https://github.com/asahi417/tner
Language model fine-tuning on NER with an easy interface and cross-domain evaluation. "T-NER: An All-Round Python Library for Transformer-based Named Entity Recognition, EACL 2021"
https://github.com/asahi417/tner
language-model named-entity-recognition nlp transformers
Last synced: about 2 months ago
JSON representation
Language model fine-tuning on NER with an easy interface and cross-domain evaluation. "T-NER: An All-Round Python Library for Transformer-based Named Entity Recognition, EACL 2021"
- Host: GitHub
- URL: https://github.com/asahi417/tner
- Owner: asahi417
- License: mit
- Created: 2020-08-27T05:42:04.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2023-05-11T08:22:36.000Z (about 2 years ago)
- Last Synced: 2025-04-06T05:15:03.513Z (2 months ago)
- Topics: language-model, named-entity-recognition, nlp, transformers
- Language: Python
- Homepage: https://aclanthology.org/2021.eacl-demos.7/
- Size: 54.7 MB
- Stars: 386
- Watchers: 8
- Forks: 41
- Open Issues: 17
-
Metadata Files:
- Readme: README.md
- License: LICENSE.txt
Awesome Lists containing this project
README
[](https://github.com/asahi417/tner/blob/master/LICENSE)
[](https://badge.fury.io/py/tner)
[](https://pypi.python.org/pypi/tner/)
[](https://pypi.python.org/pypi/tner/)

# T-NER: An All-Round Python Library for Transformer-based Named Entity Recognition
***T-NER*** is a Python tool for language model finetuning on named-entity-recognition (NER) implemented in pytorch, available via [pip](https://pypi.org/project/tner/).
It has an easy interface to finetune models and test on cross-domain and multilingual datasets.
T-NER currently integrates high coverage of publicly available NER datasets and enables an easy integration of custom datasets.
All models finetuned with T-NER can be deployed on our web app for visualization.
[Our paper demonstrating T-NER](https://www.aclweb.org/anthology/2021.eacl-demos.7/) has been accepted to EACL 2021.
All the models and datasets are shared via [T-NER HuggingFace group](https://huggingface.co/tner).
***NEW (September 2022):*** We released new NER dataset based on Twitter [`tweetner7`](https://huggingface.co/datasets/tner/tweetner7) and the paper got accepted by AACL 2022 main conference! We release the dataset along with fine-tuned models, and more details can be found at the [paper](https://aclanthology.org/2022.aacl-main.25/), [repository](https://github.com/asahi417/tner/tree/master/examples/tweetner7_paper) and [dataset page](https://huggingface.co/datasets/tner/tweetner7). The Twitter NER model has also been integrated into [TweetNLP](https://github.com/cardiffnlp/tweetnlp), and a demo is available [here](https://tweetnlp.org/demo/).
- Resources: [**MODEL_CARD**](https://github.com/asahi417/tner/blob/master/MODEL_CARD.md), [**DATASET_CARD**](https://github.com/asahi417/tner/blob/master/DATASET_CARD.md), [**Gradio Online DEMO**](https://huggingface.co/spaces/tner/NER)
- HuggingFace: [**https://huggingface.co/tner**](https://huggingface.co/tner)
- GitHub: [**https://github.com/asahi417/tner**](https://github.com/asahi417/tner)
- Papers
- T-NER (EACL2021): [**acl anthology**](https://aclanthology.org/2021.eacl-demos.7/), [**arxiv**](https://arxiv.org/abs/2209.12616)
- TweetNER7 (AACL 2022): [**arxiv**](https://arxiv.org/abs/2210.03797)
Install `tner` via pip to get started!
```shell
pip install tner
```
## Table of Contents
1. **[Dataset](#dataset)**
1.1 **[Preset Dataset](#preset-dataset)**
1.2 **[Custom Dataset](#custom-dataset)**
2. **[Model](#model)**
3. **[Fine-Tuning Language Model on NER](#fine-tuning-language-model-on-ner)**
4. **[Evaluating NER Model](#evaluating-ner-model)**
5. **[Web API](#web-app)**
6. **[Colab Examples](#google-colab-examples)**
7. **[Reference](#reference)**
### Google Colab Examples
| Description | Link |
|---------------------------|-------|
| Model Finetuning & Evaluation | [](https://colab.research.google.com/drive/1AlcTbEsp8W11yflT7SyT0L4C4HG6MXYr?usp=sharing) |
| Model Prediction | [](https://colab.research.google.com/drive/1mQ_kQWeZkVs6LgV0KawHxHckFraYcFfO?usp=sharing) |
| Multilingual NER Workflow | [](https://colab.research.google.com/drive/1Mq0UisC2dwlVMP9ar2Cf6h5b1T-7Tdwb?usp=sharing) |
## Dataset
An NER dataset contains a sequence of tokens and tags for each split (usually `train`/`validation`/`test`),
```python
{
'train': {
'tokens': [
['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.'],
['From', 'Green', 'Newsfeed', ':', 'AHFA', 'extends', 'deadline', 'for', 'Sage', 'Award', 'to', 'Nov', '.', '5', 'http://tinyurl.com/24agj38'], ...
],
'tags': [
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], ...
]
},
'validation': ...,
'test': ...,
}
```
with a dictionary to map a label to its index (`label2id`) as below.
```python
{"O": 0, "B-ORG": 1, "B-MISC": 2, "B-PER": 3, "I-PER": 4, "B-LOC": 5, "I-ORG": 6, "I-MISC": 7, "I-LOC": 8}
```
### Preset Dataset
A variety of public NER datasets are available on our [HuggingFace group](https://huggingface.co/tner), which can be used as below
(see [DATASET CARD](https://github.com/asahi417/tner/blob/master/DATASET_CARD.md) for full dataset lists).
```python
from tner import get_dataset
data, label2id = get_dataset(dataset="tner/wnut2017")
```
User can specify multiple datasets to get a concatenated dataset.
```python
data, label2id = get_dataset(dataset=["tner/conll2003", "tner/ontonotes5"])
```
In concatenated datasets, we use the [unified label set](https://raw.githubusercontent.com/asahi417/tner/master/unified_label2id.json) to unify the entity label.
The idea is to share all the available NER datasets on the HuggingFace in a unified format, so let us know if you want any NER datasets to be added there!
### Custom Dataset
To go beyond the public datasets, users can use their own datasets by formatting them into
the IOB format described in [CoNLL 2003 NER shared task paper](https://www.aclweb.org/anthology/W03-0419.pdf),
where all data files contain one word per line with empty lines representing sentence boundaries.
At the end of each line there is a tag which states whether the current word is inside a named entity or not.
The tag also encodes the type of named entity. Here is an example sentence:
```
EU B-ORG
rejects O
German B-MISC
call O
to O
boycott O
British B-MISC
lamb O
. O
```
Words tagged with O are outside of named entities and the I-XXX tag is used for words inside a
named entity of type XXX. Whenever two entities of type XXX are immediately next to each other, the
first word of the second entity will be tagged B-XXX in order to show that it starts another entity.
Please take a look [sample custom data](https://github.com/asahi417/tner/tree/master/examples/local_dataset_sample).
Those custom files can be loaded in a same way as HuggingFace dataset as below.
```python
from tner import get_dataset
data, label2id = get_dataset(local_dataset={
"train": "examples/local_dataset_sample/train.txt",
"valid": "examples/local_dataset_sample/train.txt",
"test": "examples/local_dataset_sample/test.txt"
})
```
Same as the HuggingFace dataset, one can concatenate dataset.
```python
data, label2id = get_dataset(local_dataset=[
{"train": "...", "valid": "...", "test": "..."},
{"train": "...", "valid": "...", "test": "..."}
]
)
```
## Model
T-NER currently has shared more than 100 NER models on [HuggingFace group](https://huggingface.co/tner), as shown in the above table, which reports the major models only and see [MODEL_CARD](https://github.com/asahi417/tner/blob/master/MODEL_CARD.md) for full model lists.
All the models can be used with `tner` as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-wnut2017") # provide model alias on huggingface
output = model.predict(["Jacob Collier is a Grammy awarded English artist from London"]) # give a list of sentences (or tokenized sentence)
print(output)
{
'prediction': [['B-person', 'I-person', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-location']],
'probability': [[0.9967652559280396, 0.9994561076164246, 0.9986955523490906, 0.9947081804275513, 0.6129112243652344, 0.9984312653541565, 0.9868122935295105, 0.9983410835266113, 0.9995284080505371, 0.9838910698890686]],
'input': [['Jacob', 'Collier', 'is', 'a', 'Grammy', 'awarded', 'English', 'artist', 'from', 'London']],
'entity_prediction': [[
{'type': 'person', 'entity': ['Jacob', 'Collier'], 'position': [0, 1], 'probability': [0.9967652559280396, 0.9994561076164246]},
{'type': 'location', 'entity': ['London'], 'position': [9], 'probability': [0.9838910698890686]}
]]
}
```
The [`model.predict`](https://github.com/asahi417/tner/blob/master/tner/ner_model.py#L189) takes a list of sentences and batch size `batch_size` optionally, and tokenizes the sentence by a half-space or
the symbol specified by `separator`, which is returned as `input` in its output object. Optionally, user can tokenize the
inputs beforehand with any tokenizer (spacy, nltk, etc) and the prediction will follow the tokenization.
```python
output = model.predict([["Jacob Collier", "is", "a", "Grammy awarded", "English artist", "from", "London"]])
print(output)
{
'prediction': [['B-person', 'O', 'O', 'O', 'O', 'O', 'B-location']],
'probability': [[0.9967652559280396, 0.9986955523490906, 0.9947081804275513, 0.6129112243652344, 0.9868122935295105, 0.9995284080505371, 0.9838910698890686]],
'input': [['Jacob Collier', 'is', 'a', 'Grammy awarded', 'English artist', 'from', 'London']],
'entity_prediction': [[
{'type': 'person', 'entity': ['Jacob Collier'], 'position': [0], 'probability': [0.9967652559280396]},
{'type': 'location', 'entity': ['London'], 'position': [6], 'probability': [0.9838910698890686]}
]]
}
```
A local model checkpoint can be specified instead of model alias `TransformersNER("path-to-checkpoint")`.
Script to re-produce those released models is [here](https://github.com/asahi417/tner/blob/master/examples/model_finetuning/single_dataset.sh).
### command-line tool
Following command-line tool is available for model prediction.
```shell
tner-predict [-h] -m MODEL
command line tool to test finetuned NER model
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
model alias of huggingface or local checkpoint
```
- Example
```shell
tner-predict -m "tner/roberta-large-wnut2017"
```
## Web App
To install dependencies to run the web app, add option at installation.
```shell script
pip install tner[app]
```
Then, clone the repository
```shell script
git clone https://github.com/asahi417/tner
cd tner
```
and launch the server.
```shell script
uvicorn app:app --reload --log-level debug --host 0.0.0.0 --port 8000
```
Open your browser [http://0.0.0.0:8000](http://0.0.0.0:8000) once ready.
You can specify model to deploy by an environment variable `NER_MODEL`, which is set as `tner/roberta-large-wnut2017` as a default.
`NER_MODEL` can be either path to your local model checkpoint directory or model name on transformers model hub.
***Acknowledgement*** The App interface is heavily inspired by [this repository](https://github.com/renatoviolin/Multiple-Choice-Question-Generation-T5-and-Text2Text).
## Fine-Tuning Language Model on NER
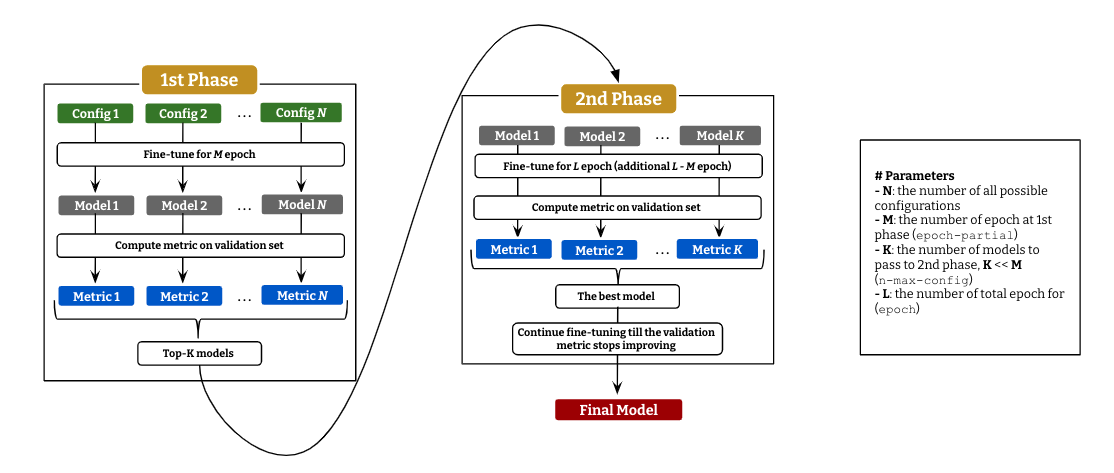
T-NER provides an easy API to run language model fine-tuning on NER with an efficient parameter-search as described above.
It consists of 2 stages: (i) fine-tuning with every possible configurations for a small epoch and
compute evaluation metric (micro F1 as default) on the validation set for all the models, and (ii) pick up top-`K` models to continue fine-tuning till `L` epoch.
The best model in the second stage will continue fine-tuning till the validation metric get decreased.
This fine-tuning with two-stage parameter search can be achieved in a few lines with `tner`.
```python
from tner import GridSearcher
searcher = GridSearcher(
checkpoint_dir='./ckpt_tner',
dataset="tner/wnut2017", # either of `dataset` (huggingface dataset) or `local_dataset` (custom dataset) should be given
model="roberta-large", # language model to fine-tune
epoch=10, # the total epoch (`L` in the figure)
epoch_partial=5, # the number of epoch at 1st stage (`M` in the figure)
n_max_config=3, # the number of models to pass to 2nd stage (`K` in the figure)
batch_size=16,
gradient_accumulation_steps=[4, 8],
crf=[True, False],
lr=[1e-4, 1e-5],
weight_decay=[1e-7],
random_seed=[42],
lr_warmup_step_ratio=[0.1],
max_grad_norm=[10]
)
searcher.train()
```
Following parameters are tunable at the moment.
- `gradient_accumulation_steps`: the number of gradient accumulation
- `crf`: use CRF on top of output embedding
- `lr`: learning rate
- `weight_decay`: coefficient for weight decay
- `random_seed`: random seed
- `lr_warmup_step_ratio`: linear warmup ratio of learning rate, eg) if it's 0.3, the learning rate will warmup linearly till 30% of the total step (no decay after all)
- `max_grad_norm`: norm for gradient clipping
See [source](https://github.com/asahi417/tner/blob/master/tner/ner_trainer.py#L275) for more information about each argument.
### command-line tool
Following command-line tool is available for fine-tuning.
```shell
tner-train-search [-h] -c CHECKPOINT_DIR [-d DATASET [DATASET ...]] [-l LOCAL_DATASET [LOCAL_DATASET ...]]
[--dataset-name DATASET_NAME [DATASET_NAME ...]] [-m MODEL] [-b BATCH_SIZE] [-e EPOCH] [--max-length MAX_LENGTH] [--use-auth-token]
[--dataset-split-train DATASET_SPLIT_TRAIN] [--dataset-split-valid DATASET_SPLIT_VALID] [--lr LR [LR ...]]
[--random-seed RANDOM_SEED [RANDOM_SEED ...]] [-g GRADIENT_ACCUMULATION_STEPS [GRADIENT_ACCUMULATION_STEPS ...]]
[--weight-decay WEIGHT_DECAY [WEIGHT_DECAY ...]] [--lr-warmup-step-ratio LR_WARMUP_STEP_RATIO [LR_WARMUP_STEP_RATIO ...]]
[--max-grad-norm MAX_GRAD_NORM [MAX_GRAD_NORM ...]] [--crf CRF [CRF ...]] [--optimizer-on-cpu] [--n-max-config N_MAX_CONFIG]
[--epoch-partial EPOCH_PARTIAL] [--max-length-eval MAX_LENGTH_EVAL]
Fine-tune transformers on NER dataset with Robust Parameter Search
optional arguments:
-h, --help show this help message and exit
-c CHECKPOINT_DIR, --checkpoint-dir CHECKPOINT_DIR
checkpoint directory
-d DATASET [DATASET ...], --dataset DATASET [DATASET ...]
dataset name (or a list of it) on huggingface tner organization eg. 'tner/conll2003' ['tner/conll2003', 'tner/ontonotes5']] see
https://huggingface.co/datasets?search=tner for full dataset list
-l LOCAL_DATASET [LOCAL_DATASET ...], --local-dataset LOCAL_DATASET [LOCAL_DATASET ...]
a dictionary (or a list) of paths to local BIO files eg.{"train": "examples/local_dataset_sample/train.txt", "test":
"examples/local_dataset_sample/test.txt"}
--dataset-name DATASET_NAME [DATASET_NAME ...]
[optional] data name of huggingface dataset (should be same length as the `dataset`)
-m MODEL, --model MODEL
model name of underlying language model (huggingface model)
-b BATCH_SIZE, --batch-size BATCH_SIZE
batch size
-e EPOCH, --epoch EPOCH
the number of epoch
--max-length MAX_LENGTH
max length of language model
--use-auth-token Huggingface transformers argument of `use_auth_token`
--dataset-split-train DATASET_SPLIT_TRAIN
dataset split to be used for training ('train' as default)
--dataset-split-valid DATASET_SPLIT_VALID
dataset split to be used for validation ('validation' as default)
--lr LR [LR ...] learning rate
--random-seed RANDOM_SEED [RANDOM_SEED ...]
random seed
-g GRADIENT_ACCUMULATION_STEPS [GRADIENT_ACCUMULATION_STEPS ...], --gradient-accumulation-steps GRADIENT_ACCUMULATION_STEPS [GRADIENT_ACCUMULATION_STEPS ...]
the number of gradient accumulation
--weight-decay WEIGHT_DECAY [WEIGHT_DECAY ...]
coefficient of weight decay (set 0 for None)
--lr-warmup-step-ratio LR_WARMUP_STEP_RATIO [LR_WARMUP_STEP_RATIO ...]
linear warmup ratio of learning rate (no decay).eg) if it's 0.3, the learning rate will warmup linearly till 30% of the total step
(set 0 for None)
--max-grad-norm MAX_GRAD_NORM [MAX_GRAD_NORM ...]
norm for gradient clipping (set 0 for None)
--crf CRF [CRF ...] use CRF on top of output embedding (0 or 1)
--optimizer-on-cpu put optimizer on CPU to save memory of GPU
--n-max-config N_MAX_CONFIG
the number of configs to run 2nd phase search
--epoch-partial EPOCH_PARTIAL
the number of epoch for 1st phase search
--max-length-eval MAX_LENGTH_EVAL
max length of language model at evaluation
```
- Example
```shell
tner-train-search -m "roberta-large" -c "ckpt" -d "tner/wnut2017" -e 15 --epoch-partial 5 --n-max-config 3 -b 64 -g 1 2 --lr 1e-6 1e-5 --crf 0 1 --max-grad-norm 0 10 --weight-decay 0 1e-7
```
## Evaluating NER Model
Evaluation of NER models is done by `model.evaluate` function that takes `dataset` or `local_dataset` as the dataset to evaluate on.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-wnut2017") # provide model alias on huggingface
# huggingface dataset
metric = model.evaluate('tner/wnut2017', dataset_split='test')
# local dataset
metric = model.evaluate(local_dataset={"test": "examples/local_dataset_sample/test.txt"}, dataset_split='test')
```
An example of the output object `metric` can be found [here](https://huggingface.co/tner/deberta-v3-large-wnut2017/raw/main/eval/metric.json).
### entity span prediction
For better understanding of out-of-domain accuracy, we provide the entity span prediction
pipeline, which ignores the entity type and compute metrics only on the IOB entity position (binary sequence labeling).
```python
metric = model.evaluate(datasets='tner/wnut2017', dataset_split='test', span_detection_mode=True)
```
### Command line tool
Following command-line tool is available for model prediction.
```shell script
tner-evaluate [-h] -m MODEL -e EXPORT [-d DATASET [DATASET ...]] [-l LOCAL_DATASET [LOCAL_DATASET ...]]
[--dataset-name DATASET_NAME [DATASET_NAME ...]] [--dataset-split DATASET_SPLIT] [--span-detection-mode] [--return-ci] [-b BATCH_SIZE]
Evaluate NER model
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
model alias of huggingface or local checkpoint
-e EXPORT, --export EXPORT
file to export the result
-d DATASET [DATASET ...], --dataset DATASET [DATASET ...]
dataset name (or a list of it) on huggingface tner organization eg. 'tner/conll2003' ['tner/conll2003', 'tner/ontonotes5']] see
https://huggingface.co/datasets?search=tner for full dataset list
-l LOCAL_DATASET [LOCAL_DATASET ...], --local-dataset LOCAL_DATASET [LOCAL_DATASET ...]
a dictionary (or a list) of paths to local BIO files eg.{"train": "examples/local_dataset_sample/train.txt", "test":
"examples/local_dataset_sample/test.txt"}
--dataset-name DATASET_NAME [DATASET_NAME ...]
[optional] data name of huggingface dataset (should be same length as the `dataset`)
--dataset-split DATASET_SPLIT
dataset split to be used for test ('test' as default)
--span-detection-mode
return F1 of entity span detection (ignoring entity type error and cast as binary sequence classification as below)- NER : ["O",
"B-PER", "I-PER", "O", "B-LOC", "O", "B-ORG"]- Entity-span detection: ["O", "B-ENT", "I-ENT", "O", "B-ENT", "O", "B-ENT"]
--return-ci return confidence interval by bootstrap
-b BATCH_SIZE, --batch-size BATCH_SIZE
batch size
```
- Example
```shell
tner-evaluate -m "tner/roberta-large-wnut2017" -e "metric.json" -d "tner/conll2003" -b "32"
```
## Reference
If you use any of these resources, please cite the following [paper](https://aclanthology.org/2021.eacl-demos.7/):
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```