https://github.com/beallio/wherewolf
Wherewolf is a production-grade, local SQL workbench designed for data engineers and analysts to query local files (CSV, Parquet, JSON) with ease. Built with Streamlit, it provides a unified interface to execute SQL against either DuckDB or PySpark engines without requiring complex setup.
https://github.com/beallio/wherewolf
big-data data-analysis data-engineering etl parquet performance pyspark python spark-sql sql uv
Last synced: 2 months ago
JSON representation
Wherewolf is a production-grade, local SQL workbench designed for data engineers and analysts to query local files (CSV, Parquet, JSON) with ease. Built with Streamlit, it provides a unified interface to execute SQL against either DuckDB or PySpark engines without requiring complex setup.
- Host: GitHub
- URL: https://github.com/beallio/wherewolf
- Owner: beallio
- License: mit
- Created: 2026-03-08T22:26:41.000Z (4 months ago)
- Default Branch: main
- Last Pushed: 2026-04-19T23:32:50.000Z (3 months ago)
- Last Synced: 2026-04-20T01:34:47.164Z (3 months ago)
- Topics: big-data, data-analysis, data-engineering, etl, parquet, performance, pyspark, python, spark-sql, sql, uv
- Language: Python
- Homepage: https://github.com/beallio/wherewolf
- Size: 228 KB
- Stars: 1
- Watchers: 0
- Forks: 0
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Agents: AGENTS.md
Awesome Lists containing this project
README
# Wherewolf

[](https://github.com/beallio/wherewolf/actions/workflows/ci.yml)
[](https://pypi.org/project/wherewolf/)
[](https://opensource.org/licenses/MIT)
A production-grade, local SQL workbench for querying files (CSV, Parquet, JSON) using DuckDB or Spark.
## Features
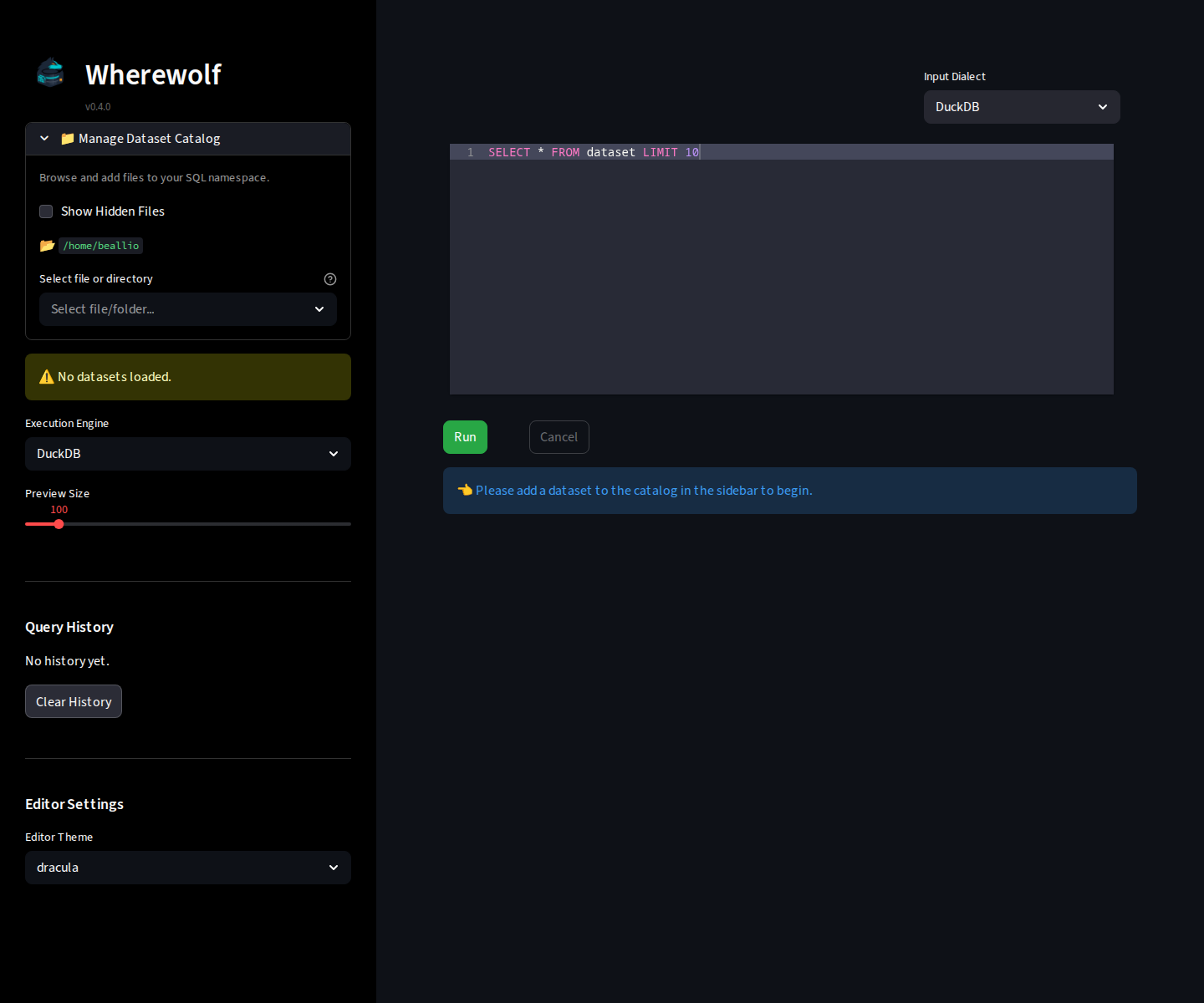
- **Multi-Engine Support:** Execute SQL via DuckDB (local) or Spark (local[*]). Native support for CSV, Parquet, JSON, and Excel (`.xlsx`, `.xls`).
- **📁 Dataset Catalog:** Improved file browser with directory-first sorting, folder icons, and extension filtering for a cleaner experience.
- **🔗 Multi-Table Queries:** Perform JOINs, unions, and subqueries across different file formats in a single session.
- **📊 Schema & Metadata HUD:** Instant visibility of column names and data types for any dataset in your catalog.
- **SQL Translation:** Real-time translation between DuckDB and SparkSQL dialects using SQLGlot.
- **Modern UI:** Distraction-free interface with a hidden toolbar, reduced whitespace, and clear visual hierarchy.
- **Safe Preview:** Scrollable results limited to 1000 rows.
- **Query History:** Persists past queries in `~/.wherewolf/history.json`.
- **Export:** Download query results as CSV, Excel, or Parquet.
- **Execution Metrics:** Tracks row count and execution time.
## Installation
Ensure you have [uv](https://github.com/astral-sh/uv) installed.
### From PyPI (Recommended)
```bash
uv tool install wherewolf
wherewolf
```
### From Source
```bash
git clone https://github.com/beallio/wherewolf.git
cd wherewolf
uv sync
```
## Usage
If running from source:
```bash
uv run streamlit run src/wherewolf/app.py
```
1. Use the **Manage Dataset Catalog** section in the sidebar to browse and add files.
2. Each file is assigned an alias (e.g., `users`, `orders`).
3. Write your SQL query using these aliases in the editor.
4. Click **Run** to execute.
5. View results, execution metrics, or switch the **Metadata Focus** to inspect other schemas.
6. Export or view the translated SQL if needed.
## Development
Run tests:
```bash
uv run pytest
```
Lint/Format:
```bash
ruff check . --fix
ruff format .
```
For information on how to release new versions, see [RELEASING.md](docs/RELEASING.md).
## Dependencies
- `streamlit`
- `duckdb`
- `pyspark`
- `ibis-framework`
- `sqlglot`
- `pandas`
- `pyarrow`
- `openpyxl`