https://github.com/baderouaich/protobuf_fs_db
Filesystem based database for basic objects using protobuf
https://github.com/baderouaich/protobuf_fs_db
cplusplus cplusplus-20 cpp cpp20 database database-design databases efficiency filesystem filesystem-database fs protobuf
Last synced: 2 months ago
JSON representation
Filesystem based database for basic objects using protobuf
- Host: GitHub
- URL: https://github.com/baderouaich/protobuf_fs_db
- Owner: baderouaich
- Created: 2024-06-16T11:19:33.000Z (about 2 years ago)
- Default Branch: main
- Last Pushed: 2024-09-03T11:32:42.000Z (almost 2 years ago)
- Last Synced: 2025-02-21T19:27:08.554Z (over 1 year ago)
- Topics: cplusplus, cplusplus-20, cpp, cpp20, database, database-design, databases, efficiency, filesystem, filesystem-database, fs, protobuf
- Language: C++
- Homepage:
- Size: 44.9 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
## Protobuf Filesystem Database
Trying to have an alike solution that was mentioned in this [article](https://hivekit.io/blog/how-weve-saved-98-percent-in-cloud-costs-by-writing-our-own-database/).
This is a small implementation of a filesystem based database that uses google's [protobuf](https://github.com/protocolbuffers/protobuf)
to store objects directly to the disk using a C++ simple Database api class that provides methods
such as (add, update, remove, clear, exists, count, findIf, countIf, update, and more)
For example, if your database models are a User, a Download, and a Setting,
the database will be structured in the hierarchy below:
```txt
Database/
|_______Users/
|____ 1 --> binary file contains User object with id = 1
|____ 2
|____ 3
|_______Downloads/
|____ 1
|____ 2
|____ 3
|_______Settings/
|____ 1
|____ 2
|____ 3
```
Where each object MUST have an `id`, so the binary file where the object is stored can easily be accessed
by id, example for User object with id = 1: User{id = 1, ...}, we already know that the file will be located at:
`Database/Users/1` which will be fast to access (of course disk type impacts, ssd or nvme..).
To use this filesystem based database, each object must be defined in the `./proto/`folder, which you can include after building your project at least once so the
protobuf compiler will generate the header and source files.
The database uses a [mutex file](./MutexFile.hpp) to protect itself from multiple processes trying to write to the database at the same time, blocking the user if the database is already in use until its free then it allows the other user to proceed.
The database uses a threading mutex to protect itself from multiple threads trying to read/write to the database at the same time using an [std::shared_mutex](https://en.cppreference.com/w/cpp/thread/shared_mutex).
The [Database api](Database.hpp) allows you to manipulate your database in such way:
Example
```cpp
// Initialize the db
Database db("/path/to/your/Database/");
// Optionally set directory name where user objects will be saved
// The default naming will be the name was set to the protobuf objects example: "types.User"
// So in below case, User objects will be saved to Database/Users
db.typeDirName("Users");
db.typeDirName("Downloads");
db.typeDirName("Settings");
// Add a new User to the database
types::User user1;
user1.set_id(1000);
user1.set_name("James");
user1.set_weight(83.15);
db.add(user1);
// Update user1's weight to 85.0
user1.set_weight(85.0);
db.update(user1);
// Add a new Download to the database
types::Download download;
download.set_id(3000);
download.set_userid(user1.id()); // owner
download.set_timestamp(std::time(nullptr));
download.set_url("https://youtube.com/some/video");
download.set_size(1024*1024*500);
download.set_success(true);
db.add(download);
// Print the count of Users and Downloads saved in the db
std::cout << db.count() << " users\n";
std::cout << db.count() << " downloads\n";
// Count users with weight > 80.0
std::size_t count = db.countIf([](const types::User& user) {
return user.weight() > 80.0;
});
std::cout << "There are " << count << " Users with weight over 80.0.\n";
// Remove users with even id
bool ok = db.removeIf([](const types::User& user) {
return user.id() % 2 == 0;
});
assert(ok);
// Remove all objects from database
db.clear();
db.clear();
db.clear();
```
## Inspiration
[This article](https://hivekit.io/blog/how-weve-saved-98-percent-in-cloud-costs-by-writing-our-own-database/)
A Company have saved 98% in cloud costs by writing their own database.
They created a purpose built, in process storage engine that’s part of the same executable as their core server.
It writes a minimal, delta based binary format. A single entry looks like this:
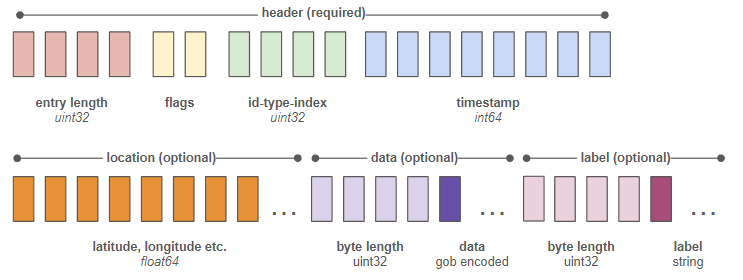
The result: A 98% reduction in cloud cost and faster everything
Of course, this is not general, some databases are too sophisticated that require a real database engine such as Microsoft SQL Server, Oracle Database, MySQL, Postgres... but this company is storing simple data structure and
they realized they can do better than paying thousands of dollars in AWS Aurora with the PostGIS extension for geospatial data storage.