https://github.com/baratgabor/mywarehouse
Clean Architecture and Domain Driven Design sample project based on C# 10 / .NET 6 / ASP.NET Core 6 / EF Core 6 & Angular 11 with Bootstrap.
https://github.com/baratgabor/mywarehouse
angular11 asp-net-core asp-net-core-6 bootstrap clean-architecture ddd domain-driven-design efcore efcore6 vertical-slice-architecture
Last synced: over 1 year ago
JSON representation
Clean Architecture and Domain Driven Design sample project based on C# 10 / .NET 6 / ASP.NET Core 6 / EF Core 6 & Angular 11 with Bootstrap.
- Host: GitHub
- URL: https://github.com/baratgabor/mywarehouse
- Owner: baratgabor
- License: mit
- Created: 2021-02-07T20:53:29.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2023-03-25T14:23:34.000Z (over 3 years ago)
- Last Synced: 2025-04-09T16:13:59.733Z (over 1 year ago)
- Topics: angular11, asp-net-core, asp-net-core-6, bootstrap, clean-architecture, ddd, domain-driven-design, efcore, efcore6, vertical-slice-architecture
- Language: C#
- Homepage:
- Size: 3.83 MB
- Stars: 254
- Watchers: 16
- Forks: 70
- Open Issues: 11
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
## MyWarehouse – A Clean Architecture, Vertical Slicing, DDD sample in ASP.NET Core
[](https://github.com/baratgabor/MyWarehouse/actions/workflows/backend-CI.yml) [](https://github.com/baratgabor/MyWarehouse/actions/workflows/backend-CD.yml) [](https://github.com/baratgabor/MyWarehouse/actions/workflows/frontend-CD.yml) [](https://coveralls.io/github/baratgabor/MyWarehouse?branch=master)
This is a sample project consisting of an ASP.NET Core web API backend service and an Angular frontend with Bootstrap.
I have finally decided it's time to have something public on my GitHub account that is actually relevant to my professional focus on ASP.NET Core, retiring those god-awfully written old classical ASP.NET projects I had on BitBucket.
The following, rather informatively written documentation page has a two-fold purpose:
1. To be – hopefully – useful for others who wish to explore a similar direction in development.
2. To provide a summary of my current approach to working with ASP.NET Core, and my current level of understanding thereof, so anyone who was interested in my skillset could easily review it in a single place.
## Live Demo
[See here](https://baratgabor.github.io/MyWarehouse). You'll have to sign in with the credentials shown on the picture below, or with your Google account*. The backend is hosted in an Azure App Service, connecting to an Azure SQL database. The frontend is hosted right here, at the excellent GitHub Pages. Apologies if the first request times out – Azure is spinning the services down if there is no traffic.
**Feel free to alter the data**, as the solution has an automatic [sample generation module](https://github.com/baratgabor/MyWarehouse/tree/master/src/SampleData) that I can run any time to reset it. What it doesn't have is a profanity filter. But I trust your maturity. 😅
**With respect to deployment**, the backend and the frontend are both automatically deployed by the corresponding [GitHub CD pipeline](https://github.com/baratgabor/MyWarehouse/tree/master/.github/workflows) when a push happens in the master branch. So the build you see should always reflect the state of the master branch.
**Google login privacy concerns: The app doesn't store any personally identifying data. The only data of yours that can end up being saved in database is your name (as `LastModifiedBy`) when you modify an entity. But no email address or Google profile ID is saved.*

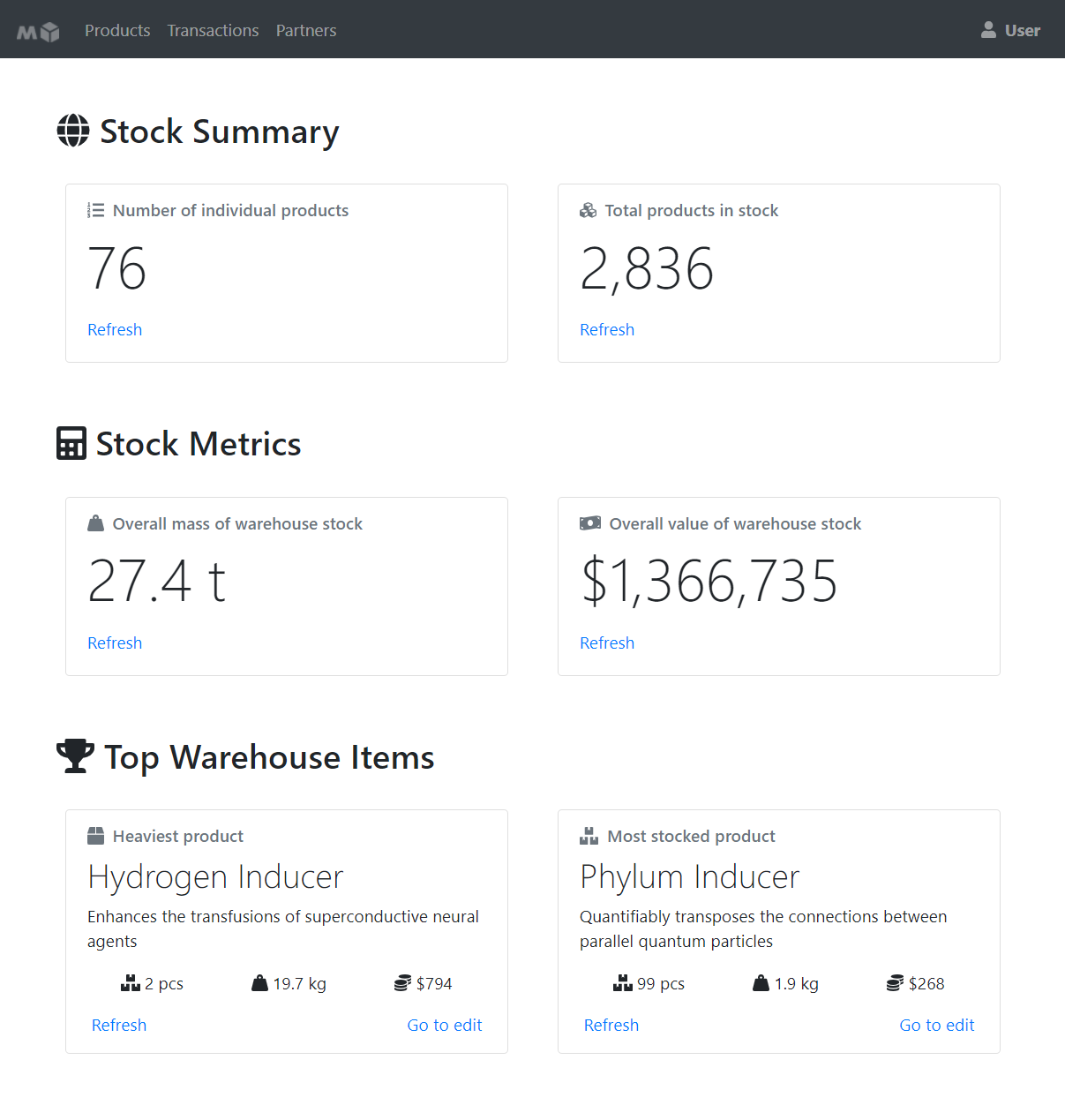
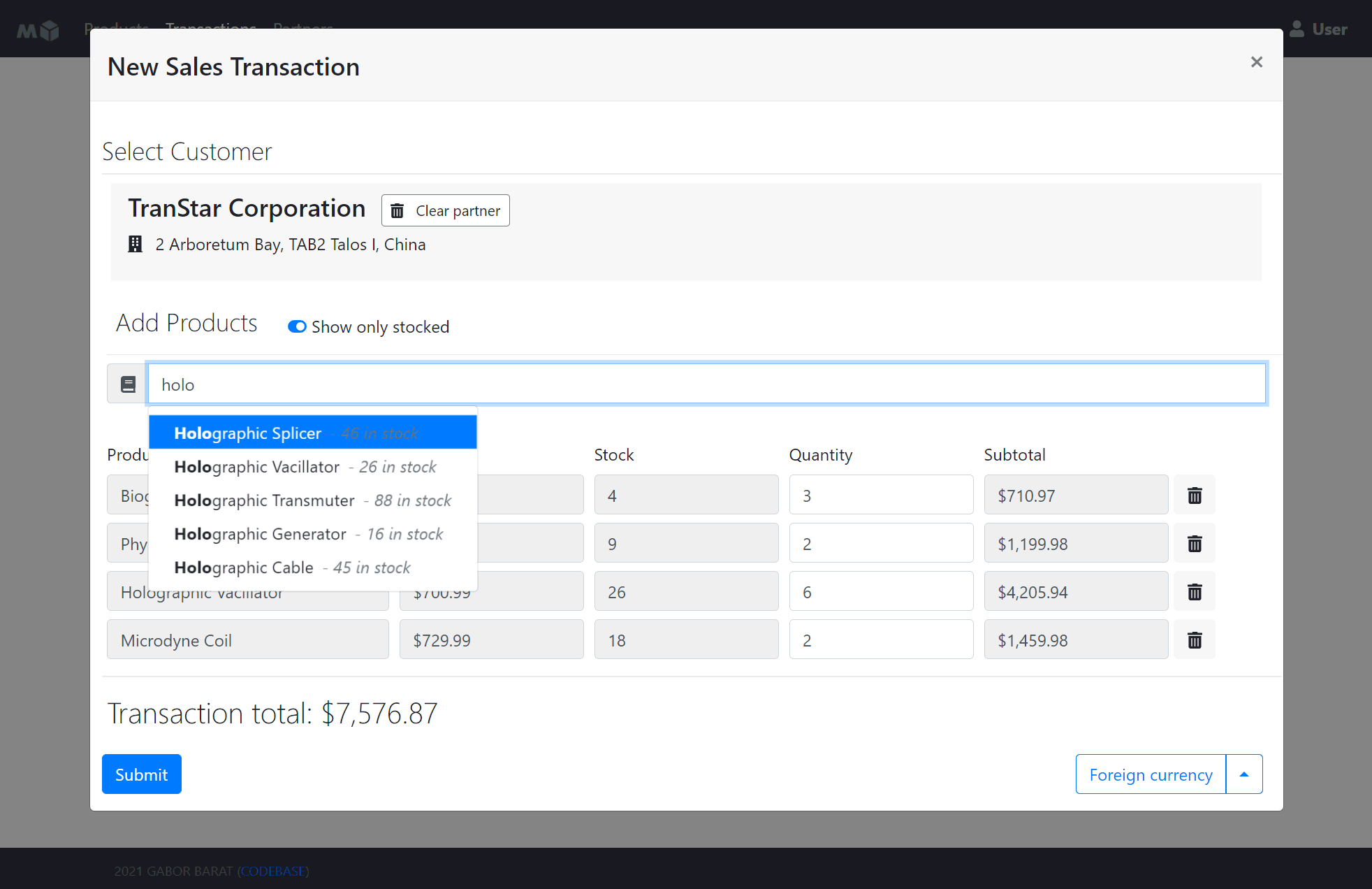
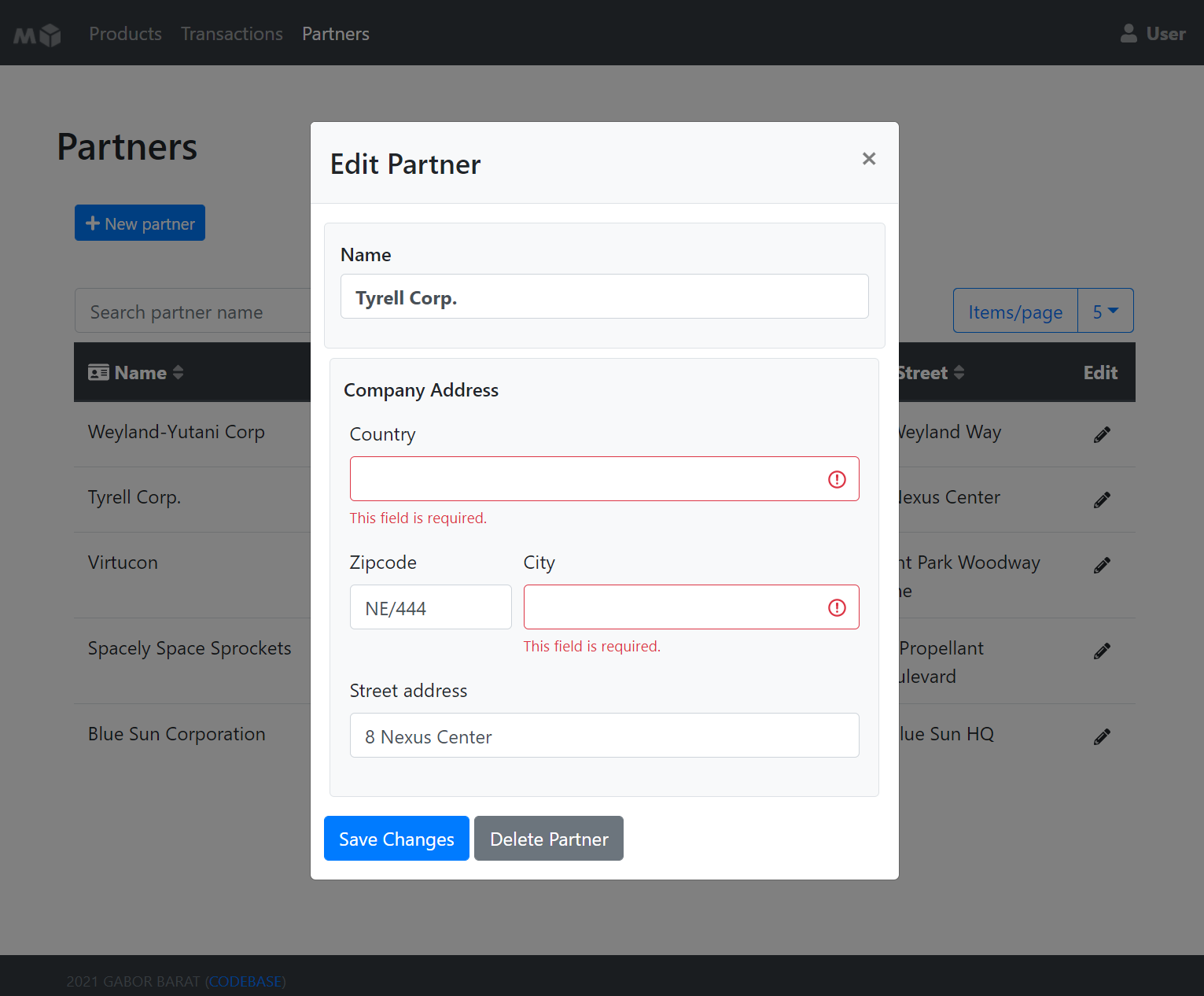
## Screenshots



---------
**Contents:**
- [Technologies](#technologies)
- [Backend Design Paradigms](#backend-design-paradigms)
* [Clean Architecture](#clean-architecture)
* [Vertical Slicing](#vertical-slicing)
* [Domain Driven Design](#domain-driven-design)
- [Project structure](#project-structure)
- [Diversions from and extensions to the Clean Architecture Template](#diversions-from-and-extensions-to-the-clean-architecture-template)
* [DDD in Domain](#ddd-in-domain)
* [Paging, ordering and filtering](#paging-ordering-and-filtering)
* [Infrastructure layer modularization](#infrastructure-layer-modularization)
* [Improved integration/unit testing](#improved-integrationunit-testing)
* [Support structure for strongly typed configuration](#support-structure-for-strongly-typed-configuration)
* [API versioning](#api-versioning)
* [Repository layer](#repository-layer)
* [Logging extensions](#logging-extensions)
* [No Identity Server integration](#no-identity-server-integration)
* [Deemphasizing CQRS](#deemphasizing-cqrs)
* [.Net 5 (C# 9) features](#net-5-c-9-features)
* [More feature-rich Angular frontend](#more-feature-rich-angular-frontend)
- [Potential improvements](#potential-improvements)
- [How to set up to run locally](#how-to-set-up-to-run-locally)
- [.NET 6.0 update improvements](#.net-6.0-update-improvements)
## Motivation
This experimental/sample project is the product of my experiences and pains with traditional n-tier, anemic model, file type folder based ASP.NET Web APIs. The ones where you have a `Controllers`, `Models`, `Services` top-level segregation, sometimes as separate assemblies, and your models are essentially simple DTOs, massaged by countless "services", "handlers", "managers", "validators", etc. All of which lead to a code base which is relatively hard to navigate, hard to reason about what touches what, brittle, and generally prone to bugs.
Also, oh my, the *Startup.cs madness*, where you just put everything in, and a few months later you have a monster Startup where you have no idea anymore what is required for what, and it often feels anything you touch breaks something else.
I'm not saying I never want to work on a more classical project, since there are realities we have to cope with, but I wanted to push my skillset and understanding into a new direction.
**Origin/disclaimer:**
This project had an older version I originally developed for a job application, with functionality they specifically asked to implement. I actually know very little of warehouses as a business domain, and I have no contact with any business experts from this domain, so the domain aspect (perhaps confusingly) is not intended to model a real warehouse. What I explored doing, with respect to the domain, is introducing validation and logic in entities, locking them down by not exposing mutable properties, and using value objects like *Money* and *Mass* (instead of [primitive obsession](https://blog.ploeh.dk/2011/05/25/DesignSmellPrimitiveObsession/)) in the context of EF Core (i.e. owned types).
## Technologies
[C# 10](https://devblogs.microsoft.com/dotnet/welcome-to-c-10-0/) ◊ [.NET 6](https://dotnet.microsoft.com/download/dotnet/6.0) ◊ [ASP.NET Core 6](https://docs.microsoft.com/en-us/aspnet/core/?view=aspnetcore-6.0) ◊ [Entity Framework Core 5](https://docs.microsoft.com/en-us/ef/core/) ◊ [Angular 11](https://angular.io/) ◊ [Bootstrap](https://getbootstrap.com/) ◊ [MediatR](https://github.com/jbogard/MediatR) ◊ [AutoMapper](https://automapper.org/) ◊ [FluentValidation](https://fluentvalidation.net/) ◊ [NUnit](https://nunit.org/) ◊ [Moq](https://github.com/Moq/moq4/wiki/Quickstart) ◊ [FluentAssertions](https://fluentassertions.com/) ◊ [Respawn](https://github.com/jbogard/Respawn) ◊ [Swagger](https://swagger.io/)
## Backend Design Paradigms
The backend system uses the following design paradigms (besides the fundamentals not worth mentioning). You can find plenty of dry materials pertaining to these subjects, so I mostly focused on providing a pragmatic narration that could perhaps help you to 'get the point' if you had difficulties extracting that value from other sources.
### Clean Architecture
Uncle Bob's [Clean Architecture](https://www.oreilly.com/library/view/clean-architecture-a/9780134494272/) is one of the most well-known modern architectural paradigms, which focuses on creating an application core that is devoid of infrastructural implementation concerns, pushing those out to an infrastructure layer (including the persistence mechanism, which is quite famously argued to be just a 'detail').
Similarly to the [onion architecture](https://jeffreypalermo.com/2008/07/the-onion-architecture-part-1/), the dependencies between layers are strictly **pointing inwards,** so you end up with a domain and application layer that is self-contained and decoupled from higher level, less stable components of the system. Application layer dependencies are declared locally as interfaces, implemented by concrete services in the infrastructure layer. This is in contrast to the classical n-tier design where you have horizontal layers on top of a database communication layer, often tightly coupling the business logic to infrastructural and external concerns, arguably leading to maintenance headaches down the road.
The basis of my project structure comes from Jason Taylor's excellent [Clean Architecture](https://github.com/jasontaylordev/CleanArchitecture) template, inspired by his relevant [conference talk](https://www.youtube.com/watch?v=dK4Yb6-LxAk). But, even though this is still just a small sample project, I vastly expanded on that template, implementing many structurally significant decisions; the most significant being the integration of DDD concerns in the Domain.
### Vertical Slicing
Vertical slicing is the concept and technique of structuring your solution into more-or-less self-contained feature slices *instead of using a bunch of generalized services from layers upon layers*.
The inspiration comes from the experience of brittleness that a highly service-oriented architecture can exhibit. E.g. when you try to implement a new feature or modify an existing, so you change the service it depends on, only to realize that **you broke another feature** that depended on the same service, because you didn't take into account all use cases of the given service component. Then you go and fix it, only to see that you broke another feature in a component far away which was relying on a second service that was relying on some validator used by a fourth service... Let's be honest: this is the day-to-day reality of many developers.
And there comes the realization that *DRY – don't repeat yourself –* can be recipe for spaghetti code, unless you take something very-very seriously:
> *What matters is not whether code in two or more places look similar in form, but whether you can guarantee that they have the same – preferably single – reason to change.* (Sorry, not an actual quote, just wanted to highlight it.)
Vertical slicing also challenges our heavily ingrained modern-day compulsion to extract everything into reusable horizontal service components. Because the truth is that even if a piece of code is used in a single place, today we very often still do place that in some generalized service, partially because that's simply how we do things, and also because without vertical slices we often don't have a good place to put such code.
Vertical slicing leads to a design where each feature, or operation, or [use case](https://martinfowler.com/bliki/UseCase.html) is more substantial than just a few calls on a bunch of generalized services, and actually encapsulates proper business logic in a structurally segregated manner.
Obviously this is an oversimplification, and in any complex system you'll undoubtedly still end up with plenty of generalized components that implement actually general/cross-cutting concerns. It's just that you can focus your design process around vertical slices, feel comfortable putting business logic into them in a prima facie fashion, and when you see the need you can *then* push those down to the domain entities (to implement DDD), or into general components.
Another great thing about vertical slicing that it aligns well to [SCREAMING ARCHITECTURE](https://blog.cleancoder.com/uncle-bob/2011/09/30/Screaming-Architecture.html), where you look at a solution, and what you see are not meaningless generic tech terms like models, services, dtos, validators... but you see *what the system actually does, what features it has*. Which arguably makes it easier to comprehend and work with a system.
One great, modern take on vertical slicing comes from [Jimmy Bogard](https://jimmybogard.com/), developer of the widely used AutoMapper package, and it uses another of his projects, [MediatR](https://github.com/jbogard/MediatR). Here is an excellent talk from him on [vertical slice architecture](https://www.youtube.com/watch?v=SUiWfhAhgQw) (notice how he is not calling it "CQRS").
In my humble, but perhaps cheeky, opinion, there are two key things to understand about MediatR:
1. ##### MediatR is not a mediator:
It's just not. I think pretty much everybody who knows their [object-oriented design patterns](https://sourcemaking.com/design_patterns) are bound to see this. It indeed couples two objects with an intermediary, decoupling the direct connection between the two, but that alone doesn't make it into a mediator; a bunch of behavioral design patterns do that.
One classical example of the mediator pattern is chat rooms, where you have multiple people wanting to broadcast messages. And instead of making their object representation know about and send messages to each one of them back and forth, you use an intermediary – a mediator – to facilitate distributed two-way communication between them. Another example is a taxi service where the dispatcher mediates between the taxis, instead of all of them having to know about all others. So, usually it refers to longer-term, more complex communication between more than two participators.
But, there is another pattern, called commanding, where you encapsulate an operation into an object, and execute that object with a handler. *Which is exactly what MediatR does.* And how do you select the handler with MediatR? Through a *service locator*, a.k.a. the [service locator anti-pattern](https://blog.ploeh.dk/2010/02/03/ServiceLocatorisanAnti-Pattern/).
TL;DR;: It's commanding with a service locator on top. Duh. But no matter how we call it, it's a pretty cool piece of code, and the service locator is arguably not that big of a deal here (although it does obfuscate what handler will actually execute). By the way, I didn't direct this against the developer of MediatR in any way; I'm 100% sure that Jimmy Bogard knows design patterns twenty times better than me, and it's just that name selection often has little to do with semantics, not to mention that projects can change in scope and direction.
2. ##### MediatR has little to do with CQRS:
This really has become one of my pet-peeves. For some reason 90% of people on the internet today seem to associate MediatR with CQRS, and they refer to "*doing CRQS with MediatR*", while their solution shows no concern or need to actually segregate queries from commands, and what they're doing is just *vertical slicing in a command-driven fashion*. Because simply naming some of your request handlers as commands and others as queries is *emphatically not CQRS*. CQRS is [this](https://martinfowler.com/bliki/CQRS.html), and as Martin Fowler notes, one should be very cautious about using it because of the added complexity.
*CQRS, or command-query responsibility segregation, is an orthogonal pattern*. You can do CQRS with MediatR, or you can decide not to do CQRS with MediatR. Just as you can do CQRS without MediatR, or decide not to do CQRS without MediatR. But yes, arguably it's easier to implement CQRS (and a lot of other things) if you have a *vertical slice architecture*.
In fact, I felt that in my sample project creating an additional level of *Commands* and *Queries* folders (like in Jason Taylor's Clean Architecture template) don't add any value to my design, and even distracts from the goals of screaming architecture, so I simply placed all operations for a given aggregate in the same folder.
Here is an article from someone who gets it: [No, MediatR Didn't Run Over My Dog](http://scotthannen.org/blog/2020/06/20/mediatr-didnt-run-over-dog.html).
Huh, this was a long section. 😅
### Domain Driven Design
The alternative to those empty 'entities' that solely consist of public `{ get; set; }` properties – doing proper OOP in our entities. I learned proper OOP design a good while ago, and honestly, it was *damn difficult* back then, because when I started to program I wrote procedural code in Commodore BASIC, then in QBasic, then in Turbo Pascal, then in PHP, and I was strongly conditioned to think in procedural terms.
Though, by banging my head against the proverbial wall I did succeed in rewiring my neural pathways to think in terms of interconnected objects which were *responsible for their own valid state*, exposing operations that were their concern to execute on their own state, and using other objects to execute other operations. And I have seen *immense value* in my designs when I started to be able to properly implement these principles (which admittedly took years, to get through the initial super-convoluted designs that added plenty of complexity without much value, which I believe are actually the reason so many people are questioning the worth of OOP (plus the inheritance madness we were doing, leading to rigid systems, but that's another long topic)).
But, when I started to work with ASP.NET, for some reason I swiftly abandoned everything I learned about object-oriented design, and I adapted to using a bunch of properties as my "model". That seemed to be the ASP.NET way of doing things, and I was a newcomer to this strange and wonderful land. Not to mention being thoroughly **terrified** of what would happen to the ORM (EF) if I added anything else than properties to the entities. *But you can add. You can add a **lot**.* At least with the current versions of EF Core.
Okay, this was quite abstract, with plenty of babbling. For some details of the actual implementation, [see the relevant section below](#ddd-in-domain).
## Project structure

The most important takeaway is that the application is separated both from the presentation (in this case the web API) and the infrastructural concerns. This way you have a highly flexible application core that you could run in multiple ways, and under various, replaceable infrastructural conditions.
Furthermore, the domain driven design (in contrast to anemic domain) helps to ensure that only valid operations are executed on the domain entities. This makes implementing application features less error-prone, especially for newer members of a team.
The vertical slice architecture of the application layer also helps to easily comprehend the behavior of the system, alleviating the usual 'what the hell is going on here' guesswork when someone new starts to work on a system.
*(The visualization of the Infrastructure layer in Clean Architecture varies. Sometimes it's shown to be on the same level as the outermost representation layer, but I think this doesn't align with the perspective of an external observer. From that perspective the presentation (in this case, the API) is the sole outermost layer.)*
## Diversions from and extensions to the Clean Architecture Template
As I mentioned earlier, the structural basis of this sample project, and many of its good ideas, come from Jason Taylor's excellent [Clean Architecture Template](https://github.com/jasontaylordev/CleanArchitecture), which has been gaining some traction in the ASP.NET community in recent years. He also has some great [conference talks on this subject](https://www.youtube.com/watch?v=dK4Yb6-LxAk).
But we all have to discover our own ways, based on our own experiences, following our own lead; arguably there is not much value in just mindlessly copying someone. So here is a list of my diversions and extensions. Part of them simply stem from the fact that this is not just a template, but instead a broader sample project with significantly more features. Another, smaller part are conscious disagreements.
### DDD in Domain:
- **Protected properties:** The properties of domain entities are exposed in a protected fashion, as getters or read-only collections. Property changes are implemented through explicit methods instead of custom setters, because validation errors can be thrown, and in my view we developers generally expect property setters not to be a source of exceptions. You can look at the [`Product`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Domain/Products/Product.cs) entity for example.
- **Operations on entities:** Operations that can be construed to be the concern of a certain domain entity are implemented as a method directly on the given domain entity. Examples are [`partner.SellTo()` / `.ProcureFrom()`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Domain/Partners/Partner.cs#L39) and [`product.RecordTransaction()`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Domain/Products/Product.cs#L84). This helps to maintain business rules, since they are implemented centrally right where they are relevant, instead of being spread out to multiple services.
- **Creation constraints:** A popular article on the subject, [Don't Create Aggregate Roots](https://udidahan.com/2009/06/29/dont-create-aggregate-roots/), puts forward a case for avoiding the direct creation of domain entities when they can be reasonably created from another entity. If a service layer can `new` up and save entities haphazardly, that goes against the protections we'd want to see from a well-designed domain.
- In this sample project a `Transaction` for example can only be created by calling the `SellTo()` or `ProcureFrom()` method on a `Partner` entity (at least from outside the domain assembly).
- I haven't found a non-contrived creation source for `Partner` and `Product`, though. Ostensibly this is due to the low complexity and limited modeling scope of this project. But still, I only exposed parameterized constructors to make sure instantiation happens in a valid fashion.
- **Required/Length attributes:** Just a brief note that I still used `[Required]` and `[StringLength]` attributes on entities, instead of configuring everything in DbContext, because it seems to me these are domain constraints, not infrastructural concerns.
- **Value objects:** This is a *biggie* with EF Core, since not long ago it was largely unfeasible. [Value objects](https://martinfowler.com/bliki/ValueObject.html) are things that are 'complex', and might have rules, but they don't have an identity, and they're purely defined by what they contain. For example Address, Money, Mass, Date Range, Point, Phone Number. When you avoid [primitive obsession](https://blog.ploeh.dk/2011/05/25/DesignSmellPrimitiveObsession/), you often end up with value objects. In this project I explored this by implementing `Money` and `Mass` value objects, each with their corresponding nested `Currency` and `MassUnit` value object, respectively. And I persisted these through a (I think rather elegant) [value conversion](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Infrastructure/Persistence/Context/ApplicationDbContext.cs#L110) that stores and restores them as a scalar plus a currency code or unit symbol, respectively.
1. A case for value objects commonly manifests as one-to-one relationships in EF, which are actually red flags that the given referenced entities probably should be considered to be part of the root entity.
2. EF Core has a feature called [owned types](https://docs.microsoft.com/en-us/ef/core/modeling/owned-entities), which is widely used to implement value objects (I used it too, obviously). EF Core saves the properties of owned types right into the parent's table, in `OwnedType_PropertyName` fashion.
3. Using them and setting them up is not completely trivial, and you can still run into issues and missing features. For example, you cannot universally declare a type as an owned type via the `ModelBuilder`; you have to configure each reference to the type ([see it in my DbContext](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Infrastructure/Persistence/Context/ApplicationDbContext.cs#L97)) individually (or use the `[Owned]` attribute on the type directly). EF Core also hates when you have the same instance of the owned type assigned to multiple root entities. You should avoid this, and always create copies, because otherwise you can find your SQL statements failing (or worse, succeeding) due to EF Core writing nulls for the given owned types because they were already being tracked, and they didn't change. Consider the scenario of creating a new order or transaction, and as part of it, saving some properties of the products or partners (current price, current address)... Finally, be aware that deletion cascades to owned types too, so you might need to handle that if you manipulate entry states in your DbContext.
### Paging, ordering and filtering:
- **Paged Query / Response Models:** It's hard to imagine using *any* API without support for paging, ordering and filtering. The original Clean Architecture Template has no such features, but I implemented a relatively okay design into this project. All list queries utilize the same `ListQueryModel` base class (extended with additional properties for the given entity, if needed), and they return a `ListResponseModel` that contains the currently applied paging parameters, the currently applied ordering and filtering, and the result set.
- **OData-compliant filtering and ordering:** Let me be frank, I don't like the OData standard's weird URL parameter schema, and also how its [integration](https://docs.microsoft.com/en-us/odata/webapi/netcore) is suggested with Microsoft's OData package. No way I'm gonna use those weird $ parameters and parentheses in my URLs unless someone pays me good money. But the filtering / ordering language itself is fine, so I added support for that. Which means this API supports queries that specify multiple orderbys, and multiple/complex filters.
- **AutoMapper expression mapping:** A big one, again. When we write proper APIs, where we *always* return DTOs instead of entities, and we flatten/map many of the properties, then allowing the consumers to specify filtering based on property names is a *pain*, because what they specify often doesn't exist on the actual entity. E.g. they want to sort Orders based on `order.CustomerName`, but what you actually have in the backend is `order.Customer.Name`, so it doesn't work. To be honest, even a year ago I was manually writing converters to support those scenarios. I didn't realize that if we use AutoMapper's [projection features](https://docs.automapper.org/en/stable/Queryable-Extensions.html) (with mapping profiles configured first, obviously), then that automatically translates the DTO property references in the Linq expressions back to entity property references. You just have to create the expressions with property names that are referencing DTO properties, and pretty much everything else is taken care of. *This also protects the properties of entities which are intentionally not exposed through DTOs; ordering and filtering only works on properties that exist on the DTO.*
### Infrastructure layer modularization:
- **Startup Modularization:** Each root folder in the Infrastructure project represents a 'module' (using the term loosely), with a separate `Startup.cs` file that handles the required registrations and pipeline injections. I really wanted to avoid the Startup hell where everything is thrown into the same place, and I think that having simple methods inside Startup is not sufficient separation. On the other hand, I didn't want to create a complicated meta-architecture around this; I generally prefer simplicity these days. This is as primitive as it gets: Each `Startup.cs` simply contains the `Configure()` and `ConfigureServices()` methods we're all used to, and the Infrastructure root's `Startup.cs` calls these methods. I like this explicitness more than using extension methods. To exclude a module, you just have to remove their call from `Infrastructure.Startup`. *(Though, this is not a perfect solution for modularization, because some features are interrelated, requiring cross-configuration, for example Identity, EF Core and authentication.)*
- **Further information:** If you're interested in ASP.NET Core / Startup modularization, [check this page](https://docs.servicestack.net/modular-startup). What they write about the current issues with ASP.NET Core makes *so much sense*, and it reflects my own experiences. That said, I'm skeptical if this complete separation of modules is feasible, due to the cross-dependencies I mentioned just above.
### Improved integration/unit testing:
- **Modular test helpers for integration testing:** I swear I fully intended to copy Jason's solution verbatim, because if something works for testing, I'd rather not waste any more time on it. But sadly that structure didn't get me far.
- **DbContext lifetime control:** One early issue I ran into is fetching some entities, then modifying and saving them in 'act'. In the original template a new DbContext is created and disposed for every single operation. This means what you fetch is not tracked in the scope of the next operation, therefore if you try to save them, EF Core attempts to save them as new entities. I found it to be more useful to **maintain a DbContext for the lifetime of the test** ([see code](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/tests/Application.IntegrationTests/TestBase.cs#L22)). To this end I exposed scope control methods in the relevant test helper. (Another solution could have been to try to `Attach()` entities when saving, but I felt that to be less elegant.)
- **Neat modularization:** I really do like my OOP. So much so that I found myself creating a separate [`TestHost`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/tests/Application.IntegrationTests/_testdep/TestHost.cs) class that you can instantiate to create... well, a test host. I also made a [`TestData`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/tests/Application.IntegrationTests/_testdep/TestData.cs) class that depends on a `TestHost` instance, and concerns itself with providing all the data access facilities available for tests. A third module, dependent on a `TestData` instance, called [`TestDataFactory`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/tests/Application.IntegrationTests/_testdep/TestDataFactory.cs), concerns itself with providing often used entities and entity states that can be used to drastically simplify the 'arrangement' of the tests (especially in DDD, where you can't just create and assign things willy-nilly). I *love* these things, because if something changes in the system (which does happen constantly), chances are I only have to change it in the test data factory, not in dozens or hundreds of tests. All in all, I think this structure is more robust and extensible.
- Of course this is still just developer testing, and as we know professional testers do things a bit differently:

### Support structure for strongly typed configuration:
- **C# 9's Init-only setters:** One handy use for the [new Init-only property setters](https://devblogs.microsoft.com/dotnet/welcome-to-c-9-0/) is inside strongly typed configuration classes. Properties declared as `init` instead of `set` can only be set once during initialization. Which means that `IConfiguration.Get()`, the pesky bugger that requires public setter for binding, can bind them just fine, and after they're bound they're immutable (at least if they contain only primitive properties, obviously). This is important, because my main concern about using bare configuration instances (instead of the `IOptions<>` wrapper [a lot of people hate](https://www.strathweb.com/2016/09/strongly-typed-configuration-in-asp-net-core-without-ioptionst/)) was that they could be accidentally modified. Not a concern anymore with `init`.
- **Configuration Registration and Retrieval helpers:** Just simple extension methods ([see code](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Infrastructure/Common/Extensions/ConfigurationExtensions.cs)) for adding strongly typed configuration instances. As I implied above, I'm adding and retrieving bare configuration instances instead of using the `IOptions<>` wrapper. It works fine, you don't have to use that wrapper if you don't need what it provides.
- **Configuration Validation:** When using the helper extension methods to add configuration instances, and the configuration classes contain validation attributes, they are validated. This is immensely helpful in making sure, at least at application startup, that all important configuration values are present, and you won't be getting strange errors later.
- **Conditional Validation:** It's extremely common to use bool flags in the configuration to indicate if something should be used or not; and that something often has properties that are needed only if the bool flag is `true`. To this end I implemented a simple custom `RequiredIfAttribute` , which allows treating a property as required only if a specified flag is true.
- **Azure Key Vault inclusion:** One module inside Infrastructure is responsible for wiring in Azure Key Vault into the Configuration. This means that the secrets inside the key vault will be available as part of the normal configuration. It's nothing complicated, but if you're interested in using Azure key vault and experienced any difficulties setting up the access or putting it in a neater place, [you can see the code here](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Infrastructure/AzureKeyVault/Startup.cs) (and follow the method calls backwards to see how is it routed). Although what probably will trip you up is not this simple configuration, but instead not setting up the proper access policy in the Key Vault that allows access from the app service as a principal registered in Azure AD.
### API versioning:
- **API versioning support:** I've added a new `Versioning` module to the WebApi project that enables versioning support via the `Microsoft.AspNetCore.MVC.Versioning` package. All versioning-related components reside here, but it doesn't function as a true pluggable module, since versioning heavily affects the general design and shape of an API. If you wish to learn more about versioning in ASP.NET Core, [check this wiki](https://github.com/microsoft/aspnet-api-versioning/wiki).
- **Swagger versioning:** The versioning module overrides the default Swagger doc generation options and Swagger UI options to enable API version selection in the Swagger UI. This showcases the use of `IPostConfigureOptions`, and also showcases the configuration of Swagger via discrete `SwaggerGenOptions` and `SwaggerUIOptions` config instances.
- **Versioned API input/output models:** One interesting aspect of API versioning is the way you decide to handle the input and output models of individual controller/endpoint versions. I think what works well is to maintain a discrete set of input and output models for each version (with their own validation rules); this ensures that you won't be introducing any accidental breaking changes. And then you map these models to/from the application models, which aren't versioned. I skipped this additional layer of abstraction here, because currently it wouldn't provide any value, since the API has a single version. But I included two helper interfaces in the `Versioning` module that might be handy for supporting versioning in simpler APIs: [`IVersionedApiInputContract`](https://github.com/baratgabor/MyWarehouse/blob/master/src/WebApi/Versioning/Interfaces/IVersionedApiInputContract.cs) and [`IVersionedApiOutputContract`](https://github.com/baratgabor/MyWarehouse/blob/master/src/WebApi/Versioning/Interfaces/IVersionedApiOutputContract.cs).
### Repository layer:
- **Persistence-focused `ApplicationDbContext`:** I do see the merit in Jimmy Bogard and Jason Taylor, among others, promoting using DbContext directly, especially in a vertical slice paradigm. And there have been people for a long time who passionately argued that DbContext in itself is a unit of work component that needs no abstractions on top. But just look at my [`ApplicationDbContext`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Infrastructure/Persistence/Context/ApplicationDbContext.cs). The poor thing is already full of relatively low-level persistence and mapping concerns, much of it specifically aimed at SQL persistence; and this is just a sample project. If I had put anything paging/sorting or custom query related in it, that would genuinely feel out of place and an SRP violation, and it would just feel muddled to work with.
- **Data-retrieval focused repositories:** I implemented traditional repositories due to the reasons explained below. I also followed the classical wisdom of not exposing `IQueryable` from the repositories, but I think in a vertical slice architecture it wouldn't be a categorical problem to do so, if it helps implementing some one-off queries in a way that avoids polluting the repositories.
- **Cross cutting concerns:** There are some data-retrieval related general concerns, for example paging, ordering and filtering on list queries. DbContext might be a good place for these, but as I mentioned above, that is often filled with persistence mechanism related concerns. So I placed these into a base repository that is used to derive concrete repositories from for each aggregates.
- **Aggregate level concerns:** You might want to define default filters, navigational property inclusions, or custom queries for certain aggregates, and repeating these things in all vertical slices just doesn't feel right, simply because you know that the given filtering or inclusion is a generalized concern for the aggregate. For example in `TransactionRepository` I ignored the query filters, because transactions cannot be deleted, and I wanted to list the transactions on soft-deleted partners and products as well. I also defined a special query for retrieving individual entities with all navigational properties included. But, in agreement with Jimmy Bogard, Jason Taylor, et al., I'd discourage filling a repository with a crapton of special queries that are used only for a *single operation*; that is absolutely a legacy approach. Unless the next point applies...
- **SQL-specific queries:** If you've worked with EF Core for longer than 5 minutes, you must know that it's not a transparent abstraction over the persistence mechanism. In fact it's a leaky abstraction. When using SQL persistence you often end up having to write Linq queries that are specifically designed for SQL so the expression could be translated into a SQL statement (e.g. grouping and aggregating). I see some problems with including these SQL-specific queries in application code, because *it tightly couples application code to the persistence mechanism*. And if we do that, it arguably erases some of the benefit of using Clean Architecture.
### Logging extensions:
- **Serilog structured logging integration with Loggly:** Structured logging is great, since you can save a lot of contextual data by logging the relevant objects. If you're new to or interested in integrating Serilog and/or Loggly, you can check out the [logging configuration of the project](https://github.com/baratgabor/MyWarehouse/tree/114b1098e08d56d5bac4185801be82ac12b5394a/src/WebApi/Logging). Though, the implementation is not completely correct, because logging is an Application layer concern, but for some reason I implemented it in the API layer. I don't plan to run this application core without the API, but still I will make a mental note to move this logging when I find some time.
### No Identity Server integration:
- **Why I don't like IS inside projects like this:** Remember the good old times when you didn't have to run a complete Identity Server inside your app (which might be just a prototype, a demo, or a sample like this) to have any sort of authentication support? I think it's bizarre, and way too heavy, to use this server in this fashion in projects that need absolutely no central authority, and need no support for issuing tokens for external parties.
- **Custom TokenService for issuing tokens:** I wrote a simple [`JwtTokenService`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Infrastructure/Authentication/Services/JwtTokenService.cs) for the purpose of issuing standard JWT tokens for logged in users. The tokens are validated by the authentication middleware by virtue of properly configuring the standard [`JwtBearerOptions.TokenValidationParameters`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Infrastructure/Authentication/Startup.cs). This is obviously not very robust overall, but it's arguably scaled well to the nature and scope of a sample project, and it shows that I understand how to work with JWT tokens.
### Deemphasizing CQRS:
- **Simplified folder structure:** [Screaming architecture](https://blog.cleancoder.com/uncle-bob/2011/09/30/Screaming-Architecture.html) is the concept of organizing your solution in a way that you look at it, and it's immediately obvious what does the system do (I know, I mentioned it earlier). One major way to achieve that is to name your folders based on what the components inside do, instead of e.g. the types of files they contain (which is a very popular legacy approach in ASP.NET, think about Models, Views, Controllers). In this project I didn't feel that separating `Queries` and `Commands` as an entire added organization level provides any value, so I just didn't do it. It's nothing huge, but I think it brings the true behavioral aspects of the project one level closer to the surface.
- **If it's not important, why force it:** I wrote plenty earlier about my pet peeve, which is how people emphasize CQRS when they're just implementing vertical slicing. Segregating queries and commands can be a core aspect of certain projects, but in other projects it's hard to imagine that they'll ever be properly implemented or provide any value. I think it's important to be pragmatic about this, and if the case seems to be the latter, then avoiding *muddling the architectural vocabulary of the project with irrelevant concepts*. I felt it was worth another section to express this sentiment.
### .Net 5 (C# 9) features:
*These are really minor things, I'm just trying to spread the good word about the new features, so more people tried them.*
- **Switch expressions:** Actually it's a C# 8 feature I think, but still not widely known. The modern `switch`, with expression form and pattern matching support, is an insanely powerful tool for certain use cases, i.e. [complex evaluation and mapping](https://docs.microsoft.com/en-us/dotnet/csharp/tutorials/pattern-matching). I recommend [this NDC talk](https://youtu.be/aUbXGs7YTGo?t=2097) as well on the same subject (NDC conference talks are awesome in general). Where I utilized this in the project is for example mapping Application exceptions into Web API responses in [`WebApi.ApiExceptionFilter`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/WebApi/ErrorHandling/ApiExceptionFilter.cs#L33). It doesn't look impressive *at all*, because I have a very short list of exception types, but the fact that you can hardly notice it shows how neat and unobtrusive this syntax is compared to traditional structures.
- **Records:** I used [records](https://devblogs.microsoft.com/dotnet/c-9-0-on-the-record/#records) in all of the DTOs in Application layer to deemphasize them as classes, which are normally thought of as having a strong identity. But what I primarily want to mention here is that while doing so is semantically neat, you can run into some difficulties. In particular, FluentAssertions really doesn't/didn't work well with records, because records have an overridden `.Equals()` method, so FluentAssertions assumes that it should use it in `BeEquivalentTo()` assertions. And that creates a total mess in my opinion, because it automatically leads to non-equal evaluation when the types are different, defeating the purpose of using `BeEquivalentTo()` in the first place. So you're forced to *always, always* specify the `o => o.ComparingByMembers()` option, even in the most trivial of cases, which is just annoying. See for example [`CreateTransactionTests`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/tests/Application.IntegrationTests/Transactions/CreateTransactionTests.cs#L49).
- **Init-only setters:** I talked about this already. It's a very handy feature for making classes immutable while keeping them initializable and easily bindable. I used init-only properties in all DTOs in the Application layer (see e.g. [`CreateTransactionCommand`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Application/Transactions/CreateTransaction/CreateTransactionCommand.cs#L13)), and in all strongly typed configuration classes (see e.g. [`AuthenticationSettings`](https://github.com/baratgabor/MyWarehouse/blob/114b1098e08d56d5bac4185801be82ac12b5394a/src/Infrastructure/Authentication/Settings/AuthenticationSettings.cs)). Haven't experienced any side effects or weirdness.
### More feature-rich Angular frontend:
- **I'm not a front-end developer** (™): But I built a relatively decent and polished frontend for this project, at least from a UX perspective. So if you're new to Angular, it could be perhaps more helpful to look into it than the mostly blank Clean Architecture Template. I broke down most problems into reusable components, and centralized what I could. For example I automated the displaying of form validation errors via [custom validators](https://github.com/baratgabor/MyWarehouse/blob/master/src/WebUI/src/app/core/errorhandling/form-validation/validators/custom-validators.ts) and a component that [lists all reported validation errors](https://github.com/baratgabor/MyWarehouse/blob/master/src/WebUI/src/app/core/errorhandling/form-validation/components/show-validation-errors/show-validation-errors.component.ts). That said, chances are you can find better resources and samples for frontend development. And if you're an Angular pro or especially an RxJS pro, perhaps you can look into it just to laugh at me. Although I genuinely didn't see much use for Stores in this particular project. Besides:

Not to mention:

## Potential improvements
- **HttpService, external services:** It's just *strange* to have any project these days that doesn't communicate with at least some external APIs. So it would be great to find a few good candidates for integration. One of them could be the exchange rate service that I added to the frontend earlier in a rather lazy and ad-hoc fashion.
- **Localization:** Seems like this would be a reasonable and well-placed addition. I've worked on web API localization earlier with good results, but I'd have to research how to implement it in a DDD paradigm, because frankly I have no clue (and that is exactly why it would be a good subject to explore).
- **Audit system:** A system for storing all changes to the entities, with the ability to list these changes through the API and display them for users on-demand. This is actually something I haven't had to implement yet, so this will also require a bit of research.
- **Actual warehouse features:** For example adding dimensions to products, and at the very least aggregating those dimensions to ascertain if the warehouse is full (after also designating a given warehouse capacity). But there is no end to these potential features, as warehouses are obviously complex structures, and I'm not that interested in actually making a working warehouse system, so the basis of consideration should be whether something is a good learning experience in DDD or API design.
- **Swagger Codegen:** I didn't implement automatic code generation for the frontend services, and probably it would be a good idea to look into doing so.
## How to set up to run locally
It you wish to clone this repository and use it (for whatever purpose you see fit), you'll have to take care of the following:
- Download and install **.NET 5 and ASP.NET Core 5 runtime** for the backend. The other project dependencies will be restored via NuGet.
- Install **Node.js and npm package manager** on your machine, and run `npm install` in the `WebUI` project folder to restore the frontend packages. Frontend can be run with `ng serve`.
- The less obvious one – **Secrets in configuration**:
- The backend system relies on multiple configuration values that are treated as 'secrets' and aren't part of the configuration committed to git. A `// Secret` comment identifies these in `WebApi.appsettings.json`.
- An excellent place for these secrets is the **User Secrets file**. You can access this file by right-clicking the `WebApi` project, and selecting **Manage User Secrets**.
- This opens a `secrets.json` file (which is actually located in your user profile folder, and not in the solution folder). In this json file you can enter any additional configuration values you'd want to see injected over the default appsettings.json (ideally only the secrets).
- To set a nested configuration setting in a short way, you can use colon (`:`) as a separator. For example to set the `DefaultUsername` property inside `UserSeedSettings`, you can simply set a value for `"UserSeedSettings:DefaultUsername"` (the configuration system flattens the hierarchical settings internally in the exact same format).
- The following could be a valid configuration that should allow running the solution in development mode (keep `LogglySettings:WriteToLoggly` and `AzureKeyVaultSettings:AddToConfiguration` as false; and also please note this connection string does rely on [SQL Server Express LocalDB](https://docs.microsoft.com/en-us/sql/database-engine/configure-windows/sql-server-express-localdb?view=sql-server-ver15), which is a standard part of the 'ASP.NET and web development' workload in the Visual Studio installer):
```json
{
"UserSeedSettings:SeedDefaultUser": true,
"UserSeedSettings:DefaultUsername": "User",
"UserSeedSettings:DefaultPassword": "Password",
"UserSeedSettings:DefaultEmail": "something@gmail.com",
"ConnectionStrings:DefaultConnection": "Server=(localdb)\\mssqllocaldb;Database=MyWarehouseDb;Trusted_Connection=True;MultipleActiveResultSets=true",
"AuthenticationSettings:JwtSigningKeyBase64": "e09053f6847d466b8f243d9522c340ef234sdfds",
}
```
- Alternative to the user secrets file is using **environment variables**.
- You can set nested configuration properties with environment variables as well. This can be achieved by using a colon (`:`) separator as explained above, or on a Linux system you can use a double underscore (`__`) separator. Windows doesn't mind the underscores either, so you can just default to using double underscores.
- You can even set array values. For example to set the `CorsSettings.AllowedOrigins` array, which contains the list of hosts that are allowed to access the backend API, you could use the following format*:
`CorsSettings__AllowedOrigins__0 = http://frontendlocation.com`
`CorsSettings__AllowedOrigins__1 = https://frontendlocation.com`
*(\*Don't include a trailing slash `/` character, for the love of god, or any capital letters, because the host checking is absolutely primitive; it's basically just doing [a case-sensitive ordinal string comparison](https://github.com/dotnet/aspnetcore/blob/461c4ece84ef5e7385249994645a3262717d3ca5/src/Middleware/CORS/src/Infrastructure/CorsPolicy.cs#L179) with the host contained in `HttpContext`. And if CORS tells you that `CORS Policy Execution Failed`, that actually means that CORS policy execution succeeded, it just ascertained that the host should not be allowed.)*
- And of course you can just set them right in `appsettings.json` too. Nothing horrible will happen. It's just a good idea to get familiar with the proper ways to inject secret configuration values into the solution, because otherwise you can end up accidentally committing these to Git repos. The demo backend system hosted in Azure gets them from an Azure Key Vault, for example.
- You should be able to log in with the seeded default user account details.
- Sample data will be automatically generated in the database (unless `ApplicationDbSettings:AutoSeed` is set to `false`), so don't be surprised to see a bunch of products, partners and transactions.
## In conclusion
Thank you for your interest in this project and/or in this lengthy documentation page. I recognize that my style of writing readmes is different from what people usually do on GitHub, but since I don't publish on any platform I usually have plenty of things bottled up, so it just feels *nice* to write about them in a context where they are at least relevant.
I'm always open to improving my designs, and, as I mentioned, this was pretty much my first foray into DDD, so feel free to suggest improvements if you'd like to.
## .NET 6.0 update improvements
With plenty of delay, the project was finally updated to .NET 6 (which we were using at my workplace pretty much from release day). The sections below will introduce you to the notable improvements that have occurred in the scope of this update.
### ● IOptions pattern improvements
If I'm not mistaken, 6.0 is the version when we got the new `ValidateDataAnnotations()` and `ValidateOnStart()` methods on `OptionsBuilder`, both of which come very handy in strongly typed options validation. So I took the opportunity to update my options registration extension helper method in the following way:
```csharp
public static void RegisterMyOptions(this IServiceCollection services, bool requiredToExistInConfiguration = true) where T : class
{
var optionsBuilder = services.AddOptions()
.BindConfiguration(typeof(T).Name)
.ValidateDataAnnotations() // <- Note
.ValidateOnStart(); // <- Note
// Note this hack too :)
// You can pass a validation lambda to Validate() that will check if the section actually exists in configuration.
// This check runs on startup if ValidateOnStart() is called.
if (requiredToExistInConfiguration)
optionsBuilder.Validate((_, configuration)
=> configuration.GetSection(typeof(T).Name).Exists(), string.Format(ConfigMissingErrorMessage, typeof(T).Name));
services.AddSingleton(resolver => resolver.GetRequiredService>().Value);
}
```
### ● EF 6 "ConfigureConventions" – Centralized decimal precision config
There is a new feature in EF 6 that makes it **much** easier to configure entity properties in a cross-cutting manner. Previously you had to call `modelBuilder.Entity().Property(e => e.PropertyName)` to set configuration on a per-property basis, even if you wanted those constraints to apply to *all properties of a given type*, for example *all* strings to have the same maximum length, or *all* decimals to have the same precision. This lead to awkward solutions like the one below to have at least some sort of cross-cutting control (directly copied from this codebase before the .NET 6 update):
```csharp
// Before .NET 6
///
/// Set all decimal properties to a custom uniform precision.
///
private static void ConfigureDecimalPrecision(ModelBuilder builder)
{
foreach (var entityType in builder.Model.GetEntityTypes())
{
foreach (var decimalProperty in entityType.GetProperties()
.Where(x => x.ClrType == typeof(decimal)))
{
decimalProperty.SetPrecision(18);
decimalProperty.SetScale(4);
}
}
}
```
Now, after EF 6, we can do:
```csharp
// After .NET 6
protected override void ConfigureConventions(ModelConfigurationBuilder configBuilder)
{
configBuilder.Properties()
.HavePrecision(precision: 18, scale: 4);
} }
```
Bam! 👌
### ● EF 6 "ConfigureConventions" – Centralized conversion config
Similarly to the section above, configuring conversions for *all* properties of a given type is much easier now as well. Consider that the following code was present in the codebase before the .NET 6 update:
```csharp
// Before .NET 6
// Notice that conversion had to be set individually for each property of a given type.
// I had to resort to creating some local functions to reduce code repetition.
// Store and restore mass unit as symbol.
builder.Entity().OwnsOne(p => p.Mass, StoreMassUnitAsSymbol);
// Store and restore currency as currency code.
builder.Entity().OwnsOne(p => p.Price, StoreCurrencyAsCode);
builder.Entity().OwnsOne(p => p.Total, StoreCurrencyAsCode);
builder.Entity().OwnsOne(p => p.UnitPrice, StoreCurrencyAsCode);
static void StoreCurrencyAsCode(OwnedNavigationBuilder onb) where T : class
=> onb.Property(m => m.Currency)
.HasConversion(
c => c.Code,
c => Currency.FromCode(c))
.HasMaxLength(3);
static void StoreMassUnitAsSymbol(OwnedNavigationBuilder onb) where T : class
=> onb.Property(m => m.Unit)
.HasConversion(
u => u.Symbol,
s => MassUnit.FromSymbol(s))
.HasMaxLength(3);
```
Now after .NET 6 this has become:
```csharp
protected override void ConfigureConventions(ModelConfigurationBuilder configBuilder)
{
configBuilder.Properties()
.HaveConversion() // Notice how we're setting a converter for all props of this type.
.HaveMaxLength(3);
configBuilder.Properties()
.HaveConversion()
.HaveMaxLength(3);
}
```
The only downside is that we're forced to write converter classes (e.g. `CurrencyConverter` above), which is arguably a bit too much ceremony for very simple conversions where a short lambda would suffice.