https://github.com/ashishpatel26/tcn-keras-examples
This repository contains example of keras-tcn on easy way.
https://github.com/ashishpatel26/tcn-keras-examples
keras keras-tcn keras-tensorflow neuralnetwork sequence-to-sequence tcn temporal-convolution-network tensorflow-tcn time-series
Last synced: 3 months ago
JSON representation
This repository contains example of keras-tcn on easy way.
- Host: GitHub
- URL: https://github.com/ashishpatel26/tcn-keras-examples
- Owner: ashishpatel26
- License: mit
- Created: 2020-09-14T12:56:00.000Z (about 5 years ago)
- Default Branch: master
- Last Pushed: 2020-09-15T13:32:59.000Z (about 5 years ago)
- Last Synced: 2025-04-02T17:52:57.679Z (8 months ago)
- Topics: keras, keras-tcn, keras-tensorflow, neuralnetwork, sequence-to-sequence, tcn, temporal-convolution-network, tensorflow-tcn, time-series
- Language: Jupyter Notebook
- Homepage:
- Size: 298 KB
- Stars: 57
- Watchers: 2
- Forks: 14
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# TCN Keras Examples
### TCN Example Notebooks by Topic
***Note : This All Notebook Contains Step by Step code of TCN in different domain Application.***
#### Installation
```python
pip install keras-tcn
```
---
| Topic | Github | Colab |
| -------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| MNIST Dataset | [MNIST Dataset](https://github.com/ashishpatel26/tcn-keras-Examples/blob/master/TCN_MNIST.ipynb) | [](https://colab.research.google.com/github/ashishpatel26/tcn-keras-Examples/blob/master/TCN_MNIST.ipynb) |
| IMDB Dataset | [IMDA Dataset](https://github.com/ashishpatel26/tcn-keras-Examples/blob/master/TCN_IMDB.ipynb) | [](https://colab.research.google.com/github/ashishpatel26/tcn-keras-Examples/blob/master/TCN_IMDB.ipynb) |
| Time Series Dataset Milk | [Time Series Dataset Milk](https://github.com/ashishpatel26/tcn-keras-Examples/blob/master/TCN_TimeSeries_Approach.ipynb) | [](https://colab.research.google.com/github/ashishpatel26/tcn-keras-Examples/blob/master/TCN_TimeSeries_Approach.ipynb) |
| Many to Many Regression Approach | [MtoM Regression](https://colab.research.google.com/github/ashishpatel26/tcn-keras-Examples/blob/master/TCN_Many_to_Many_Regression.ipynb) | [](https://colab.research.google.com/github/ashishpatel26/tcn-keras-Examples/blob/master/TCN_Many_to_Many_Regression.ipynb) |
| Self Generated Dataset Approach | [Self Generated Dataset](https://github.com/ashishpatel26/tcn-keras-Examples/blob/master/TCN_Self_generated_Data_Training.ipynb) | [](https://colab.research.google.com/github/ashishpatel26/tcn-keras-Examples/blob/master/TCN_Self_generated_Data_Training.ipynb) |
| Cifar10 Image Classification | [Cifar10 Image Classification](https://github.com/ashishpatel26/tcn-keras-Examples/blob/master/TCN_cifar10.ipynb) | [](https://colab.research.google.com/github/ashishpatel26/tcn-keras-Examples/blob/master/TCN_cifar10.ipynb) |
Article : https://arxiv.org/pdf/1803.01271.pdf
github : https://github.com/philipperemy/keras-tcn
## Why Temporal Convolutional Network?
- TCNs exhibit longer memory than recurrent architectures with the same capacity.
- Constantly performs better than LSTM/GRU architectures on a vast range of tasks (Seq. MNIST, Adding Problem, Copy Memory, Word-level PTB...).
- Parallelism, flexible receptive field size, stable gradients, low memory requirements for training, variable length inputs...
[](https://github.com/philipperemy/keras-tcn/blob/master/misc/Dilated_Conv.png) **Visualization of a stack of dilated causal convolutional layers (Wavenet, 2016)**
### Arguments
```
TCN(nb_filters=64, kernel_size=2, nb_stacks=1, dilations=[1, 2, 4, 8, 16, 32], padding='causal', use_skip_connections=False, dropout_rate=0.0, return_sequences=True, activation='relu', kernel_initializer='he_normal', use_batch_norm=False, **kwargs)
```
- `nb_filters`: Integer. The number of filters to use in the convolutional layers. Would be similar to `units` for LSTM.
- `kernel_size`: Integer. The size of the kernel to use in each convolutional layer.
- `dilations`: List. A dilation list. Example is: [1, 2, 4, 8, 16, 32, 64].
- `nb_stacks`: Integer. The number of stacks of residual blocks to use.
- `padding`: String. The padding to use in the convolutions. 'causal' for a causal network (as in the original implementation) and 'same' for a non-causal network.
- `use_skip_connections`: Boolean. If we want to add skip connections from input to each residual block.
- `return_sequences`: Boolean. Whether to return the last output in the output sequence, or the full sequence.
- `dropout_rate`: Float between 0 and 1. Fraction of the input units to drop.
- `activation`: The activation used in the residual blocks o = activation(x + F(x)).
- `kernel_initializer`: Initializer for the kernel weights matrix (Conv1D).
- `use_batch_norm`: Whether to use batch normalization in the residual layers or not.
- `kwargs`: Any other arguments for configuring parent class Layer. For example "name=str", Name of the model. Use unique names when using multiple TCN.
### Input shape
3D tensor with shape `(batch_size, timesteps, input_dim)`.
`timesteps` can be None. This can be useful if each sequence is of a different length: [Multiple Length Sequence Example](https://github.com/philipperemy/keras-tcn/blob/master/tasks/multi_length_sequences.py).
### Output shape
- if `return_sequences=True`: 3D tensor with shape `(batch_size, timesteps, nb_filters)`.
- if `return_sequences=False`: 2D tensor with shape `(batch_size, nb_filters)`.
### Supported task types
- Regression (Many to one) e.g. adding problem
- Classification (Many to many) e.g. copy memory task
- Classification (Many to one) e.g. sequential mnist task
For a Many to Many regression, a cheap fix for now is to change the [number of units of the final Dense layer](https://github.com/philipperemy/keras-tcn/blob/8151b4a87f906fd856fd1c113c48392d542d0994/tcn/tcn.py#L90).
### Receptive field
- Receptive field = **nb_stacks_of_residuals_blocks \* kernel_size \* last_dilation**.
- If a TCN has only one stack of residual blocks with a kernel size of 2 and dilations [1, 2, 4, 8], its receptive field is 2 * 1 * 8 = 16. The image below illustrates it:
[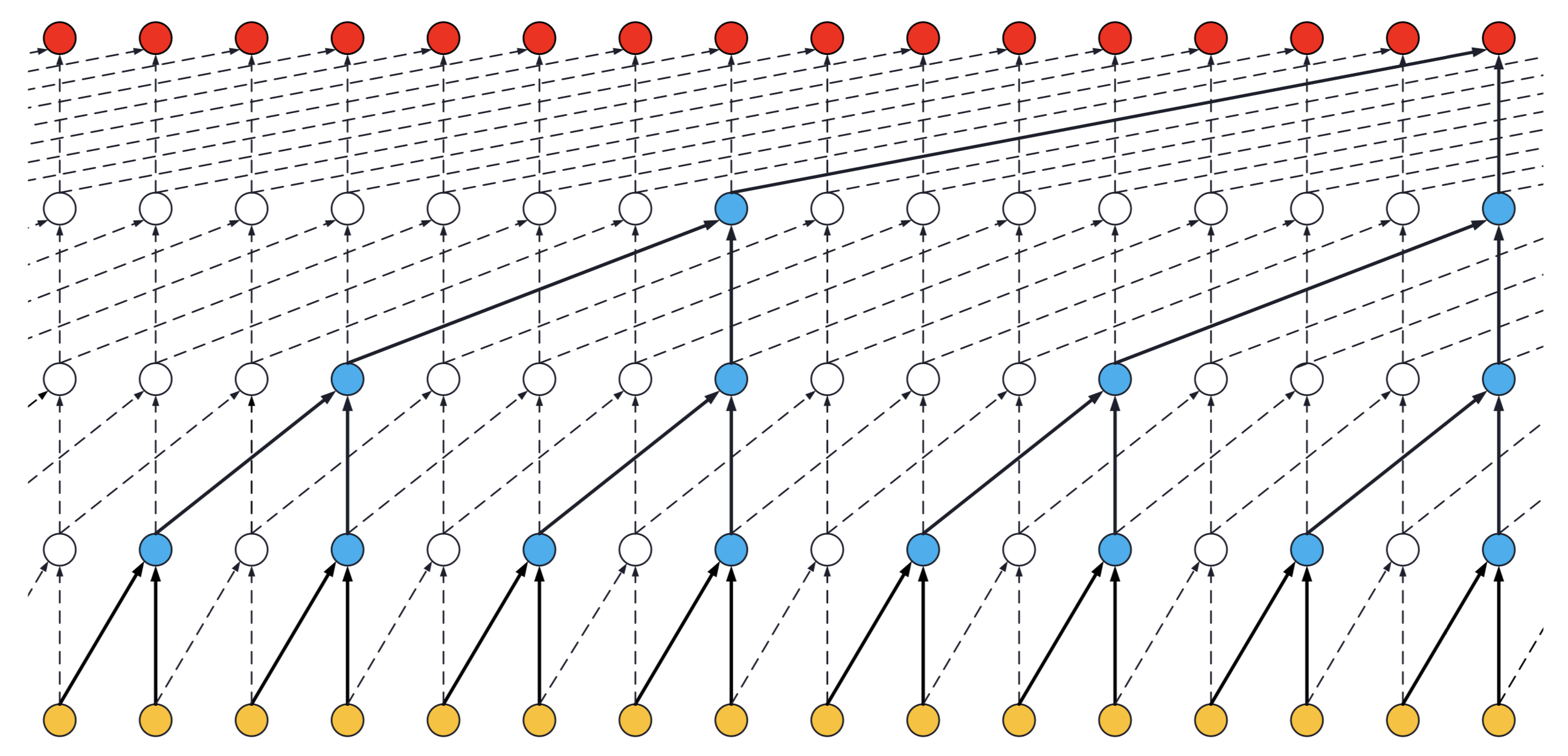](https://user-images.githubusercontent.com/40159126/41830054-10e56fda-7871-11e8-8591-4fa46680c17f.png) **ks = 2, dilations = [1, 2, 4, 8], 1 block**
- If the TCN has now 2 stacks of residual blocks, wou would get the situation below, that is, an increase in the receptive field to 32:
[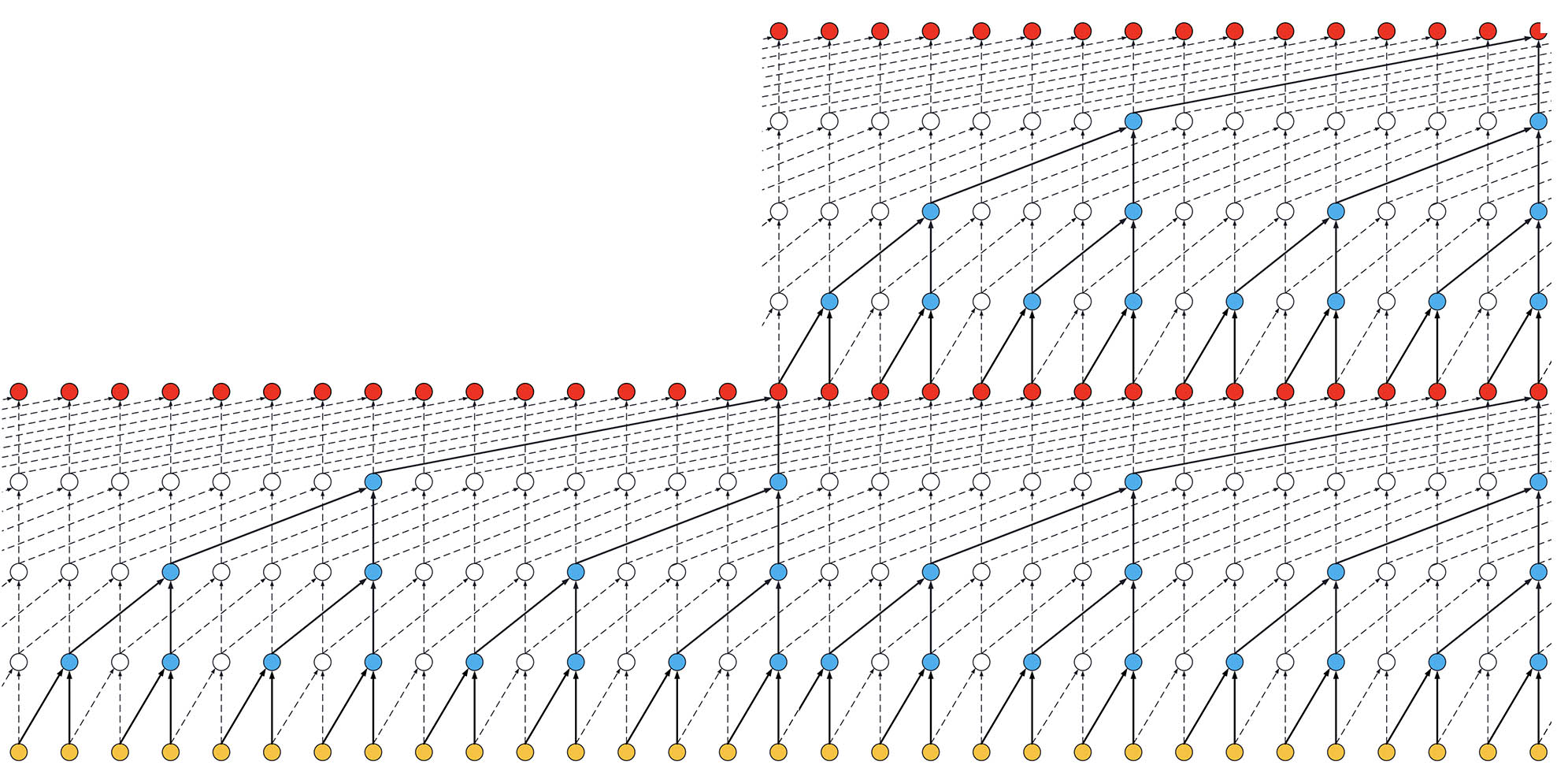](https://user-images.githubusercontent.com/40159126/41830618-a8f82a8a-7874-11e8-9d4f-2ebb70a31465.jpg) **ks = 2, dilations = [1, 2, 4, 8], 2 blocks**
- If we increased the number of stacks to 3, the size of the receptive field would increase again, such as below:
[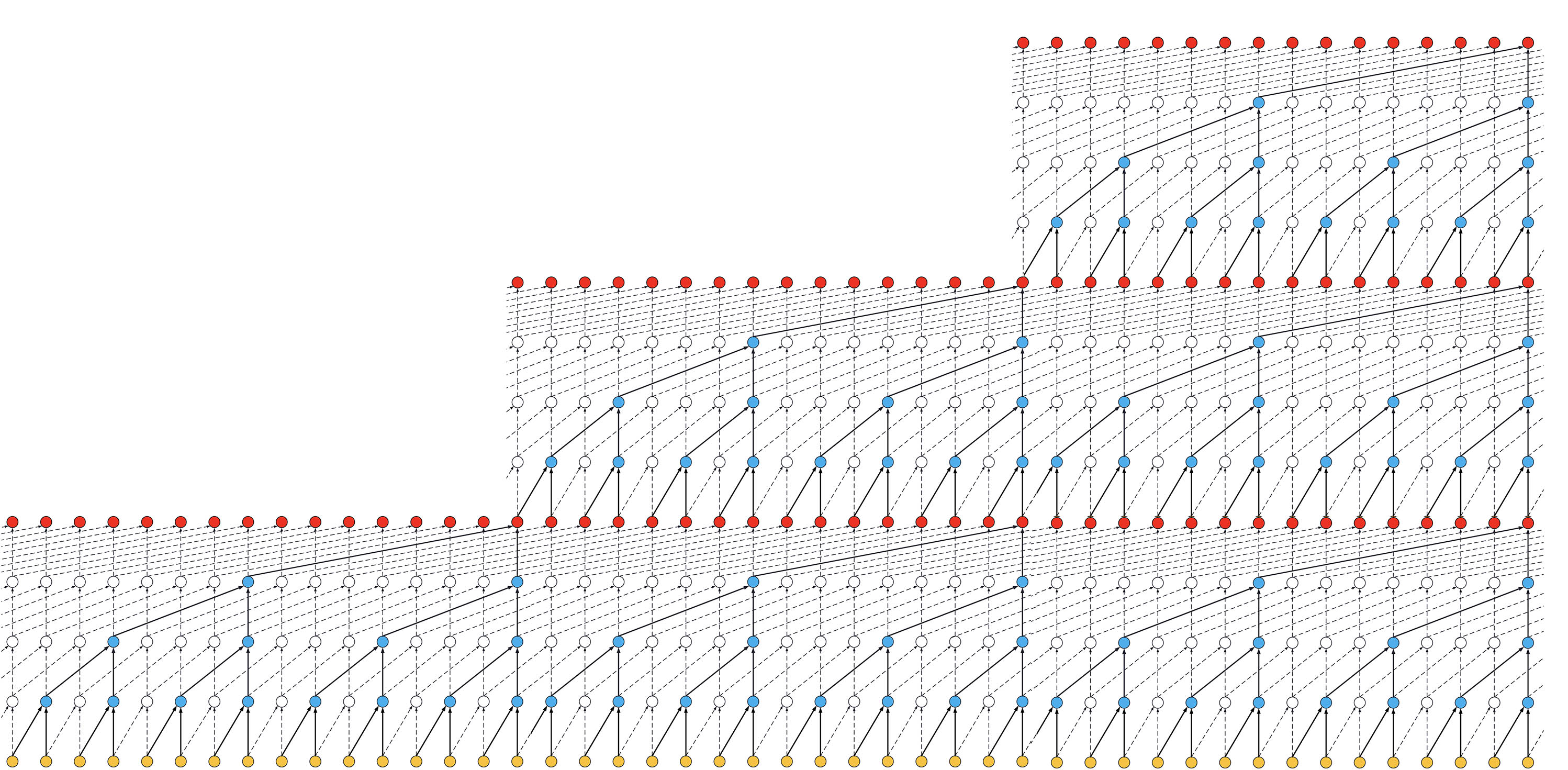](https://user-images.githubusercontent.com/40159126/41830628-ae6e73d4-7874-11e8-8ecd-cea37efa33f1.jpg) **ks = 2, dilations = [1, 2, 4, 8], 3 blocks**
Thanks to [@alextheseal](https://github.com/alextheseal) for providing such visuals.
### Non-causal TCN
Making the TCN architecture non-causal allows it to take the future into consideration to do its prediction as shown in the figure below.
However, it is not anymore suitable for real-time applications.
[](https://github.com/philipperemy/keras-tcn/blob/master/misc/Non_Causal.png) **Non-Causal TCN - ks = 3, dilations = [1, 2, 4, 8], 1 block**
To use a non-causal TCN, specify `padding='valid'` or `padding='same'` when initializing the TCN layers.
---
#### References:
- https://github.com/philipperemy/keras-tcn ( TCN Keras Version)
- https://github.com/locuslab/TCN/ (TCN for Pytorch)
- https://arxiv.org/pdf/1803.01271.pdf (An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling)
- https://arxiv.org/pdf/1609.03499.pdf (Original Wavenet paper)
- ***Note : All the rights reserved by original Author. This Repository creation intense for Educational purpose only.***