https://github.com/azat-io/token-limit
🛰 Monitor how many tokens your code and configs consume in AI tools. Set budgets and get alerts when limits are hit
https://github.com/azat-io/token-limit
ai chatgpt claude context tokens
Last synced: 10 months ago
JSON representation
🛰 Monitor how many tokens your code and configs consume in AI tools. Set budgets and get alerts when limits are hit
- Host: GitHub
- URL: https://github.com/azat-io/token-limit
- Owner: azat-io
- License: mit
- Created: 2025-07-01T18:19:16.000Z (11 months ago)
- Default Branch: main
- Last Pushed: 2025-07-20T21:24:15.000Z (11 months ago)
- Last Synced: 2025-08-03T16:42:08.704Z (10 months ago)
- Topics: ai, chatgpt, claude, context, tokens
- Language: TypeScript
- Homepage:
- Size: 535 KB
- Stars: 49
- Watchers: 1
- Forks: 1
- Open Issues: 1
-
Metadata Files:
- Readme: readme.md
- Changelog: changelog.config.ts
- Contributing: contributing.md
- License: license.md
- Code of conduct: .github/code_of_conduct.md
- Security: .github/security.md
Awesome Lists containing this project
README
# Token Limit

[](https://npmjs.com/package/token-limit)
[](https://npmjs.com/package/token-limit)
[](https://github.com/azat-io/token-limit/blob/main/license.md)
Token Limit helps you monitor how many tokens your AI context files consume. Set token budgets for your prompts, documentation, and configs, then get alerts when limits are exceeded.
Keep your AI costs predictable and avoid hitting context window limits that break your applications.
## Why
AI context files are becoming a standard part of modern development workflows. Projects now commonly include `.context/`, `CLAUDE.md`, `.clinerules`, `.cursorrules`, and other AI instruction files directly in their repositories.
As these files grow in size and complexity, it becomes crucial to monitor their token consumption to avoid unexpected API costs and context window limitations.
## Key Features
- **Multi-model support** for OpenAI GPT and Anthropic Claude
- **CI integration** to catch budget overruns in pull requests
- **Flexible configuration** for different AI use cases
- **Real token costs** instead of inaccurate file sizes
- **Cost budgets** in dollars and cents, not just tokens
- **Up-to-date pricing** from OpenRouter API instead of hardcoded values
###
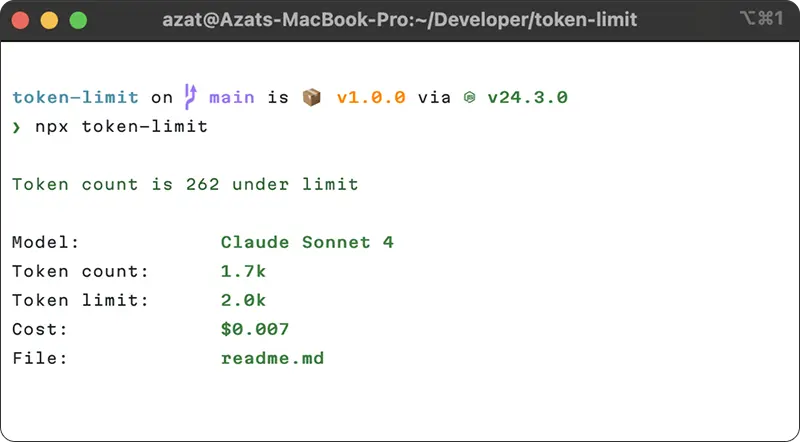
## How It Works
1. **Configure** your token budgets in `token-limit.config.ts`, `package.json`, or other supported formats
2. **Analyze** files using official tokenizers for each AI model (tiktoken, Anthropic)
3. **Report** which files exceed limits with detailed breakdowns
4. **Prevent** costly overruns by failing CI builds when budgets are exceeded
## Usage
### Quick Start
1. Install Token Limit:
```sh
npm install --save-dev token-limit
```
2. Create a configuration file (e.g., `token-limit.config.ts` or `.token-limit.json`):
```ts
// token-limit.config.ts
import { defineConfig } from 'token-limit'
export default defineConfig([
{
name: 'AI Context',
path: '.context/**/*.md',
limit: '100k',
model: 'gpt-4',
},
{
name: 'Documentation',
path: ['docs/**/*.md', 'docs/**/*.txt'],
limit: '$0.05',
model: 'claude-sonnet-4',
},
])
```
3. Add a script to your `package.json`:
```json
{
"scripts": {
"token-limit": "token-limit"
}
}
```
4. Run the analysis:
```sh
npm run token-limit
```
### Command Line Usage
You can also run Token Limit directly from the command line:
```sh
# Check specific files
npx token-limit README.md docs/guide.md
# Set limits and models
npx token-limit --limit 10k --model gpt-4 docs/**/*.md
# Set cost limits
npx token-limit --limit '$0.25' --model gpt-4 expensive-prompts/**/*.md
# Name your check
npx token-limit --name "API Docs" --limit 50k api-docs/**/*.md
# Multiple examples
npx token-limit .context/**/*.md
npx token-limit --limit 1000 claude.md
npx token-limit --limit '5c' --model gpt-3.5-turbo quick-prompts/*.txt
npx token-limit --json --hide-passed
```
## Configuration
Token Limit supports multiple configuration formats to suit your project needs. You can define token limits, models, and file paths in a variety of ways:
### Configuration Formats
- `token-limit.config.{ts,js,mjs,cjs}`
- `.token-limit.{ts,js,mjs,cjs,json}`
- `.token-limit`
- `package.json` (`token-limit` field)
- Command line arguments
### Supported Models
**OpenAI Models**
- `gpt-4.1`
- `gpt-4.1-mini`
- `gpt-4.1-nano`
- `gpt-4o`
- `gpt-4o-mini`
- `gpt-4-turbo`
- `gpt-4`
- `gpt-3.5-turbo`
- `o1`
- `o1-mini`
- `o3-mini`
**Anthropic Models**
- `claude-opus-4`
- `claude-opus-4.1`
- `claude-sonnet-4`
- `claude-3.7-sonnet`
- `claude-3.5-sonnet`
- `claude-3.5-haiku`
- `claude-3-opus`
### Limit Formats
**Token Limits**
- Numbers: `1000`, `50000`
- Human-readable: `"10k"`, `"1.5M"`, `"500K"`
**Cost Limits**
- Dollar amounts: `"$0.05"`, `"$1.50"`
- Cents: `"5c"`, `"10c"`
- Plain numbers: `0.05`, `1.5` (interpreted as dollars)
## CI Integration
### GitHub Actions Integration
Add Token Limit to your CI pipeline:
```yaml
# .github/workflows/token-limit.yml
name: Token Limit
on: [push, pull_request]
jobs:
token-limit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: '18'
- run: npx token-limit
```
## Why Token Limits Matter
Unlike traditional bundle size limits, token limits directly impact:
- **API Costs**: More tokens = higher bills (GPT-4 costs $0.03 per 1K tokens)
- **Response Quality**: Exceeding context windows truncates input (GPT-4: 128K limit)
- **Performance**: Larger contexts mean slower API responses
- **Reliability**: Context overflow can cause API errors
Token Limit helps you catch these issues before they reach production.
## Contributing
See [Contributing Guide](https://github.com/azat-io/token-limit/blob/main/contributing.md).
## License
MIT © [Azat S.](https://azat.io)