Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/bangoc123/transformer
Build English-Vietnamese machine translation with ProtonX Transformer. :D
https://github.com/bangoc123/transformer
machine-translation tensorflow2 transformer
Last synced: 3 months ago
JSON representation
Build English-Vietnamese machine translation with ProtonX Transformer. :D
- Host: GitHub
- URL: https://github.com/bangoc123/transformer
- Owner: bangoc123
- Created: 2021-06-22T03:09:54.000Z (over 3 years ago)
- Default Branch: master
- Last Pushed: 2021-09-13T11:44:01.000Z (over 3 years ago)
- Last Synced: 2024-11-02T02:23:03.366Z (4 months ago)
- Topics: machine-translation, tensorflow2, transformer
- Language: Python
- Homepage:
- Size: 55.7 KB
- Stars: 64
- Watchers: 4
- Forks: 21
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# ProtonX Transformer

Design Machine Translation Engine for Vietnamese using Transformer Architecture from paper [Attention Is All You Need](https://arxiv.org/pdf/1706.03762.pdf). Give us a star if you like this repo.
Model Explanation:
- Slide:
- Transformer Encoder: Check out [here](https://drive.google.com/file/d/182rTpgUdTjDgw4LrAM6ah2B_Iw_4rXQW/view?usp=sharing)
- Transformer Decoder (Updating)
Author:
- Github: bangoc123
- Email: [email protected]
This library belongs to our project: [Papers-Videos-Code](https://docs.google.com/document/d/1bjmwsYFafizRXlZyJFazd5Jcr3tqpWSiHLvfllWRQBc/edit?usp=sharing) where we will implement AI SOTA papers and publish all source code. Additionally, videos to explain these models will be uploaded to [ProtonX Youtube](https://www.youtube.com/c/ProtonX/videos) channels.
Architecture:
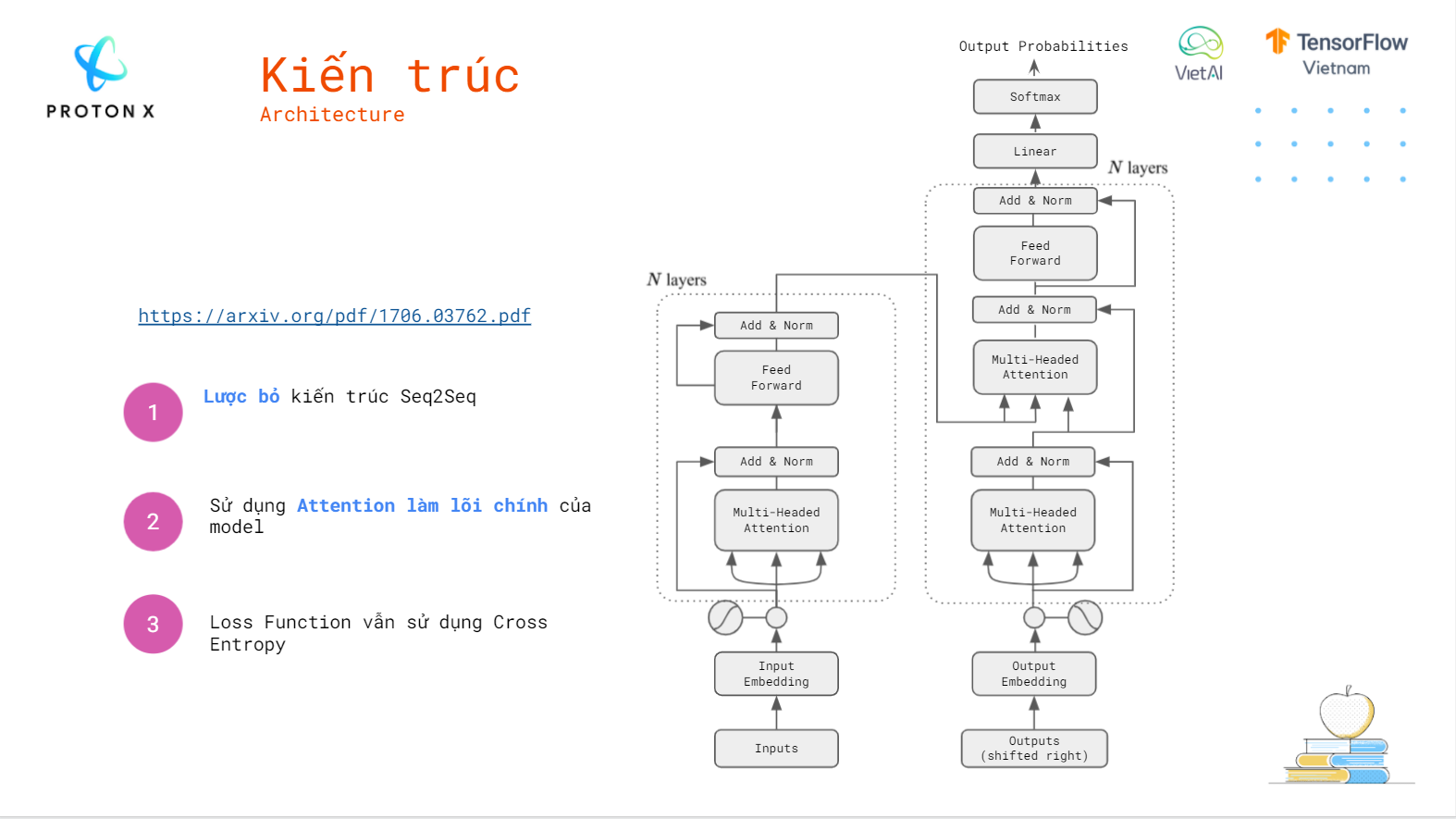
**[Note] You can use your data to train this model.**
### I. Set up environment
1. Make sure you have installed Miniconda. If not yet, see the setup document [here](https://conda.io/en/latest/user-guide/install/index.html#regular-installation).
2. `cd` into `transformer` and use command line `conda env create -f environment.yml` to set up the environment
3. Run conda environment using the command `conda activate transformer`
### II. Set up your dataset.
Design train dataset with 2 files:
- train.en
- train.vi
For example:
| train.en | train.vi |
|----------|:-------------:|
| I love you | Tôi yêu bạn|
| ... | .... |
You can see mocking data in `./data/mock` folder.
### III. Train your model by running this command line
Training script:
```bash
python train.py --epochs ${epochs} --input-lang en --target-lang vi --input-path ${path_to_en_text_file} --target-path ${path_to_vi_text_file}
```
Example: You want to build English-Vietnamese machine translation in 10 epochs
```bash
python train.py --epochs 10 --input-lang en --target-lang vi --input-path ./data/mock/train.en --target-path ./data/mock/train.vi
```
There are some `important` arguments for the script you should consider when running it:
- `input-lang`: The name of the input language (E.g. en)
- `target-lang`: The name of the target language (E.g. vi)
- `input-path`: The path of the input text file (E.g. ./data/mock/train.en)
- `target-path`: The path of the output text file (E.g. ./data/mock/train.vi)
- `model-folder`: Saved model path
- `vocab-folder`: Saved tokenizer + vocab path
- `batch-size`: The batch size of the dataset
- `max-length`: The maximum length of a sentence you want to keep when preprocessing
- `num-examples`: The number of lines you want to train. It was set small if you want to experiment with this library quickly.
- `d-model`: The dimension of linear projection for all sentence. It was mentioned in Section `3.2.2 ` on the [page 5](https://arxiv.org/pdf/1706.03762.pdf)
- `n`: The number of Encoder/Decoder Layers. Transformer-Base sets it to 6.
- `h`: The number of Multi-Head Attention. Transformer-Base sets it to 6.
- `d-ff`: The hidden size of Position-wise Feed-Forward Networks. It was mentioned in Section `3.3`
- `activation`: The activation of Position-wise Feed-Forward Networks. If we want to experiment `GELU` instead of `RELU`, which activation was wisely used recently.
- `dropout-rate`. Dropout rate of any Layer. Transformer-Base sets it to 0.1
- `eps`. Layer Norm parameter. Default value: 0.1
After training successfully, your model will be saved to `model-folder` defined before
### IV. TODO
- ~~Bugs Fix~~:
In this project, you can see that we try to compile all the pipeline into `tf.keras.Model` class in `model.py` file and using `fit function `to train the model. Unfortunately, there are few critical bugs we need to fix for a new release.
- Fix exporting model using save_weights API. (Currently, the system is unable to reload checkpoint for some unknown reasons.)
- New Features:
- ~~Reading files Pipeline (Release Time: 06/07/2021)~~
- Adapting BPE, Subwords Tokenizer (Release Time: Updating...)
- Use Beam Search for better-generating words (Release Time: Updating...)
- Set up Typing weights mode (Release Time: Updating...)
### V. Running Test
When you want to modify the model, you need to run the test to make sure your change does not affect the whole system.
In the `./transformer` folder please run:
```bash
pytest
```
### VI. Feedback
If you have any issues when using this library, please let us know via the issues submission tab.