https://github.com/baochuquan/ios-vad
iOS Voice Activity Detection (VAD). Supports WebRTC VAD GMM, Silero VAD DNN, Yamnet VAD DNN models.
https://github.com/baochuquan/ios-vad
audio-processing deep-neural-network dnn gmm ios neural-networks offline on-device-ai onnex-models real-time silero silero-vad speech-detection speech-recognition vad voice-activity-detection voice-activity-detector voice-detection webrtc yamnet
Last synced: 3 months ago
JSON representation
iOS Voice Activity Detection (VAD). Supports WebRTC VAD GMM, Silero VAD DNN, Yamnet VAD DNN models.
- Host: GitHub
- URL: https://github.com/baochuquan/ios-vad
- Owner: baochuquan
- Created: 2024-11-08T01:47:23.000Z (12 months ago)
- Default Branch: main
- Last Pushed: 2024-11-14T14:55:20.000Z (12 months ago)
- Last Synced: 2025-05-13T00:47:15.754Z (6 months ago)
- Topics: audio-processing, deep-neural-network, dnn, gmm, ios, neural-networks, offline, on-device-ai, onnex-models, real-time, silero, silero-vad, speech-detection, speech-recognition, vad, voice-activity-detection, voice-activity-detector, voice-detection, webrtc, yamnet
- Language: Swift
- Homepage:
- Size: 4.5 MB
- Stars: 15
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
## iOS Voice Activity Detection (VAD)
iOS [VAD](https://en.wikipedia.org/wiki/Voice_activity_detection) library is designed to process audio in
real-time and identify presence of human speech in audio samples that contain a mixture of speech
and noise. The VAD functionality operates offline, performing all processing tasks directly on the mobile device.
The repository offers three distinct models for voice activity detection:
[WebRTC VAD](https://chromium.googlesource.com/external/webrtc/+/branch-heads/43/webrtc/common_audio/vad/) [[1]](#1)
is based on a Gaussian Mixture Model [(GMM)](http://en.wikipedia.org/wiki/Mixture_model#Gaussian_mixture_model)
which is known for its exceptional speed and effectiveness in distinguishing between noise and silence.
However, it may demonstrate relatively lower accuracy when it comes to differentiating speech from background noise.
[Silero VAD](https://github.com/snakers4/silero-vad) [[2]](#2) is based on a Deep Neural Networks
[(DNN)](https://en.wikipedia.org/wiki/Deep_learning) and utilizes the
[ONNX Runtime Mobile](https://onnxruntime.ai/docs/install/#install-on-web-and-mobile) for execution.
It provides exceptional accuracy and achieves processing time that is very close to WebRTC VAD.
[Yamnet VAD](https://github.com/tensorflow/models/tree/master/research/audioset/yamnet) [[3]](#3) is based on a Deep Neural Networks
[(DNN)](https://en.wikipedia.org/wiki/Deep_learning) and employs the Mobilenet_v1 depthwise-separable
convolution architecture. For execution utilizes the [Tensorflow Lite](https://www.tensorflow.org/lite/android) runtime.
Yamnet VAD can predict [522](https://github.com/tensorflow/models/blob/master/research/audioset/yamnet/yamnet_class_map.csv)
audio event classes (such as speech, music, animal sounds and etc).
It was trained on [AudioSet-YouTube](https://research.google.com/audioset/) corpus.
WebRTC VAD is lightweight (only 158 KB) and provides exceptional speed in audio processing, but it may exhibit lower accuracy
compared to DNN models. WebRTC VAD can be invaluable in scenarios where a small and fast library is necessary and where sacrificing accuracy is acceptable.
In situations where high accuracy is critical, models like Silero VAD and Yamnet VAD are more preferable.
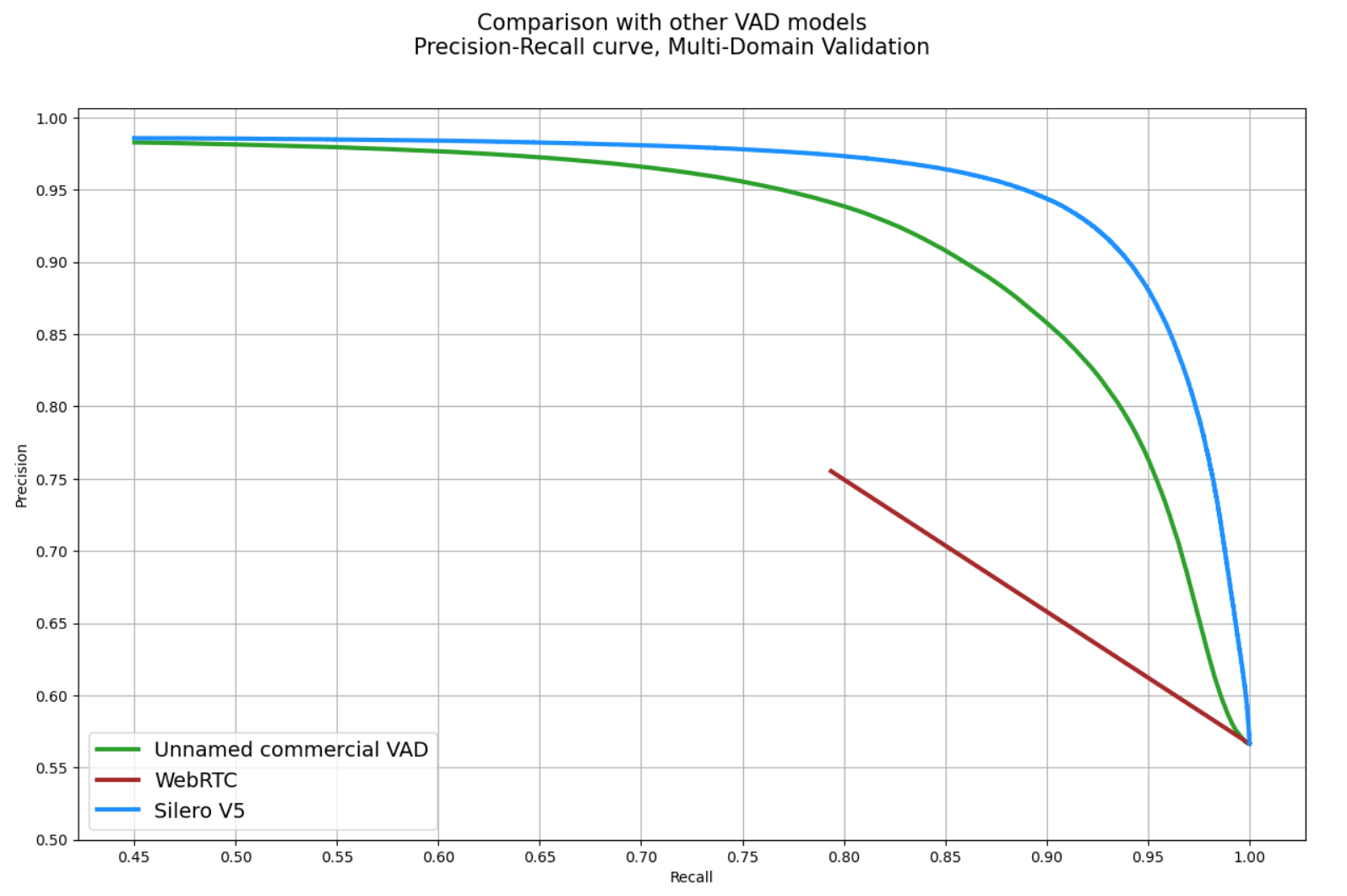
For more detailed insights and a comprehensive comparison between DNN and GMM, refer to the following comparison
[Silero VAD vs WebRTC VAD](https://github.com/snakers4/silero-vad/wiki/Quality-Metrics#vs-other-available-solutions).
## WebRTC VAD
#### Parameters
WebRTC VAD library only accepts **16-bit Mono PCM audio stream** and can work with next Sample Rates,
Frame Sizes and Modes.
| Valid Sample Rate | Valid Frame Size |
|:-----------------:|:----------------:|
| 8000Hz | 80, 160, 240 |
| 16000Hz | 160, 320, 480 |
| 32000Hz | 320, 640, 960 |
| 48000Hz | 480, 960, 1440 |
| Valid Mode |
|:----------------|
| NORMAL |
| LOW_BITRATE |
| AGGRESSIVE |
| VERY_AGGRESSIVE |
Recommended parameters for WebRTC VAD:
* Sample Rate (required) - **16KHz** - The sample rate of the audio input.
* Frame Size (required) - **320** - The frame size of the audio input.
* Mode (required) - **VERY_AGGRESSIVE** - The confidence mode of the VAD model.
* Silence Duration (optional) - **300ms** - The minimum duration in milliseconds for silence segments.
* Speech Duration (optional) - **50ms** - The minimum duration in milliseconds for speech segments.
#### Usage
WebRTC VAD can identify speech in short audio frames, returning results for each frame.
By utilizing parameters such as **silenceDurationMs** and **speechDurationMs**, you can enhance the
capability of VAD, enabling the detection of prolonged utterances while minimizing false positive
results during pauses between sentences.
Swift example:
```swift
// TODO
```
Objective-C example:
```objc
// TODO
```
An example of how to detect speech in an audio file:
```swift
// TODO
```
## Silero VAD
#### Parameters
Silero VAD library only accepts **16-bit Mono PCM audio stream** and can work with next Sample Rates,
Frame Sizes and Modes.
| Valid Sample Rate | Valid Frame Size |
|:-----------------:|:----------------:|
| 8000Hz | 256, 512, 768 |
| 16000Hz | 512, 1024, 1536 |
| Valid Mode |
|:----------------|
| OFF |
| NORMAL |
| AGGRESSIVE |
| VERY_AGGRESSIVE |
Recommended parameters for Silero VAD:
* Context (required) - The Context is required to facilitate reading the model file from the Android file system.
* Sample Rate (required) - **16KHz** - The sample rate of the audio input.
* Frame Size (required) - **512** - The frame size of the audio input.
* Mode (required) - **NORMAL** - The confidence mode of the VAD model.
* Silence Duration (optional) - **300ms** - The minimum duration in milliseconds for silence segments.
* Speech Duration (optional) - **50ms** - The minimum duration in milliseconds for speech segments.
#### Usage
Silero VAD can identify speech in short audio frames, returning results for each frame.
By utilizing parameters such as **silenceDurationMs** and **speechDurationMs**, you can enhance the
capability of VAD, enabling the detection of prolonged utterances while minimizing false positive
results during pauses between sentences.
Swift example:
```swift
// TODO
```
Objective-C example:
```objc
// TODO
```
## Yamnet VAD
#### Parameters
Yamnet VAD library only accepts **16-bit Mono PCM audio stream** and can work with next Sample Rates,
Frame Sizes and Modes.
| Valid Sample Rate | Valid Frame Size |
|:-----------------:|:------------------:|
| 16000Hz | 243, 487, 731, 975 |
| | 243, 487, 731, 975 |
| Valid Mode |
|:----------------|
| OFF |
| NORMAL |
| AGGRESSIVE |
| VERY_AGGRESSIVE |
Recommended parameters for Yamnet VAD:
* Context (required) - The Context is required to facilitate reading the model file from the Android file system.
* Sample Rate (required) - **16KHz** - The sample rate of the audio input.
* Frame Size (required) - **243** - The frame size of the audio input.
* Mode (required) - **NORMAL** - The confidence mode of the VAD model.
* Silence Duration (optional) - **30ms** - The minimum duration in milliseconds for silence segments.
* Speech Duration (optional) - **30ms** - The minimum duration in milliseconds for speech segments.
#### Usage
Yamnet VAD can identify [521](https://github.com/tensorflow/models/blob/master/research/audioset/yamnet/yamnet_class_map.csv)
audio event classes (such as speech, music, animal sounds and etc) in small audio frames.
By utilizing parameters such as **silenceDurationMs** and **speechDurationMs** and specifying
sound category (ex. classifyAudio(**"Speech"**, audioData)), you can enhance the capability of VAD,
enabling the detection of prolonged utterances while minimizing false positive results during
pauses between sentences.
Swift example:
```swift
// TODO
```
Objective-C example:
```objc
// TODO
```
## Requirements
#### iOS API
WebRTC VAD - iOS XX and later.
Silero VAD - iOS XX and later.
Yamnet VAD - iOS XX and later.
## Download
CocoaPods is the only supported build configuration, so just add the dependency to your project `Podfile` file:
1. Add it in your Podfile at the end of repositories:
```ruby
// TODO
```
2. Add one dependency from list below:
#### WebRTC VAD
```ruby
// TODO
```
#### Silero VAD
```ruby
// TODO
```
#### Yamnet VAD
```ruby
// TODO
```
## References
[1]
[WebRTC VAD](https://chromium.googlesource.com/external/webrtc/+/branch-heads/43/webrtc/common_audio/vad/) -
Voice Activity Detector from Google which is reportedly one of the best available: it's fast,
modern and free. This algorithm has found wide adoption and has recently become one of the
gold-standards for delay-sensitive scenarios like web-based interaction.
[2]
[Silero VAD](https://github.com/snakers4/silero-vad) - pre-trained enterprise-grade Voice Activity Detector,
Number Detector and Language Classifier hello@silero.ai.
[3]
[Yamnet VAD](https://github.com/tensorflow/models/tree/master/research/audioset/yamnet) -
YAMNet is a pretrained deep neural network that can predicts 522 audio event classes based on the AudioSet-YouTube
corpus, employing the Mobilenet_v1 depthwise-separable convolution architecture.
------------
Bao Chuquan 2024 (c) [MIT License](https://opensource.org/licenses/MIT)