https://github.com/ben-hayes/neural-waveshaping-synthesis
efficient neural audio synthesis in the waveform domain
https://github.com/ben-hayes/neural-waveshaping-synthesis
Last synced: 7 months ago
JSON representation
efficient neural audio synthesis in the waveform domain
- Host: GitHub
- URL: https://github.com/ben-hayes/neural-waveshaping-synthesis
- Owner: ben-hayes
- License: mpl-2.0
- Created: 2021-02-19T07:30:25.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2021-08-27T10:21:34.000Z (almost 4 years ago)
- Last Synced: 2024-08-09T13:19:35.776Z (11 months ago)
- Language: Python
- Homepage:
- Size: 25.6 MB
- Stars: 184
- Watchers: 2
- Forks: 15
- Open Issues: 5
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- StarryDivineSky - ben-hayes/neural-waveshaping-synthesis
README
neural waveshaping synthesis
real-time neural audio synthesis in the waveform domain
This repository is the official implementation of [Neural Waveshaping Synthesis](https://benhayes.net/projects/nws/).
## Model Architecture
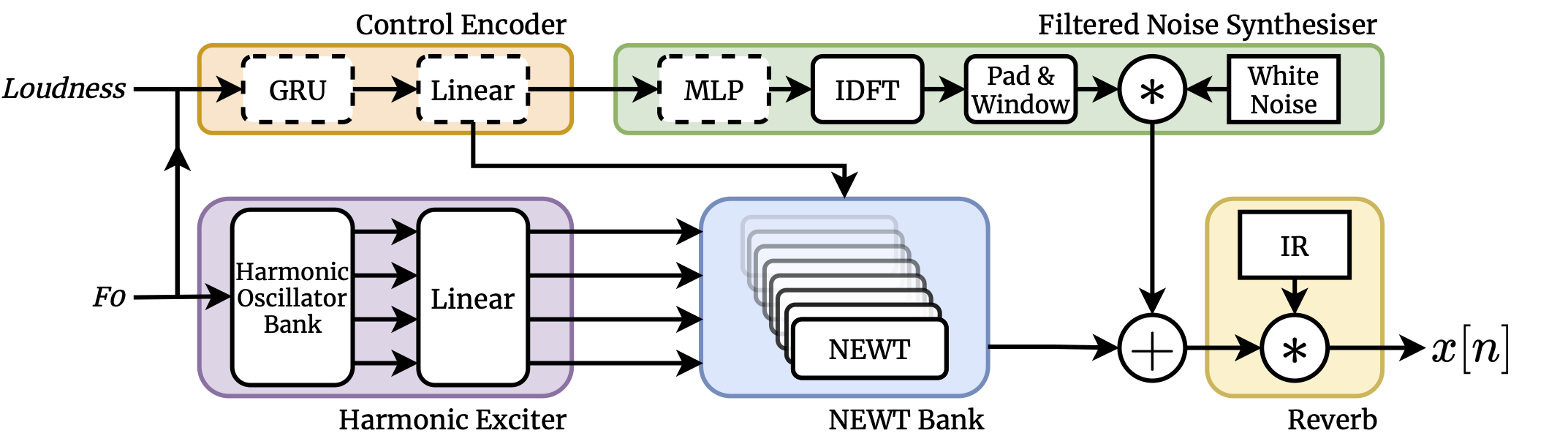
## Requirements
To install:
```setup
pip install -r requirements.txt
pip install -e .
```
We recommend installing in a virtual environment.
## Data
We trained our checkpoints on the [URMP](http://www2.ece.rochester.edu/projects/air/projects/URMP.html) dataset.
Once downloaded, the dataset can be preprocessed using `scripts/create_urmp_dataset.py`.
This will consolidate recordings of each instrument within the dataset and preprocess them according to the pipeline in the paper.
```bash
python scripts/create_urmp_dataset.py \
--gin-file gin/data/urmp_4second_crepe.gin \
--data-directory /path/to/urmp \
--output-directory /path/to/output \
--device cuda:0 # torch device string for CREPE model
```
Alternatively, you can supply your own dataset and use the general `create_dataset.py` script:
```bash
python scripts/create_dataset.py \
--gin-file gin/data/urmp_4second_crepe.gin \
--data-directory /path/to/dataset \
--output-directory /path/to/output \
--device cuda:0 # torch device string for CREPE model
```
## Training
To train a model on the URMP dataset, use this command:
```bash
python scripts/train.py \
--gin-file gin/train/train_newt.gin \
--dataset-path /path/to/processed/urmp \
--urmp \
--instrument vn \ # select URMP instrument with abbreviated string
--load-data-to-memory
```
Or to use a non-URMP dataset:
```bash
python scripts/train.py \
--gin-file gin/train/train_newt.gin \
--dataset-path /path/to/processed/data \
--load-data-to-memory
```