https://github.com/bighuang624/vop
[CVPR 2023] VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval
https://github.com/bighuang624/vop
cvpr2023 parameter-efficient-tuning prompt-tuning transfer-learning visual-prompting
Last synced: 6 months ago
JSON representation
[CVPR 2023] VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval
- Host: GitHub
- URL: https://github.com/bighuang624/vop
- Owner: bighuang624
- Created: 2022-11-22T08:17:59.000Z (over 3 years ago)
- Default Branch: master
- Last Pushed: 2023-02-28T13:20:29.000Z (over 3 years ago)
- Last Synced: 2025-01-03T11:46:48.977Z (over 1 year ago)
- Topics: cvpr2023, parameter-efficient-tuning, prompt-tuning, transfer-learning, visual-prompting
- Homepage: https://kyonhuang.top/publication/text-video-cooperative-prompt-tuning
- Size: 2.93 KB
- Stars: 38
- Watchers: 4
- Forks: 3
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Text-Video Co-operative Prompt Tuning (VoP)
**News: The paper has been accepted to CVPR 2023!**
* **Title**: **[VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval](https://arxiv.org/pdf/2211.12764)**
* **Authors**: [Siteng Huang](https://kyonhuang.top/), Biao Gong, Yulin Pan, Jianwen Jiang, Yiliang Lv, Yuyuan Li, [Donglin Wang](https://milab.westlake.edu.cn/)
* **Institutes**: Westlake University, Alibaba Group, Zhejiang University
* **Conference**: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 (CVPR 2023)
* **More details**: [[arXiv]](https://arxiv.org/pdf/2211.12764) | [[homepage]](https://kyonhuang.top/publication/text-video-cooperative-prompt-tuning)
We are in the process of cleaning up the source code and awaiting corporate review to open source it. We have released a version of the basic VoP in [ModelScope](https://modelscope.cn/models/damo/cv_vit-b32_retrieval_vop/summary). ModelScope is built upon the notion of “Model-as-a-Service” (MaaS). It seeks to bring together most advanced machine learning models from the AI community, and streamlines the process of leveraging AI models in real-world applications.
## Overview
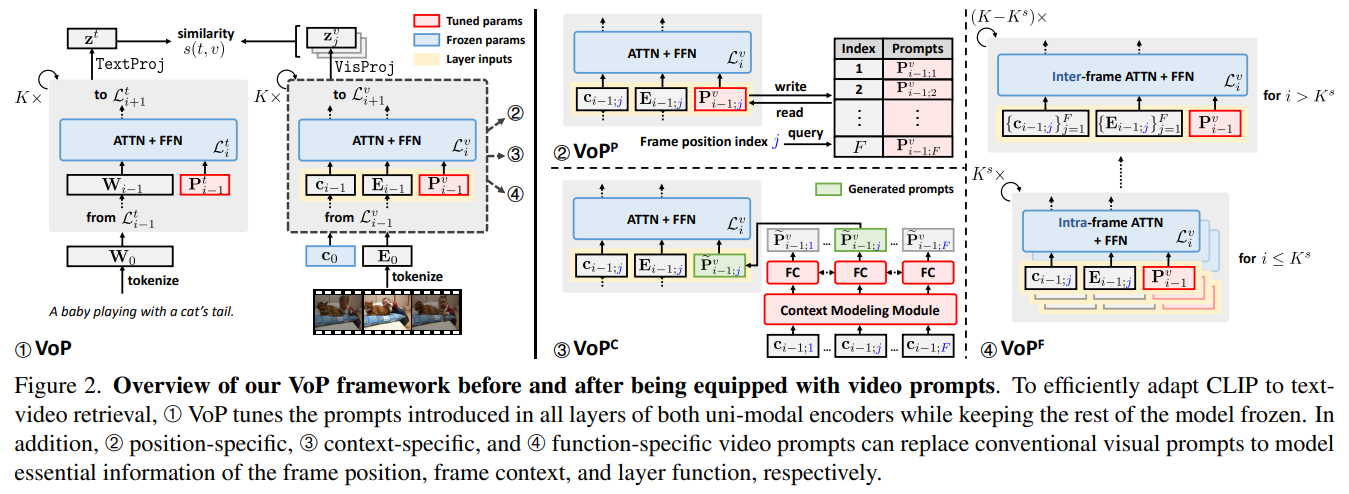
In this work, we propose the **VoP**: Text-**V**ideo C**o**-operative **P**rompt Tuning for efficient tuning on the text-video retrieval task. The proposed VoP is an end-to-end framework with both video & text prompts introducing, which can be regarded as a powerful baseline with only **0.1%** trainable parameters. Further, based on the spatio-temporal characteristics of videos, we develop three novel video prompt mechanisms to improve the performance with different scales of trainable parameters. The basic idea of the VoP enhancement is to model the frame position, frame context, and layer function with specific trainable prompts, respectively. Extensive experiments show that compared to full finetuning, the enhanced VoP achieves a **1.4%** average R@1 gain across five text-video retrieval benchmarks with **6×** less parameter overhead.
## Results
### Main Results
The following results are obtained with a pre-trained CLIP (ViT-B/32). More experimental results can be found in the paper.
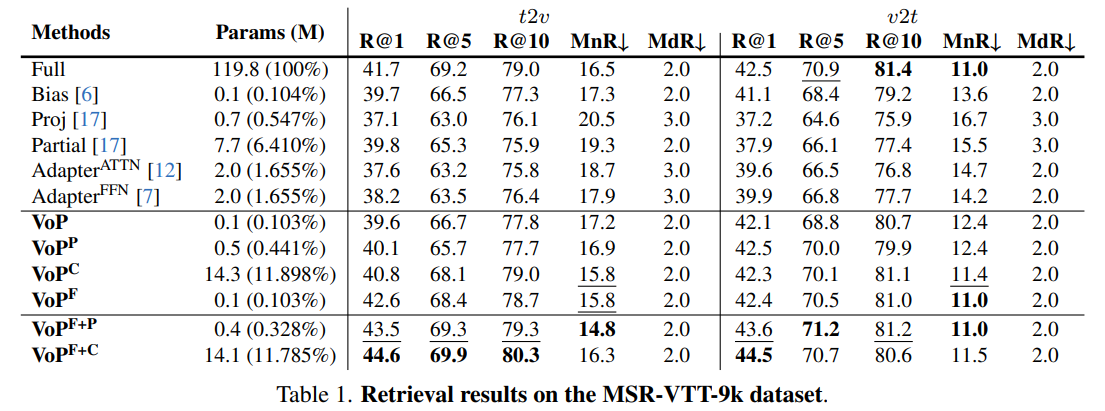
*t2v* and *v2t* retrieval results on MSR-VTT-9k dataset:
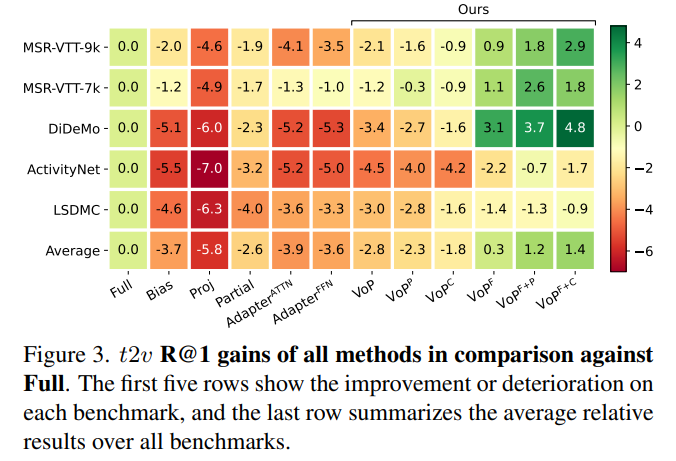
*t2v* relative results on all datasets:
### Qualitative Results

## Citation
If you find this work useful in your research, please cite our paper:
```
@inproceedings{Huang2023VoP,
title={{VoP}: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval},
author={Siteng Huang and Biao Gong and Yulin Pan and Jianwen Jiang and Yiliang Lv and Yuyuan Li and Donglin Wang},
booktitle = {Proceedings of the {IEEE/CVF} Conference on Computer Vision and Pattern Recognition 2023},
month = {June},
year = {2023}
}
```
## Acknowledgement
Our code references the following projects:
* [xpool](https://github.com/layer6ai-labs/xpool)
* [CLIP4Clip](https://github.com/ArrowLuo/CLIP4Clip)