoGen](https://github.com/arklexai/arksim/tree/main/examples/integrations/autogen) | Microsoft |
| [LlamaIndex](https://github.com/arklexai/arksim/tree/main/examples/integrations/llamaindex) | LlamaIndex |
| [Pydantic AI](https://github.com/arklexai/arksim/tree/main/examples/integrations/pydantic-ai) | Pydantic |
| [Rasa](https://github.com/arklexai/arksim/tree/main/examples/integrations/rasa) | Rasa |
| [Smolagents](https://github.com/arklexai/arksim/tree/main/examples/integrations/smolagents) | Hugging Face |
| [Mastra](https://github.com/arklexai/arksim/tree/main/examples/integrations/mastra) | TypeScript |
| [Vercel AI SDK](https://github.com/arklexai/arksim/tree/main/examples/integrations/vercel-ai-sdk) | TypeScript |
See [examples](https://github.com/arklexai/arksim/tree/main/examples) for end-to-end projects with custom metrics and scenarios.
## Learn More
| Topic | |
|-------|---|
| Evaluation metrics (built-in and custom) | [Metrics guide](https://docs.arklex.ai/main/evaluate-conversation) |
| CI integration (pytest and GitHub Actions) | [CI setup guide](https://docs.arklex.ai/main/ci-integration) |
| Configuration reference (all YAML settings) | [Schema reference](https://docs.arklex.ai/main/schema-reference) |
| Simulation and CLI usage | [Simulation guide](https://docs.arklex.ai/main/simulate-conversation) |
| Web UI for browsing results | [Overview](https://docs.arklex.ai/main/overview) |
## Development
```bash
git clone https://github.com/arklexai/arksim.git
cd arksim
pip install -e ".[dev]"
pytest tests/
```
Linting and formatting:
```bash
ruff check .
ruff format .
```
See [CONTRIBUTING.md](https://github.com/arklexai/arksim/blob/main/CONTRIBUTING.md) for guidelines.
## License
Apache-2.0. See [LICENSE](https://github.com/arklexai/arksim/blob/main/LICENSE).
## Citation
```bibtex
@misc{shea2026sage,
title={SAGE: A Top-Down Bottom-Up Knowledge-Grounded User Simulator for Multi-turn AGent Evaluation},
author={Ryan Shea and Yunan Lu and Liang Qiu and Zhou Yu},
year={2026},
eprint={2510.11997},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2510.11997},
}
```
## Star History
[](https://star-history.com/#arklexai/arksim&date)