https://github.com/berkeleyautomation/rlqp
Accelerating Quadratic Optimization with Reinforcement Learning
https://github.com/berkeleyautomation/rlqp
admm-algorithm osqp quadratic-programming reinforcement-learning td3
Last synced: 10 months ago
JSON representation
Accelerating Quadratic Optimization with Reinforcement Learning
- Host: GitHub
- URL: https://github.com/berkeleyautomation/rlqp
- Owner: BerkeleyAutomation
- Created: 2021-07-07T16:31:15.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2021-10-30T03:45:16.000Z (over 4 years ago)
- Last Synced: 2025-01-25T21:26:32.584Z (over 1 year ago)
- Topics: admm-algorithm, osqp, quadratic-programming, reinforcement-learning, td3
- Homepage: https://BerkeleyAutomation.github.io/rlqp
- Size: 313 KB
- Stars: 87
- Watchers: 10
- Forks: 16
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# RLQP: Accelerating Quadratic Optimization with RL
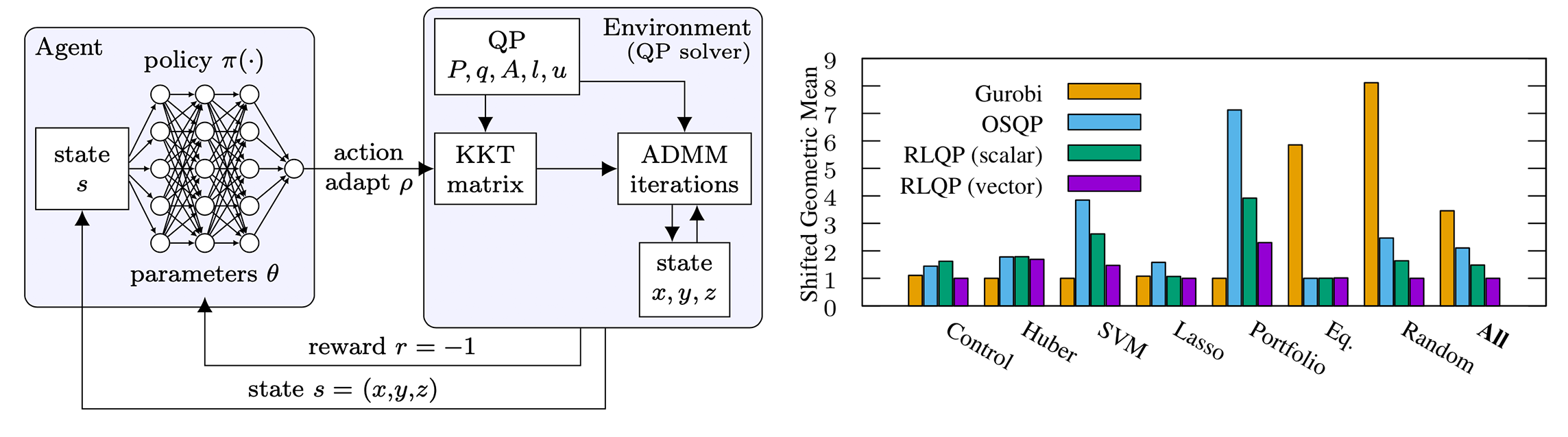
We demonstrate reinforcement learning can significantly accelerate first-order optimization, outperforming state-of-the-art solvers by up to 3x. RLQP avoids suboptimal heuristics within solvers by tuning the internal parameters of the ADMM algorithm. By decomposing the policy as a multi-agent partially observed problem, RLQP adapts to unseen problem classes and to larger problems than seen during training.
## Getting Started
RLQP is composed of a few submodules, namely to (a) train the RL policy on a specific class of problems (source in `rlqp_train/`) and (b) evaluate the policy on a test problem. Most users will want to start by using RLQP's policy to accelerate optimization of their problems.
### Prerequisites
### Installation (evaluation)
To install the Python package to *evaluate* a pre-trained policy, run:
```
pip install git+https://github.com/berkeleyautomation/rlqp-python.git@55f378e496979bd00e84cea4583ac37bfaa571a9
```
This package contains a pre-trained model which should improve convergence beyond OSQP. The interface is identical to OSQP.
### Installation (training)
Please follow the instructions in the `rlqp_train/` directory to setup and run training code. This code is still in *preview* mode as we work to release features like our TD3 policy.
## Citation
```
@article{ichnowski2021rlqp,
title={Accelerating Quadratic Optimization with Reinforcement Learning},
author={Jeffrey Ichnowski, Paras Jain, Bartolomeo Stellato,
and Goran Banjac, Michael Luo, Francesco Borrelli
and Joseph E. Gonzalez, Ion Stoica, Ken Goldberg},
year={2021},
journal={arXiv preprint}
}
```