https://github.com/awikramanayake/lmu-parallel-hpc
A repository for my 'Parallel and High Performance Computing' course
https://github.com/awikramanayake/lmu-parallel-hpc
Last synced: 4 months ago
JSON representation
A repository for my 'Parallel and High Performance Computing' course
- Host: GitHub
- URL: https://github.com/awikramanayake/lmu-parallel-hpc
- Owner: AWikramanayake
- Created: 2023-11-05T17:42:26.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2024-07-09T21:40:13.000Z (about 1 year ago)
- Last Synced: 2025-01-29T09:36:22.790Z (6 months ago)
- Language: C
- Homepage:
- Size: 1.86 MB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# LMU-Parallel-HPC
A repository for code for my 'Parallel and High Performance Computing' course. Experiments conducted so far:
1. Pipelined vs Non-Pipelined Loops
2. Cache Size
## Experiment 2: Optimizing for Cache Size
This experiment aims to study the impact of memory operations on computation time, specifically the performance penalty incurred when accessing higher latency memory (L1 -> L2 -> L3 -> main memory). This is done by performing the Schönauer vector triad benchmark, given by: A[i] = B[i] + C[i] * D[i] with increasingly large vectors. As higher latency memory is used, the time taken for memory operations dominates the overall process time, and we see drops of orders of magnitude in computation speed.
To remove other potential bottlenecks, this benchmark is run with aggressive optimization (-O3 -march=native) but steps are taken to avoid dead code elimination by the compiler which would invalidate the results.
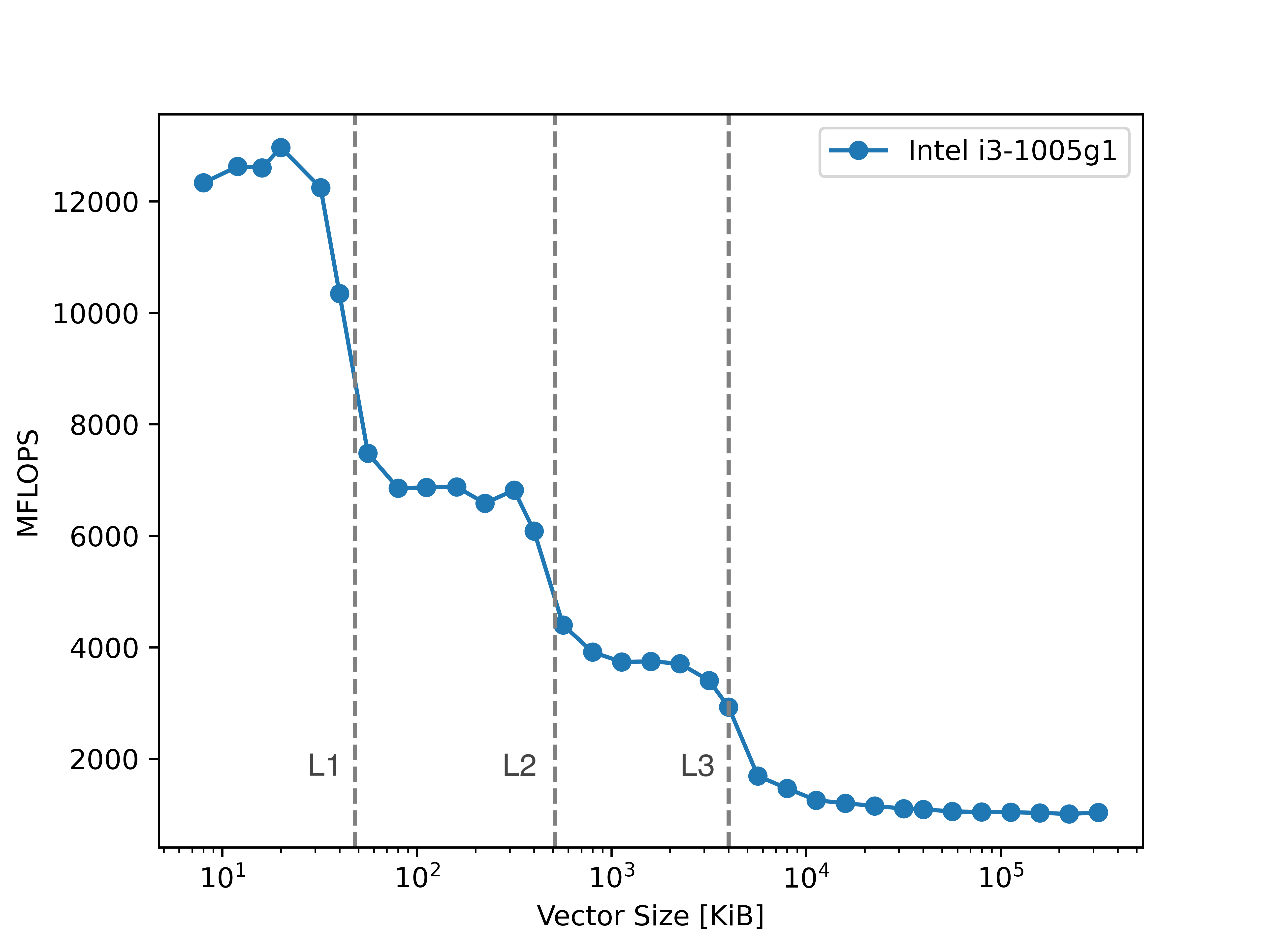
Fig 1: Triad results with Intel i3-1005g1
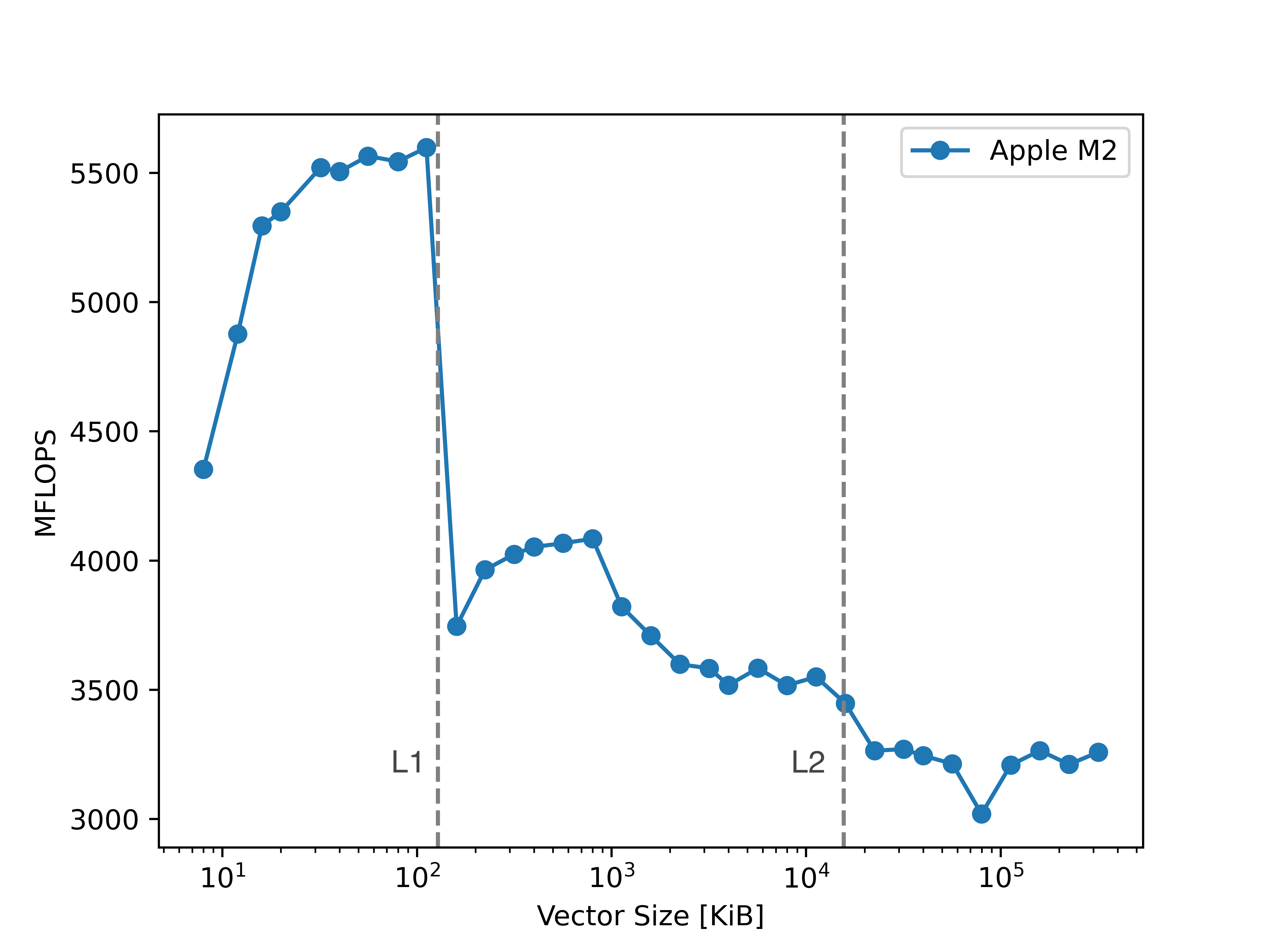
Fig 2: Triad results with Apple M2
As expected, we see a shard drop in computational efficiency whenever the vector size exceeds the size of one of the caches.
## Experiment 1: Pipelined vs. Non-pipelined Loops
The goal of this experiement is to study the performance improvements offered by [pipelining](https://cs.stanford.edu/people/eroberts/courses/soco/projects/risc/pipelining/index.html).
This is achieved by writing two loops that perform the same number of operations, but one is written with data hazards that prevent the compiler from pipelining the operations while the other has little to no hazards.
The loops are written in C and perform arithmetic operations (floating point addition, multiplication, division).
We use the flags
-O2 so that data does not need to be transferred from memory to registers at every step, ensuring that we only account for the time taken for the arithmetic operations and
-fno-tree-vectorize to stop the compiler from generating SIMD instructions so we can focus on scalar operations.
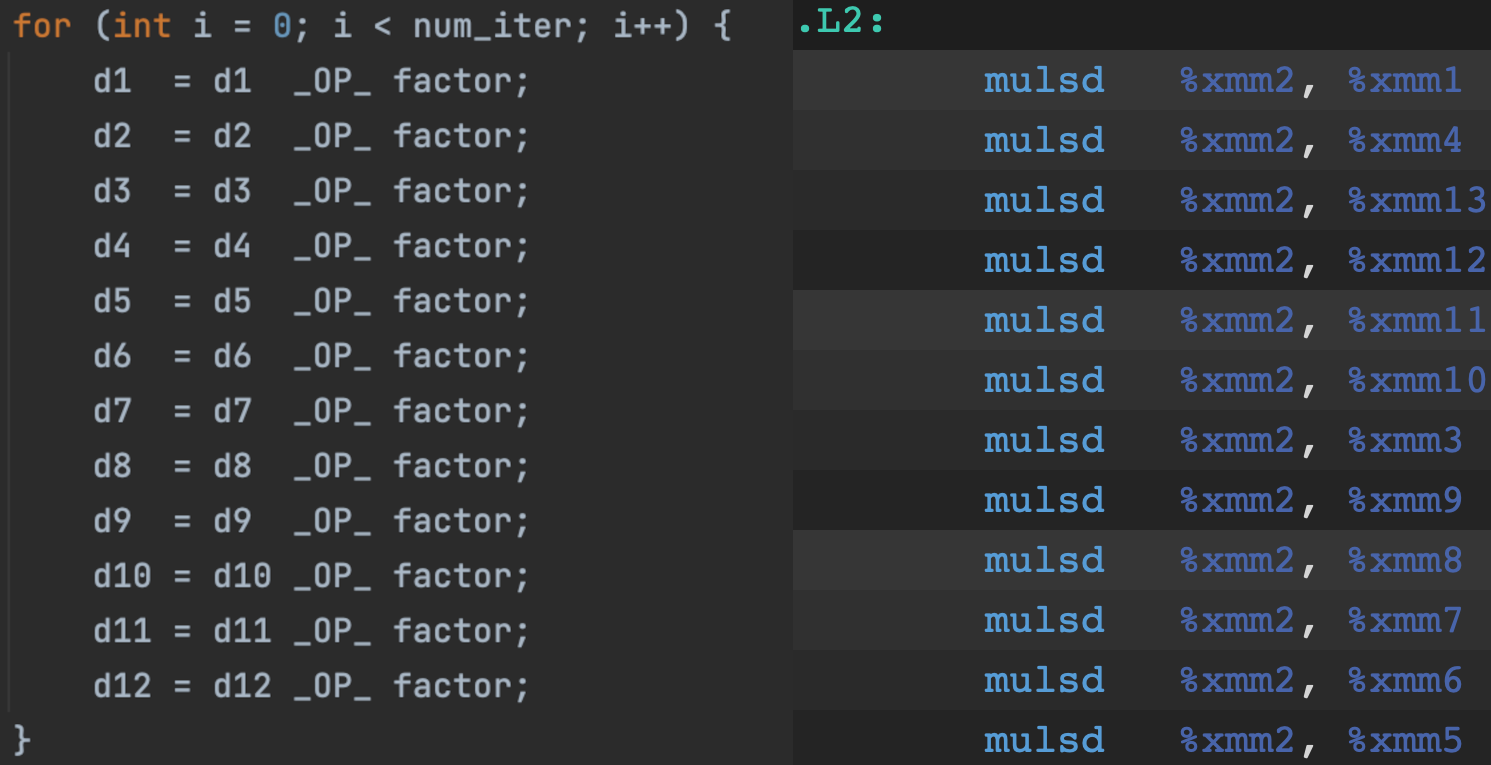
Fig 1: Loop with little to no data hazards that can be pipelined, and the corresponding assebly code
The locations on the right to which data is written are not referenced in subsequent lines, so these operations can be pipelined.
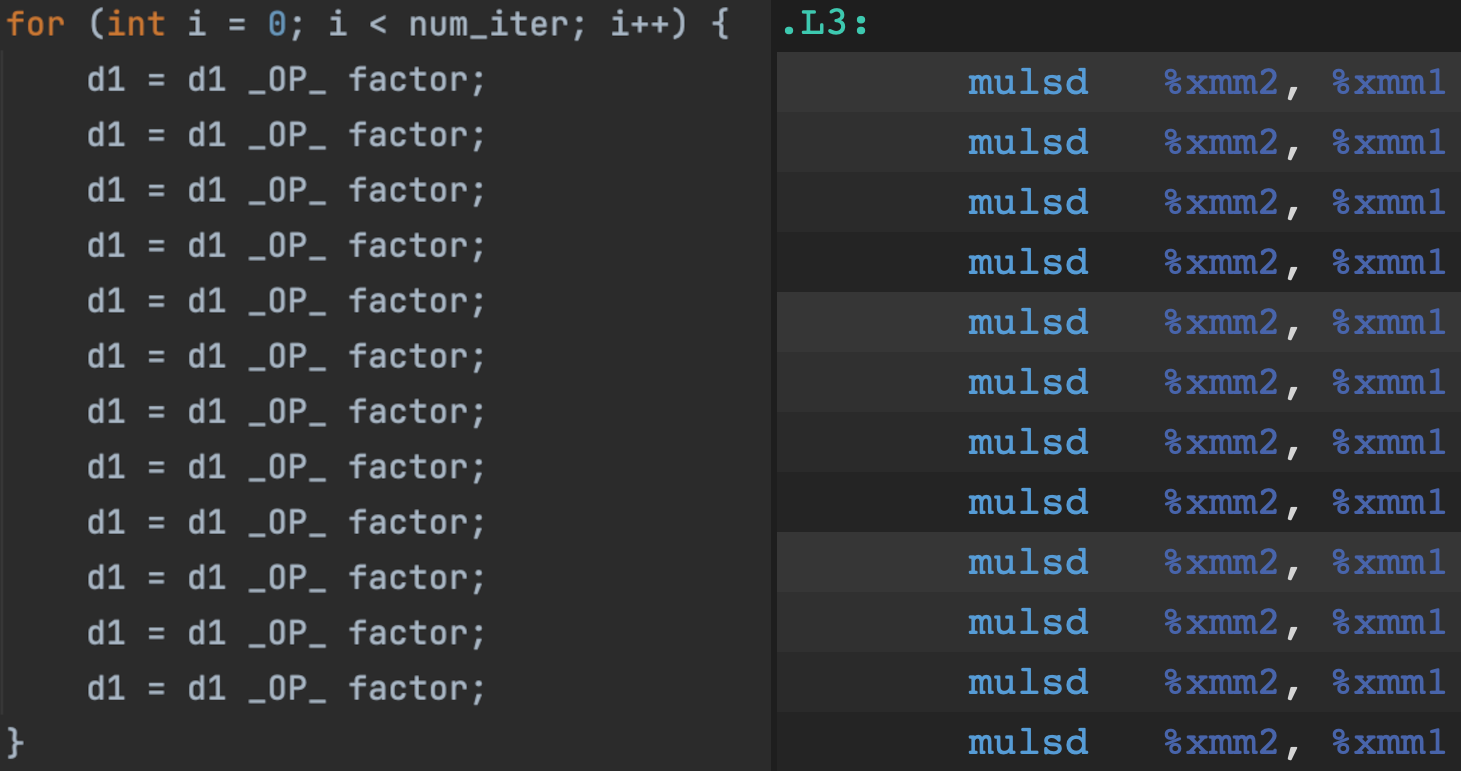
Fig 2: Loop with data hazards that cannot be pipelined, and the corresponding assebly code
Here the location to which data is written is referenced in each subsequent line, so these operations should not be pipelined by the compiler.
Due to issues with thread pinning (see below) and difficulties finding concrete documentation of the expected reciprocal throughput for Apple M2 processors (sadly they are not included in [Agner Fog's table (PDF)](https://www.agner.org/optimize/instruction_tables.pdf)), this experiment was done with an Intel i3-1005g1 (10th Gen/Ice Lake).
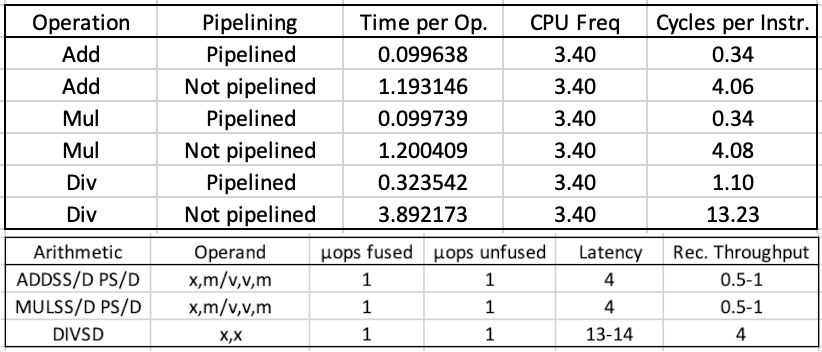
Fig 3: Top: Benchmark results. Bottom: Latency and reciprocal throughput for Ice Lake microarchitecture from Agner Fog's tables.
We clearly see that for non-pipelined operations, the cycles per instruction (top) correspond to the latency for that operation (bottom), just as expected for sequential operations. But what about the numbers for pipelined operations? Perhaps a look at the Sunny Cove core architecture will shed some light on these.
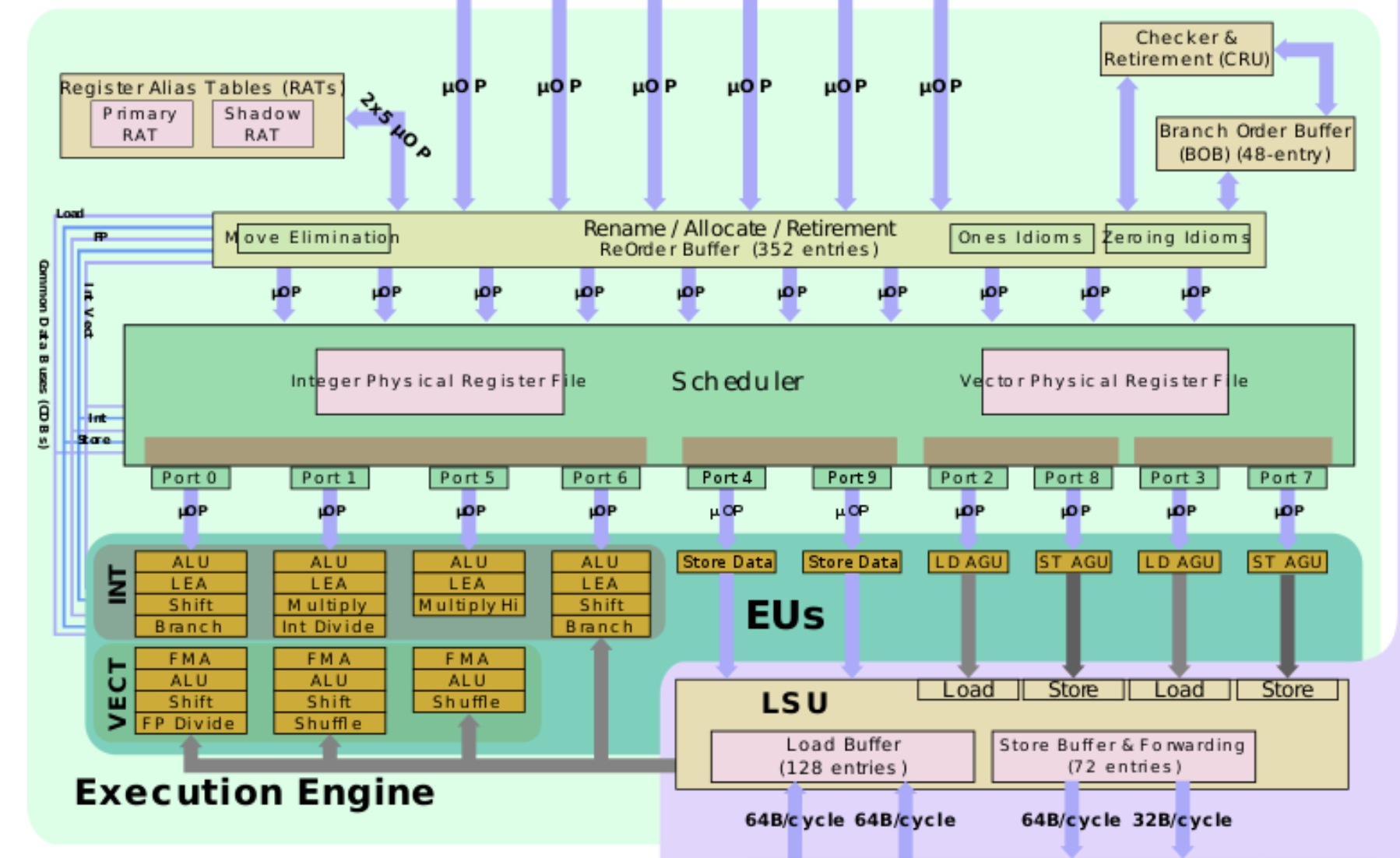
Fig 4: Sunny Cove architecture of the cores in the i3-1005g1 CPU. Source: wikichip.org
Looking at the very bottom left, we see that the Sunny Cove execution engine has 3 units that can handle FMA (fused multiply-add) and 1 that performs FP divide operations. This is possibly where the ~0.33 add/mul instructions per cycle (by performing 3 concurrently) and ~1 divide per cycle numbers for pipelined operations comes from.
### Issue: Thread pinning on Mac/OS X
Unlike linux, it appears OS X does not allow explicitly pinning a thread/process to a core (sched_setaffinity is not available). A partial solution presented [here](http://www.hybridkernel.com/2015/01/18/binding_threads_to_cores_osx.html) proposes a way to encourage the kernel to run given processes on different cores by assigning the processes different affinity tags, signalling to the kernel that they do not want to share L2 cache.
However, this method does not force a process to remain on a given core uninterrupted, which is verified by running this benchmark with and without tthis affinity policy fix.
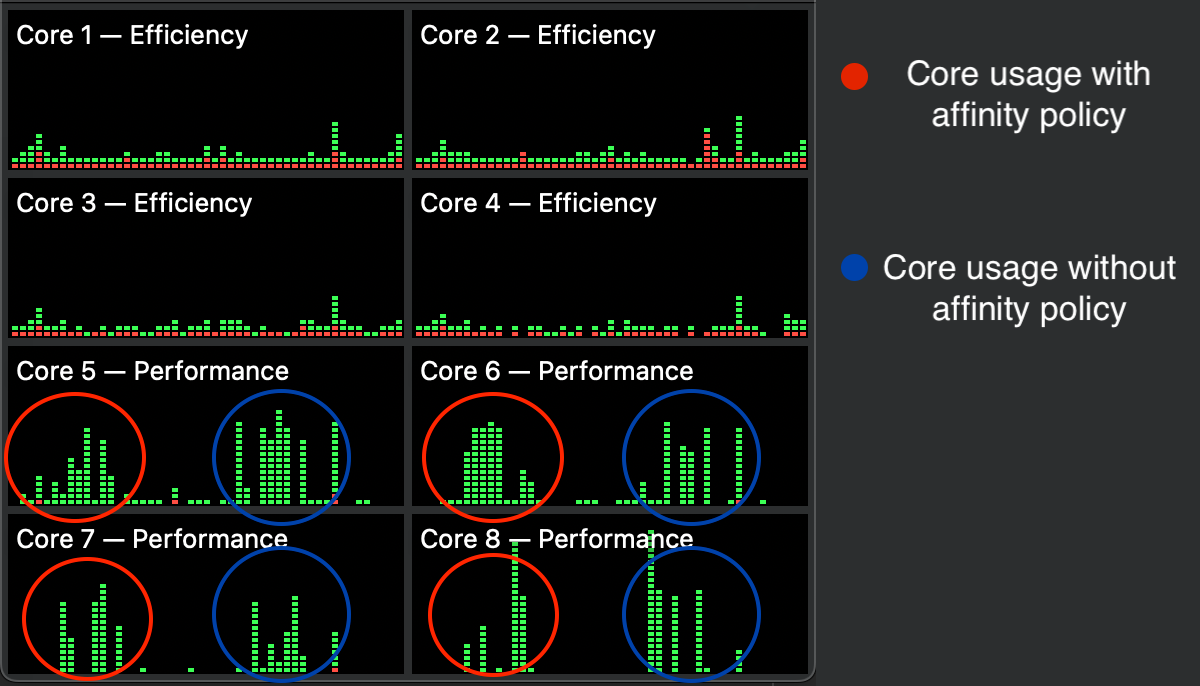
Fig 5: Core usage on Apple M2 while running the benchmark with and without the affinity policy fix
Clearly the affinity policy does not pin the process to a single core as all the performance cores are engaged during the benchmark regardless of whether the affinity tag fix is implemented or not. Nevertheless, this fix can be used later for other benchmarks exploring other implementations of parallelism.