https://github.com/bigscience-workshop/data-preparation
Code used for sourcing and cleaning the BigScience ROOTS corpus
https://github.com/bigscience-workshop/data-preparation
dataset large-language-models multilingual
Last synced: about 1 year ago
JSON representation
Code used for sourcing and cleaning the BigScience ROOTS corpus
- Host: GitHub
- URL: https://github.com/bigscience-workshop/data-preparation
- Owner: bigscience-workshop
- License: apache-2.0
- Created: 2022-04-25T10:08:43.000Z (about 4 years ago)
- Default Branch: main
- Last Pushed: 2023-03-20T17:05:44.000Z (over 3 years ago)
- Last Synced: 2025-04-02T07:08:21.300Z (over 1 year ago)
- Topics: dataset, large-language-models, multilingual
- Language: Jupyter Notebook
- Homepage: https://bigscience.huggingface.co/
- Size: 931 KB
- Stars: 309
- Watchers: 24
- Forks: 40
- Open Issues: 9
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Data prepation
This repository contains all the tools and code used to build the ROOTS dataset produced by the BigScience initiative to train the BLOOM models as well as a reduced version to train the tokenizer.
## General pipeline for the preparation of the ROOTS dataset
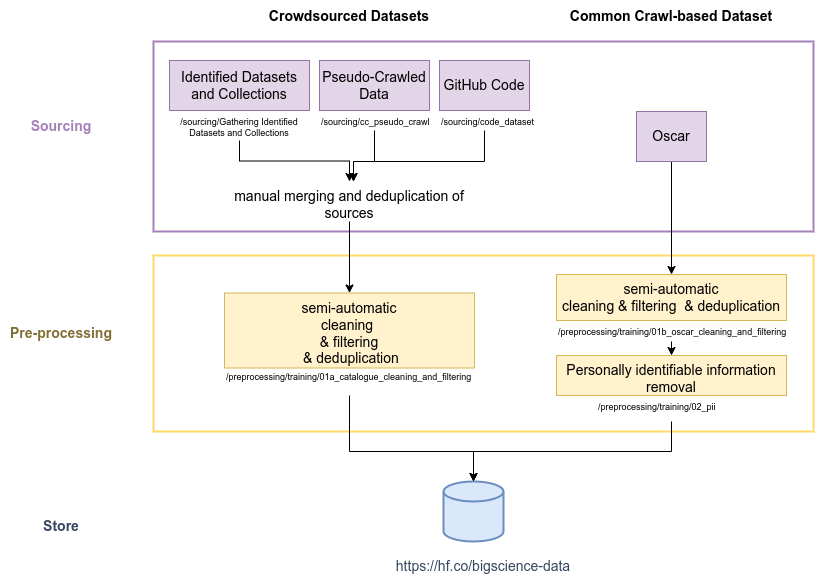
More detail on the process, including the specifics of the *cleaning*, *filtering*, and *deduplication* operations, can be found in Sections 2 "(Crowd)Sourcing a Language Resource Catalogue" and 3 "Processing OSCAR" of our paper [on the ROOTS dataset creation](https://openreview.net/forum?id=UoEw6KigkUn).
## Key resources
### [Code for making the Pseudo-Crawl dataset](sourcing/cc_pseudo_crawl)
### [Filtering library used to filter OSCAR](preprocessing/training/01b_oscar_cleaning_and_filtering)
### [Code used to run preprocessing pipeline on crowdsourced dataset](preprocessing/training/01a_catalogue_cleaning_and_filtering)
### [Code used for the tokenizer's training dataset](preprocessing/tokenizer)
### [Code used for making the analysis and plots for the paper](analysis)
## Citation
```
@inproceedings{
bigscience-roots:2022,
title={The BigScience {ROOTS} Corpus: A 1.6{TB} Composite Multilingual Dataset},
author={Hugo Lauren{\c{c}}on and Lucile Saulnier and Thomas Wang and Christopher Akiki and Albert Villanova del Moral and Teven Le Scao and Leandro Von Werra and Chenghao Mou and Eduardo Gonz{\'a}lez Ponferrada and Huu Nguyen and J{\"o}rg Frohberg and Mario {\v{S}}a{\v{s}}ko and Quentin Lhoest and Angelina McMillan-Major and G{\'e}rard Dupont and Stella Biderman and Anna Rogers and Loubna Ben allal and Francesco De Toni and Giada Pistilli and Olivier Nguyen and Somaieh Nikpoor and Maraim Masoud and Pierre Colombo and Javier de la Rosa and Paulo Villegas and Tristan Thrush and Shayne Longpre and Sebastian Nagel and Leon Weber and Manuel Romero Mu{\~n}oz and Jian Zhu and Daniel Van Strien and Zaid Alyafeai and Khalid Almubarak and Vu Minh Chien and Itziar Gonzalez-Dios and Aitor Soroa and Kyle Lo and Manan Dey and Pedro Ortiz Suarez and Aaron Gokaslan and Shamik Bose and David Ifeoluwa Adelani and Long Phan and Hieu Tran and Ian Yu and Suhas Pai and Jenny Chim and Violette Lepercq and Suzana Ilic and Margaret Mitchell and Sasha Luccioni and Yacine Jernite},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=UoEw6KigkUn}
}
```