https://github.com/awsaf49/gcvit-tf
Tensorflow 2.0 Implementation of GCViT: Global Context Vision Transformer
https://github.com/awsaf49/gcvit-tf
attention cnn computer-vision image-classification image-recognition imagenet self-attention transformer
Last synced: 6 months ago
JSON representation
Tensorflow 2.0 Implementation of GCViT: Global Context Vision Transformer
- Host: GitHub
- URL: https://github.com/awsaf49/gcvit-tf
- Owner: awsaf49
- License: mit
- Created: 2022-07-16T18:26:22.000Z (almost 4 years ago)
- Default Branch: main
- Last Pushed: 2023-12-24T18:55:04.000Z (over 2 years ago)
- Last Synced: 2026-01-13T06:20:53.803Z (6 months ago)
- Topics: attention, cnn, computer-vision, image-classification, image-recognition, imagenet, self-attention, transformer
- Language: Jupyter Notebook
- Homepage:
- Size: 27.6 MB
- Stars: 27
- Watchers: 5
- Forks: 6
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
- Citation: CITATION.cff
Awesome Lists containing this project
README
GCViT: Global Context Vision Transformer






Tensorflow 2.0 Implementation of GCViT
This library implements GCViT using Tensorflow 2.0 specifically in tf.keras.Model manner to get PyTorch flavor.
## Update
* **15 Jan 2023** : `GCViTLarge` model added with ckpt.
* **3 Sept 2022** : Annotated [kaggle-notebook](https://www.kaggle.com/code/awsaf49/gcvit-global-context-vision-transformer) based on this project won [Kaggle ML Research Spotlight: August 2022](https://www.kaggle.com/discussions/general/349817).
* **19 Aug 2022** : This project got acknowledged by [Official](https://github.com/NVlabs/GCVit) repo [here](https://github.com/NVlabs/GCVit#third-party-implementations-and-resources)
## Paper Implementation & Explanation **
I have explained the GCViT paper in a Kaggle notebook **[GCViT: Global Context Vision Transformer](https://www.kaggle.com/code/awsaf49/gcvit-global-context-vision-transformer)**, which also includes a detailed implementation of the model from scratch. The notebook provides a comprehensive explanation of each part of the model, with intuition.
Do check it out, especially if you are interested in learning more about GCViT or implementing it yourself. Note that this notebook has won the **Kaggle ML Research Award 2022.**
## Model
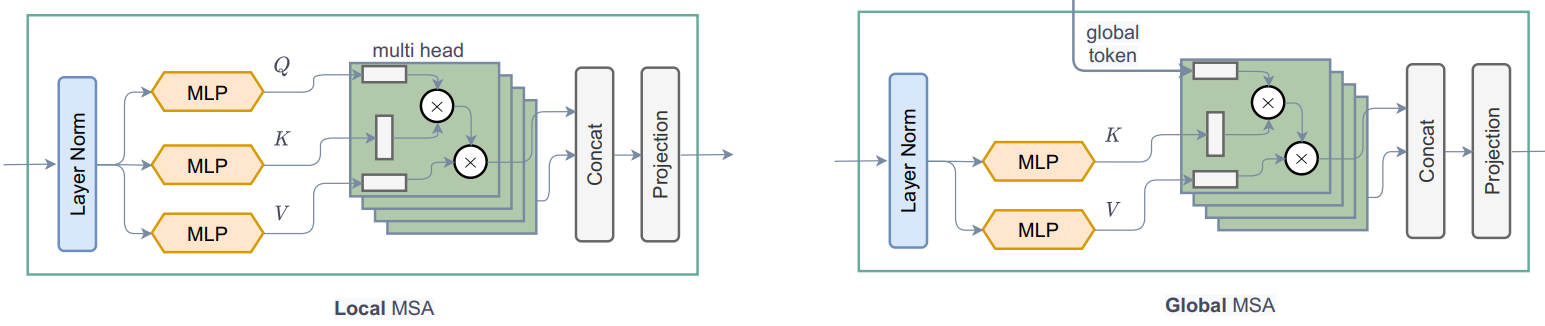
* Architecture:

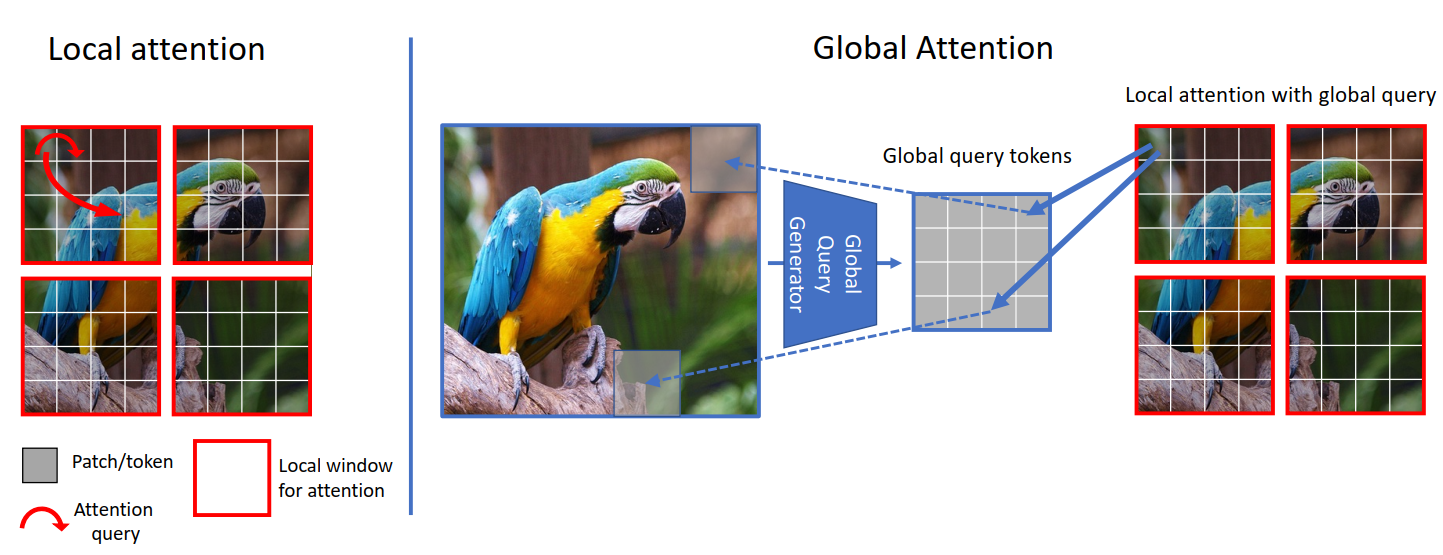
* Local Vs Global Attention:
## Result
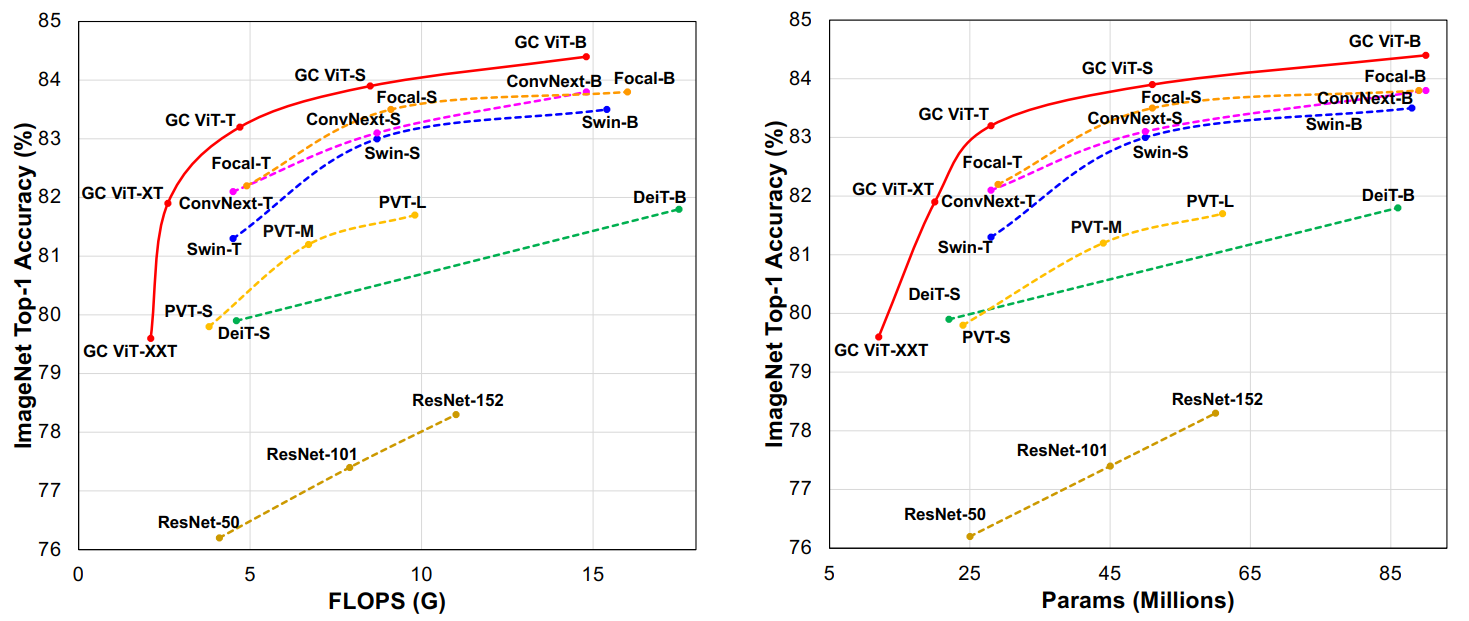
Official codebase had some issue which has been fixed recently (12 August 2022). Here's the result of ported weights on **ImageNetV2-Test** data,
| Model | Acc@1 | Acc@5 | #Params |
|--------------|-------|-------|---------|
| GCViT-XXTiny | 0.663 | 0.873 | 12M |
| GCViT-XTiny | 0.685 | 0.885 | 20M |
| GCViT-Tiny | 0.708 | 0.899 | 28M |
| GCViT-Small | 0.720 | 0.901 | 51M |
| GCViT-Base | 0.731 | 0.907 | 90M |
| GCViT-Large | 0.734 | 0.913 | 202M |
## Installation
```bash
pip install -U gcvit
# or
# pip install -U git+https://github.com/awsaf49/gcvit-tf
```
## Usage
Load model using following codes,
```py
from gcvit import GCViTTiny
model = GCViTTiny(pretrain=True)
```
Any input size other than **224x224**,
```py
from gcvit import GCViTTiny
model = GCViTTiny(input_shape=(512,512,3), pretrain=True, resize_query=True)
```
Simple code to check model's prediction,
```py
from skimage.data import chelsea
img = tf.keras.applications.imagenet_utils.preprocess_input(chelsea(), mode='torch') # Chelsea the cat
img = tf.image.resize(img, (224, 224))[None,] # resize & create batch
pred = model(img).numpy()
print(tf.keras.applications.imagenet_utils.decode_predictions(pred)[0])
```
Prediction:
```py
[('n02124075', 'Egyptian_cat', 0.9194835),
('n02123045', 'tabby', 0.009686623),
('n02123159', 'tiger_cat', 0.0061576385),
('n02127052', 'lynx', 0.0011503297),
('n02883205', 'bow_tie', 0.00042479983)]
```
For feature extraction:
```py
model = GCViTTiny(pretrain=True) # when pretrain=True, num_classes must be 1000
model.reset_classifier(num_classes=0, head_act=None)
feature = model(img)
print(feature.shape)
```
Feature:
```py
(None, 512)
```
For feature map:
```py
model = GCViTTiny(pretrain=True) # when pretrain=True, num_classes must be 1000
feature = model.forward_features(img)
print(feature.shape)
```
Feature map:
```py
(None, 7, 7, 512)
```
## Kaggle Models
These pre-trained models can also be loaded using [Kaggle Models](https://www.kaggle.com/models/awsaf49/gcvit-tf). Setting `from_kaggle=True` will enforce model to load weights from Kaggle Models without downloading, thus can be used without internet in Kaggle.
```py
from gcvit import GCViTTiny
model = GCViTTiny(pretrain=True, from_kaggle=True)
```
## Live-Demo
* For live demo on Image Classification & Grad-CAM, with **ImageNet** weights, click  powered by 🤗 Space and Gradio. here's an example,
powered by 🤗 Space and Gradio. here's an example,

## Example
For working training example checkout these notebooks on **Google Colab** & **Kaggle** .
Here is grad-cam result after training on Flower Classification Dataset,

## To Do
- [ ] Convert it to multi-backend `Keras 3.0`
- [ ] Segmentation Pipeline
- [x] Support for `Kaggle Models`
- [x] Remove `tensorflow_addons`
- [x] New updated weights have been added.
- [x] Working training example in Colab & Kaggle.
- [x] GradCAM showcase.
- [x] Gradio Demo.
- [x] Build model with `tf.keras.Model`.
- [x] Port weights from official repo.
- [x] Support for `TPU`.
## Acknowledgement
* [GCVit](https://github.com/NVlabs/GCVit) (Official)
* [Swin-Transformer-TF](https://github.com/rishigami/Swin-Transformer-TF)
* [tfgcvit](https://github.com/shkarupa-alex/tfgcvit/tree/develop/tfgcvit)
* [keras_cv_attention_models](https://github.com/leondgarse/keras_cv_attention_model)
## Citation
```bibtex
@article{hatamizadeh2022global,
title={Global Context Vision Transformers},
author={Hatamizadeh, Ali and Yin, Hongxu and Kautz, Jan and Molchanov, Pavlo},
journal={arXiv preprint arXiv:2206.09959},
year={2022}
}
```