https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet
This repository lets you train neural networks models for performing end-to-end full-page handwriting recognition using the Apache MXNet deep learning frameworks on the IAM Dataset.
https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet
Last synced: 7 months ago
JSON representation
This repository lets you train neural networks models for performing end-to-end full-page handwriting recognition using the Apache MXNet deep learning frameworks on the IAM Dataset.
- Host: GitHub
- URL: https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet
- Owner: awslabs
- License: apache-2.0
- Created: 2019-02-26T18:26:17.000Z (over 6 years ago)
- Default Branch: master
- Last Pushed: 2023-03-01T20:34:32.000Z (over 2 years ago)
- Last Synced: 2025-03-13T02:37:51.907Z (7 months ago)
- Language: Jupyter Notebook
- Size: 73 MB
- Stars: 500
- Watchers: 24
- Forks: 190
- Open Issues: 24
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
Awesome Lists containing this project
README
# Handwritten Text Recognition (OCR) with MXNet Gluon
## Local Setup
`git clone https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet --recursive`
You need to install SCLITE for WER evaluation
You can follow the following bash script from this folder:
```bash
cd ..
git clone https://github.com/usnistgov/SCTK
cd SCTK
export CXXFLAGS="-std=c++11" && make config
make all
make check
make install
make doc
cd -
```
You also need hsnwlib
```bash
pip install pybind11 numpy setuptools
cd ..
git clone https://github.com/nmslib/hnswlib
cd hnswlib/python_bindings
python setup.py install
cd ../..
```
if "AssertionError: Please enter credentials for the IAM dataset in credentials.json or as arguments" occurs rename credentials.json.example and to credentials.json with your username and password.
## Overview
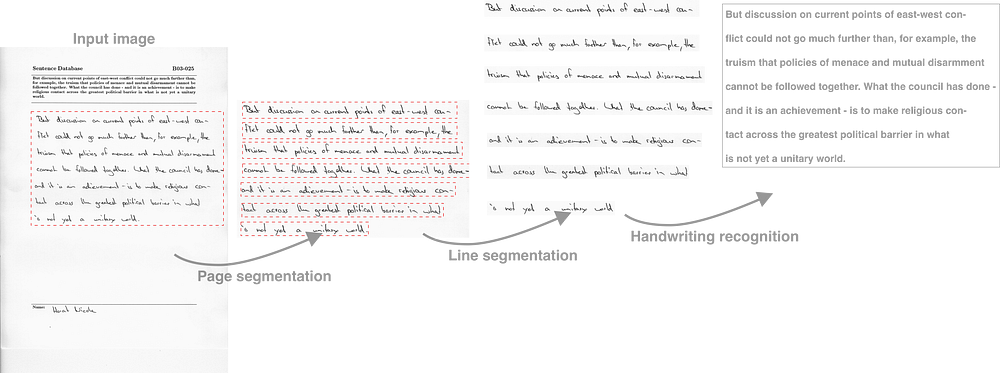
The pipeline is composed of 3 steps:
- Detecting the handwritten area in a form [[blog post](https://medium.com/apache-mxnet/page-segmentation-with-gluon-dcb4e5955e2)], [[jupyter notebook](https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet/blob/master/1_b_paragraph_segmentation_dcnn.ipynb)], [[python script](https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet/blob/master/ocr/scripts/paragraph_segmentation_dcnn.py)]
- Detecting lines of handwritten texts [[blog post](https://medium.com/apache-mxnet/handwriting-ocr-line-segmentation-with-gluon-7af419f3a3d8)], [[jupyter notebook](https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet/blob/master/2_line_word_segmentation.ipynb)], [[python script](https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet/blob/master/word_and_line_segmentation.py)]
- Recognising characters and applying a language model to correct errors. [[blog post](https://medium.com/apache-mxnet/handwriting-ocr-handwriting-recognition-and-language-modeling-with-mxnet-gluon-4c7165788c67)], [[jupyter notebook](https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet/blob/master/3_handwriting_recognition.ipynb)], [[python script](https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet/blob/master/ocr/scripts/handwriting_line_recognition.py)]
The entire inference pipeline can be found in this [notebook](https://github.com/awslabs/handwritten-text-recognition-for-apache-mxnet/blob/master/0_handwriting_ocr.ipynb). See the *pretrained models* section for the pretrained models.
A recorded talk detailing the approach is available on youtube. [[video](https://www.youtube.com/watch?v=xDcOdif4lj0)]
The corresponding slides are available on slideshare. [[slides](https://www.slideshare.net/apachemxnet/ocr-with-mxnet-gluon)]
## Pretrained models:
You can get the models by running `python get_models.py`:
## Sample results

The greedy, lexicon search, and beam search outputs present similar and reasonable predictions for the selected examples. In Figure 6, interesting examples are presented. The first line of Figure 6 show cases where the lexicon search algorithm provided fixes that corrected the words. In the top example, “tovely” (as it was written) was corrected “lovely” and “woved” was corrected to “waved”. In addition, the beam search output corrected “a” into “all”, however it missed a space between “lovely” and “things”. In the second example, “selt” was converted to “salt” with the lexicon search output. However, “selt” was erroneously converted to “self” in the beam search output. Therefore, in this example, beam search performed worse. In the third example, none of the three methods significantly provided comprehensible results. Finally, in the forth example, the lexicon search algorithm incorrectly converted “forhim” into “forum”, however the beam search algorithm correctly identified “for him”.
## Dataset:
* To use test_iam_dataset.ipynb, create credentials.json using credentials.json.example and editing the appropriate field. The username and password can be obtained from http://www.fki.inf.unibe.ch/DBs/iamDB/iLogin/index.php.
* **It is recommended to use an instance with 32GB+ RAM and 100GB disk size, a GPU is also recommended. A p3.2xlarge would be the recommended starter instance on AWS for this project**
## Appendix
### 1) Handwritten area
##### Model architecture
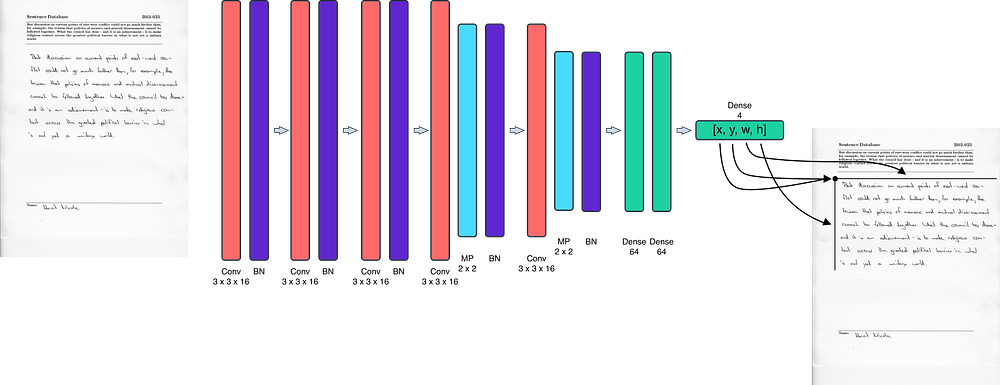
##### Results

### 2) Line Detection
##### Model architecture
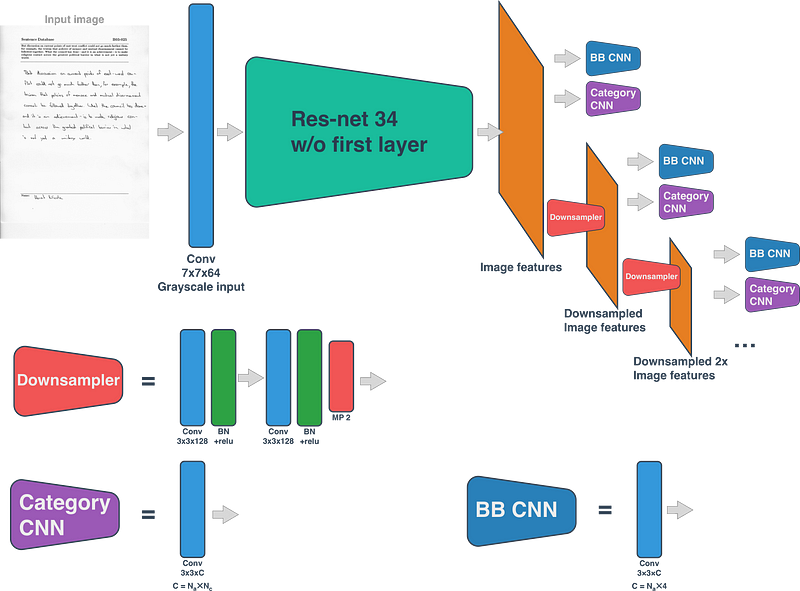
##### Results

### 3) Handwritten text recognition
##### Model architecture
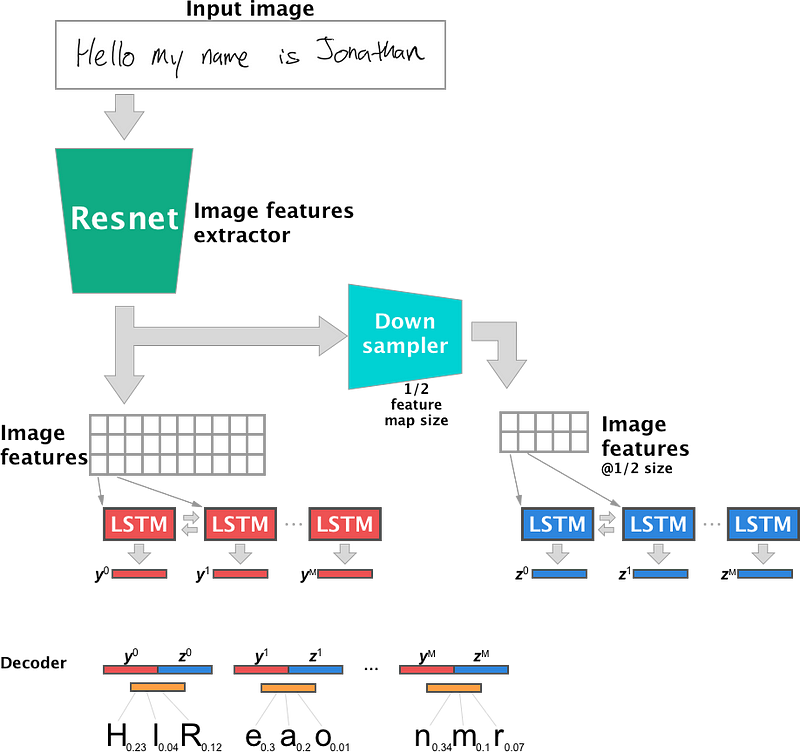
##### Results
