https://github.com/bitzhuwei/sharpfiledb
SharpFileDB is a micro database library that uses no SQL, files as storage form and totally C# to implement a CRUD system. SharpFileDB是一个纯C#的无SQL的支持CRUD的小型文件数据库,目标是支持万人级别的应用程序。
https://github.com/bitzhuwei/sharpfiledb
Last synced: 2 months ago
JSON representation
SharpFileDB is a micro database library that uses no SQL, files as storage form and totally C# to implement a CRUD system. SharpFileDB是一个纯C#的无SQL的支持CRUD的小型文件数据库,目标是支持万人级别的应用程序。
- Host: GitHub
- URL: https://github.com/bitzhuwei/sharpfiledb
- Owner: bitzhuwei
- Created: 2015-06-21T11:00:13.000Z (about 10 years ago)
- Default Branch: master
- Last Pushed: 2015-07-14T14:09:08.000Z (almost 10 years ago)
- Last Synced: 2023-02-27T21:03:43.305Z (over 2 years ago)
- Language: C#
- Homepage:
- Size: 6.9 MB
- Stars: 54
- Watchers: 13
- Forks: 16
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# SharpFileDB
SharpFileDB is a micro database library that uses no SQL, files as storage form and totally C# to implement a CRUD system.
SharpFileDB是一个纯C#的无SQL的支持CRUD的小型文件数据库,目标是支持万人级别的应用程序。
小型单文件NoSQL数据库SharpFileDB初步实现
我不是数据库方面的专家,不过还是想做一个小型的数据库,算是一种通过mission impossible进行学习锻炼的方式。我知道这是自不量力,不过还是希望各路大神批评的时候不要人身攻击,谢谢。
SharpFileDB

最近所做的多文件数据库是受(C#实现文件数据库)的启发。后来又发现了(LiteDB),看到了单文件数据库和分页、索引、查询语句等的实现方式,大受启发。不过我仍旧认为LiteDB使用起来有些不顺畅,它的代码组织也不敢完全苟同。所以,我重新设计了一个小型的单文件数据库SharpFileDB:
无需配置服务器。
无需SQL。
100%纯C#开发的一个不到50KB的DLL。
支持事务ACID。
写入失败后可恢复(日志模式)。
可存储任意继承了Table且具有[Serializable]特性的类型(相当于关系数据库的Table)。类型数目不限。
可存储System.Drawing.Image等大型对象。
单文件存储,只要你的硬盘空间够大,理论上能支持的最大长度为long.MaxValue = 9223372036854775807 = 0x7FFFFFFFFFFFFFFF = 8589934591GB = 8388607TB = 8191PB = 7EB的大文件。
每个类型都可以建立多个索引,索引数目不限。只需在属性上加[TableIndex]特性即可实现。
支持通过Lambda表达式进行查询。
开源免费,2300行代码,1000行注释。
附带Demo、可视化的监视工具、可视化的数据库设计器,便于学习、调试和应用。
使用场景

假设已经做好了这样一个单文件数据库,我期望的使用方式是这样的:
1 string fullname = Path.Combine(Environment.CurrentDirectory, "test.db");
2 using (FileDBContext db = new FileDBContext(fullname))
3 {
4 Cat cat = new Cat();
5 string name = "kitty " + random.Next();
6 cat.KittyName = name;
7 cat.Price = random.Next(1, 100);
8
9 db.Insert(cat);
10
11 System.Linq.Expressions.Expression<Func<Cat, bool>> pre = null;
12
13 pre = (x =>
14 (x.KittyName == "kitty" || (x.KittyName == name && x.Id.ToString() != string.Empty))
15 || (x.KittyName.Contains("kitty") && x.Price > 10)
16 );
17
18 IEnumerable<Cat> cats = db.Find<Cat>(pre);
19
20 cats = db.FindAll<Cat>();
21
22 cat.KittyName = "小白 " + random.Next();
23 db.Update(cat);
24
25 db.Delete(cat);
26 }
就像关系型数据库一样,我们可以创建各种Table(例如这里的Cat)。然后直接使用Insert(Table record);插入一条记录。创建自定义Table只需继承Talbe实现自己的class即可。
1 /// <summary>
2 /// 继承此类型以实现您需要的Table。
3 /// </summary>
4 [Serializable]
5 public abstract class Table : ISerializable
6 {
7
8 /// <summary>
9 /// 用以区分每个Table的每条记录。
10 /// This Id is used for diffrentiate instances of 'table's.
11 /// </summary>
12 [TableIndex]// 标记为索引,这是每个表都有的主键。
13 public ObjectId Id { get; internal set; }
14
15 /// <summary>
16 /// 创建一个文件对象,在用<code>FileDBContext.Insert();</code>将此对象保存到数据库之前,此对象的Id为null。
17 /// </summary>
18 public Table() { }
19
20 /// <summary>
21 /// 显示此条记录的Id。
22 /// </summary>
23 /// <returns></returns>
24 public override string ToString()
25 {
26 return string.Format("Id: {0}", this.Id);
27 }
28
29 /// <summary>
30 /// 使用的字符越少,序列化时占用的字节就越少。一个字符都不用最好。
31 /// <para>Using less chars means less bytes after serialization. And "" is allowed.</para>
32 /// </summary>
33 const string strId = "";
34
35 #region ISerializable 成员
36
37 /// <summary>
38 /// This method will be invoked automatically when IFormatter.Serialize() is called.
39 /// <para>You must use <code>base(info, context);</code> in the derived class to feed <see cref="Table"/>'s fields and properties.</para>
40 /// <para>当使用IFormatter.Serialize()时会自动调用此方法。</para>
41 /// <para>继承此类型时,必须在子类型中用<code>base(info, context);</code>来填充<see cref="Table"/>自身的数据。</para>
42 /// </summary>
43 /// <param name="info"></param>
44 /// <param name="context"></param>
45 public virtual void GetObjectData(SerializationInfo info, StreamingContext context)
46 {
47 byte[] value = this.Id.Value;//byte[]比this.Id.ToString()占用的字节少2个字节。
48 info.AddValue(strId, value);
49 }
50
51 #endregion
52
53 /// <summary>
54 /// This method will be invoked automatically when IFormatter.Serialize() is called.
55 /// <para>You must use <code>: base(info, context)</code> in the derived class to feed <see cref="Table"/>'s fields and properties.</para>
56 /// <para>当使用IFormatter.Serialize()时会自动调用此方法。</para>
57 /// <para>继承此类型时,必须在子类型中用<code>: base(info, context)</code>来填充<see cref="Table"/>自身的数据。</para>
58 /// </summary>
59 /// <param name="info"></param>
60 /// <param name="context"></param>
61 protected Table(SerializationInfo info, StreamingContext context)
62 {
63 byte[] value = (byte[])info.GetValue(strId, typeof(byte[]));
64 this.Id = new ObjectId(value);
65 }
66
67 }
这里的Cat定义如下:
1 [Serializable]
2 public class Cat : Table
3 {
4 /// <summary>
5 /// 显示此对象的信息,便于调试。
6 /// </summary>
7 /// <returns></returns>
8 public override string ToString()
9 {
10 return string.Format("{0}: ¥{1}", KittyName, Price);
11 }
12
13 public string KittyName { get; set; }
14
15 public int Price { get; set; }
16
17 public Cat() { }
18
19 const string strKittyName = "N";
20 const string strPrice = "P";
21
22 public override void GetObjectData(System.Runtime.Serialization.SerializationInfo info, System.Runtime.Serialization.StreamingContext context)
23 {
24 base.GetObjectData(info, context);
25
26 info.AddValue(strKittyName, this.KittyName);
27 info.AddValue(strPrice, this.Price);
28 }
29
30 protected Cat(System.Runtime.Serialization.SerializationInfo info, System.Runtime.Serialization.StreamingContext context)
31 : base(info, context)
32 {
33 this.KittyName = info.GetString(strKittyName);
34 this.Price = info.GetInt32(strPrice);
35 }
36
37 }
后面我提供了一个可视化的数据库设计器,你可以像在SQL Server Management里那样设计好你需要的表,即可一键生成相应的数据库项目源码。
从何开始

用C#做一个小型单文件数据库,需要用到.NET Framework提供的这几个类型。
FileStream

文件流用于操作数据库文件。FileStream支持随机读写,并且FileStream.Length属性是long型的,就是说数据库文件最大可以有long.MaxValue个字节,这是超级大的。
使用FileStream的方式是这样的:
1 var fileStream = new FileStream(fullname, FileMode.Open, FileAccess.ReadWrite, FileShare.Read);
这句代码指明:
fullname:打开绝对路径为fullname的文件。
FileMode.Open:如果文件不存在,抛出异常。
FileAccess.ReadWrite:fileStream对象具有读和写文件的权限。
FileShare.Read:其它进程只能读此文件,不能写。我们可以用其它进程来实现容灾备份之类的操作。
BinaryFormatter

读写数据库文件实际上就是反序列化和序列化对象的过程。我在这里详细分析了为什么使用BinaryFormatter。
联合使用FileStream和BinaryFormatter就可以实现操作数据库文件的最基础的功能。
1 /// <summary>
2 /// 使用FileStream和BinaryFormatter做单文件数据库的核心工作流。
3 /// </summary>
4 /// <param name="fullname"></param>
5 public static void TypicalScene(string fullname)
6 {
7 // 初始化。
8 BinaryFormatter formatter = new BinaryFormatter();
9
10 // 打开数据库文件。
11 FileStream fs = new FileStream(fullname, FileMode.Open, FileAccess.ReadWrite, FileShare.Read);
12
13 // 把对象写入数据库。
14 long position = 0;// 指定位置。
15 fs.Seek(position, SeekOrigin.Begin);
16 Object obj = new Object();// 此处可以是任意具有[Serializable]特性的类型。
17 formatter.Serialize(fs, obj);// 把对象序列化并写入文件。
18
19 fs.Flush();
20
21 // 从数据库文件读取对象。
22 fs.Seek(position, SeekOrigin.Begin);// 指定位置。
23 Object deserialized = formatter.Deserialize(fs);// 从文件得到反序列化的对象。
24
25 // 关闭文件流,退出数据库。
26 fs.Close();
27 fs.Dispose();
28 }
简单来说,这就是整个单文件数据库最基本的工作过程。后续的所有设计,目的都在于得到应指定的位置和应读写的对象类型了。能够在合适的位置写入合适的内容,能够通过索引实现快速定位和获取/删除指定的内容,这就是实现单文件数据库要做的第一步。能够实现事务和恢复机制,就是第二步。
MemoryStream

使用MemoryStream是为了先把对象转换成byte[],这样就可以计算其序列化后的长度,然后才能为其安排存储到数据库文件的什么地方。
1 /// <summary>
2 /// 把Table的一条记录转换为字节数组。这个字节数组应该保存到Data页。
3 /// </summary>
4 /// <param name="table"></param>
5 /// <returns></returns>
6 [MethodImpl(MethodImplOptions.AggressiveInlining)]
7 public static byte[] ToBytes(this Table table)
8 {
9 byte[] result;
10 using (MemoryStream ms = new MemoryStream())
11 {
12 Consts.formatter.Serialize(ms, table);
13 if (ms.Length > (long)int.MaxValue)// RULE: 一条记录序列化后最长不能超过int.MaxValue个字节。
14 { throw new Exception(string.Format("Toooo long is the [{0}]", table)); }
15 result = new byte[ms.Length];
16 ms.Seek(0, SeekOrigin.Begin);
17 ms.Read(result, 0, result.Length);
18 }
19
20 return result;
21 }
准备知识
全局唯一编号

写入数据库的每一条记录,都应该有一个全局唯一的编号。(C#实现文件数据库)和(LiteDB)都有一个ObjectId类型,两者也十分相似,且存储它需要的长度也小于.NET Framework自带的Guid,所以就用ObjectId做全局唯一的编号了。


1 /// <summary>
2 /// 用于生成唯一的<see cref="Table"/>编号。
3 /// </summary>
4 [Serializable]
5 public sealed class ObjectId : ISerializable, IComparable<ObjectId>, IComparable
6 {
7 private string _string;
8
9 private ObjectId()
10 {
11 }
12
13 internal ObjectId(string value)
14 : this(DecodeHex(value))
15 {
16 }
17
18 internal ObjectId(byte[] value)
19 {
20 Value = value;
21 }
22
23 internal static ObjectId Empty
24 {
25 get { return new ObjectId("000000000000000000000000"); }
26 }
27
28 internal byte[] Value { get; private set; }
29
30 /// <summary>
31 /// 获取一个新的<see cref="ObjectId"/>。
32 /// </summary>
33 /// <returns></returns>
34 public static ObjectId NewId()
35 {
36 return new ObjectId { Value = ObjectIdGenerator.Generate() };
37 }
38
39 internal static bool TryParse(string value, out ObjectId objectId)
40 {
41 objectId = Empty;
42 if (value == null || value.Length != 24)
43 {
44 return false;
45 }
46
47 try
48 {
49 objectId = new ObjectId(value);
50 return true;
51 }
52 catch (FormatException)
53 {
54 return false;
55 }
56 }
57
58 static byte[] DecodeHex(string value)
59 {
60 if (string.IsNullOrEmpty(value))
61 throw new ArgumentNullException("value");
62
63 var chars = value.ToCharArray();
64 var numberChars = chars.Length;
65 var bytes = new byte[numberChars / 2];
66
67 for (var i = 0; i < numberChars; i += 2)
68 {
69 bytes[i / 2] = Convert.ToByte(new string(chars, i, 2), 16);
70 }
71
72 return bytes;
73 }
74
75 /// <summary>
76 ///
77 /// </summary>
78 /// <returns></returns>
79 public override int GetHashCode()
80 {
81 return Value != null ? ToString().GetHashCode() : 0;
82 }
83
84 /// <summary>
85 /// 显示此对象的信息,便于调试。
86 /// </summary>
87 /// <returns></returns>
88 public override string ToString()
89 {
90 if (_string == null && Value != null)
91 {
92 _string = BitConverter.ToString(Value)
93 .Replace("-", string.Empty)
94 .ToLowerInvariant();
95 }
96
97 return _string;
98 }
99
100 /// <summary>
101 ///
102 /// </summary>
103 /// <param name="obj"></param>
104 /// <returns></returns>
105 public override bool Equals(object obj)
106 {
107 var other = obj as ObjectId;
108 return Equals(other);
109 }
110
111 /// <summary>
112 ///
113 /// </summary>
114 /// <param name="other"></param>
115 /// <returns></returns>
116 public bool Equals(ObjectId other)
117 {
118 return other != null && ToString() == other.ToString();
119 }
120
121 //public static implicit operator string(ObjectId objectId)
122 //{
123 // return objectId == null ? null : objectId.ToString();
124 //}
125
126 //public static implicit operator ObjectId(string value)
127 //{
128 // return new ObjectId(value);
129 //}
130
131 /// <summary>
132 ///
133 /// </summary>
134 /// <param name="left"></param>
135 /// <param name="right"></param>
136 /// <returns></returns>
137 public static bool operator ==(ObjectId left, ObjectId right)
138 {
139 if (ReferenceEquals(left, right))
140 {
141 return true;
142 }
143
144 if (((object)left == null) || ((object)right == null))
145 {
146 return false;
147 }
148
149 return left.Equals(right);
150 }
151
152 /// <summary>
153 ///
154 /// </summary>
155 /// <param name="left"></param>
156 /// <param name="right"></param>
157 /// <returns></returns>
158 public static bool operator !=(ObjectId left, ObjectId right)
159 {
160 return !(left == right);
161 }
162
163 #region ISerializable 成员
164
165 const string strValue = "";
166 void ISerializable.GetObjectData(SerializationInfo info, StreamingContext context)
167 {
168 string value = this.ToString();
169 info.AddValue(strValue, value);
170 }
171
172 #endregion
173
174 private ObjectId(SerializationInfo info, StreamingContext context)
175 {
176 string value = info.GetString(strValue);
177 this.Value = DecodeHex(value);
178 }
179
180
181 #region IComparable<ObjectId> 成员
182
183 /// <summary>
184 /// 根据<see cref="ObjectId.ToString()"/>的值比较两个对象。
185 /// </summary>
186 /// <param name="other"></param>
187 /// <returns></returns>
188 public int CompareTo(ObjectId other)
189 {
190 if (other == null) { return 1; }
191
192 string thisStr = this.ToString();
193 string otherStr = other.ToString();
194 int result = thisStr.CompareTo(otherStr);
195
196 return result;
197 }
198
199 #endregion
200
201 #region IComparable 成员
202
203 /// <summary>
204 /// 根据<see cref="ObjectId.ToString()"/>的值比较两个对象。
205 /// </summary>
206 /// <param name="obj"></param>
207 /// <returns></returns>
208 public int CompareTo(object obj)
209 {
210 ObjectId other = obj as ObjectId;
211 return CompareTo(other);
212 }
213
214 #endregion
215 }
216
217 internal static class ObjectIdGenerator
218 {
219 private static readonly DateTime Epoch =
220 new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc);
221 private static readonly object _innerLock = new object();
222 private static int _counter;
223 private static readonly byte[] _machineHash = GenerateHostHash();
224 private static readonly byte[] _processId =
225 BitConverter.GetBytes(GenerateProcessId());
226
227 internal static byte[] Generate()
228 {
229 var oid = new byte[12];
230 var copyidx = 0;
231
232 Array.Copy(BitConverter.GetBytes(GenerateTime()), 0, oid, copyidx, 4);
233 copyidx += 4;
234
235 Array.Copy(_machineHash, 0, oid, copyidx, 3);
236 copyidx += 3;
237
238 Array.Copy(_processId, 0, oid, copyidx, 2);
239 copyidx += 2;
240
241 Array.Copy(BitConverter.GetBytes(GenerateCounter()), 0, oid, copyidx, 3);
242
243 return oid;
244 }
245
246 private static int GenerateTime()
247 {
248 var now = DateTime.UtcNow;
249 var nowtime = new DateTime(Epoch.Year, Epoch.Month, Epoch.Day,
250 now.Hour, now.Minute, now.Second, now.Millisecond);
251 var diff = nowtime - Epoch;
252 return Convert.ToInt32(Math.Floor(diff.TotalMilliseconds));
253 }
254
255 private static byte[] GenerateHostHash()
256 {
257 using (var md5 = MD5.Create())
258 {
259 var host = Dns.GetHostName();
260 return md5.ComputeHash(Encoding.Default.GetBytes(host));
261 }
262 }
263
264 private static int GenerateProcessId()
265 {
266 var process = Process.GetCurrentProcess();
267 return process.Id;
268 }
269
270 private static int GenerateCounter()
271 {
272 lock (_innerLock)
273 {
274 return _counter++;
275 }
276 }
277 }
ObjectId
使用时只需通过调用ObjectId.NewId();即可获取一个新的编号。
分页机制

磁盘I/O操作每次都是以4KB个字节为单位进行的。所以把单文件数据库划分为一个个长度为4KB的页就很有必要。这一点稍微增加了数据库设计图的复杂程度。由于磁盘I/O所需时间最长,所以对此进行优化是值得的。
你可以随意新建一个TXT文件,在里面写几个字符,保存一下,会看到即使是大小只有1个字节内容的TXT文件,其占用空间也是4KB。

而且所有文件的"占用空间"都是4KB的整数倍。
索引机制

我从LiteDB的文档看到,它用Skip List实现了索引机制,能够快速定位读写一个对象。Skip List是以空间换时间的方式,用扩展了的单链表达到了红黑树的效率,而其代码比红黑树简单得多。要研究、实现红黑树会花费更多时间,所以我效仿LiteDB用Skip List做索引。
关于Skip List大家可以参考这里,有Skip List的实现代码。(还有很多数据结构和算法的C#实现,堪称宝贵)还有这里(http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html)的介绍也很不错。
Skip List的结构如下图所示。

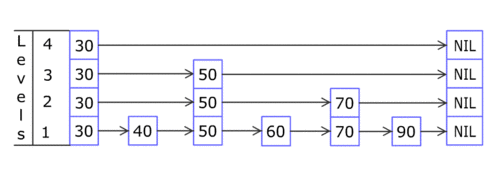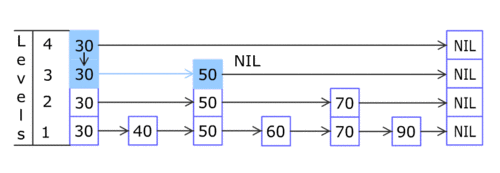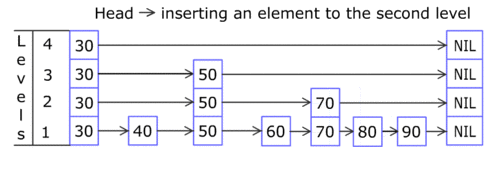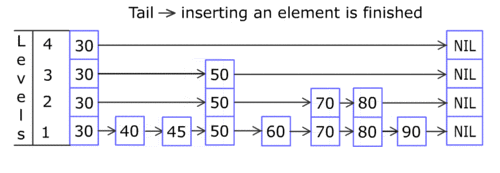
你只需知道Skip List在外部看起来就像一个Dictionary<TKey, TValue>,它是通过Add(TKey key, TValue value);来增加元素的。每个Skip List Node都含有一个key和一个value,而且,同一列上的结点的key和value值都相同。例如,上图的key值为50的三个Skip List Node,其key当然都是50,而其value也必须是相同的。
关于Skip List的详细介绍可参考维基百科。
查询语句

创建数据库、创建表、索引和删除表的语句都已经不需要了。
Lambda表达式可以用作查询语句。再次感谢LiteDB,给了我很多启发。
不利用索引的懒惰方案

解析Lambda表达式的工作量超出我的预期,暂时先用一个懒惰的方案顶替之。LiteDB提供的解析方式也有很大局限,我还要考虑一下如何做Lambda表达式的解析。
1 /// <summary>
2 /// 查找数据库内的某些记录。
3 /// </summary>
4 /// <typeparam name="T"></typeparam>
5 /// <param name="predicate">符合此条件的记录会被取出。</param>
6 /// <returns></returns>
7 public IEnumerable<T> Find<T>(Expression<Func<T, bool>> predicate) where T : Table, new()
8 {
9 if (predicate == null) { throw new ArgumentNullException("predicate"); }
10
11 // 这是没有利用索引的版本。
12 Func<T, bool> func = predicate.Compile();
13 foreach (T item in this.FindAll<T>())
14 {
15 if(func(item))
16 {
17 yield return item;
18 }
19 }
20
21 // TODO: 这是利用索引的版本,尚未实现。
22 //List<T> result = new List<T>();
23
24 //var body = predicate.Body as LambdaExpression;
25 //this.Find(result, body);
26
27 //return result;
28 }
29 /// <summary>
30 /// 查找数据库内所有指定类型的记录。
31 /// </summary>
32 /// <typeparam name="T">要查找的类型。</typeparam>
33 /// <returns></returns>
34 public IEnumerable<T> FindAll<T>() where T:Table, new()
35 {
36 Type type = typeof(T);
37 if (this.tableBlockDict.ContainsKey(type))
38 {
39 TableBlock tableBlock = this.tableBlockDict[type];
40 IndexBlock firstIndex = tableBlock.IndexBlockHead.NextObj;// 第一个索引应该是Table.Id的索引。
41 FileStream fs = this.fileStream;
42
43 SkipListNodeBlock current = firstIndex.SkipListHeadNodes[0]; //currentHeadNode;
44
45 while (current.RightPos != firstIndex.SkipListTailNodePos)
46 {
47 current.TryLoadProperties(fs, SkipListNodeBlockLoadOptions.RightObj);
48 current.RightObj.TryLoadProperties(fs, SkipListNodeBlockLoadOptions.RightObj | SkipListNodeBlockLoadOptions.Value);
49 T item = current.RightObj.Value.GetObject<T>(this);
50
51 yield return item;
52
53 current = current.RightObj;
54 }
55 }
56 }
Lambda表达式

在MSDN上有观察Lambda表达式的介绍。
System.Object
System.Linq.Expressions.Expression
System.Linq.Expressions.BinaryExpression
System.Linq.Expressions.BlockExpression
System.Linq.Expressions.ConditionalExpression
System.Linq.Expressions.ConstantExpression
System.Linq.Expressions.DebugInfoExpression
System.Linq.Expressions.DefaultExpression
System.Linq.Expressions.DynamicExpression
System.Linq.Expressions.GotoExpression
System.Linq.Expressions.IndexExpression
System.Linq.Expressions.InvocationExpression
System.Linq.Expressions.LabelExpression
System.Linq.Expressions.LambdaExpression
System.Linq.Expressions.ListInitExpression
System.Linq.Expressions.LoopExpression
System.Linq.Expressions.MemberExpression
System.Linq.Expressions.MemberInitExpression
System.Linq.Expressions.MethodCallExpression
System.Linq.Expressions.NewArrayExpression
System.Linq.Expressions.NewExpression
System.Linq.Expressions.ParameterExpression
System.Linq.Expressions.RuntimeVariablesExpression
System.Linq.Expressions.SwitchExpression
System.Linq.Expressions.TryExpression
System.Linq.Expressions.TypeBinaryExpression
System.Linq.Expressions.UnaryExpression
这个列表放在这里是为了方便了解lambda表达式都有哪些类型的结点。我还整理了描述表达式目录树的节点的节点类型System.Linq.Expressions. ExpressionType。
1 namespace System.Linq.Expressions
2 {
3 /// <summary>
4 /// 描述表达式目录树的节点的节点类型。
5 /// </summary>
6 public enum ExpressionType
7 {
8 /// <summary>
9 /// 加法运算,如 a + b,针对数值操作数,不进行溢出检查。
10 /// </summary>
11 Add = 0,
12 //
13 /// <summary>
14 /// 加法运算,如 (a + b),针对数值操作数,进行溢出检查。
15 /// </summary>
16 AddChecked = 1,
17 //
18 /// <summary>
19 /// 按位或逻辑 AND 运算,如 C# 中的 (a & b) 和 Visual Basic 中的 (a And b)。
20 /// </summary>
21 And = 2,
22 //
23 /// <summary>
24 /// 条件 AND 运算,它仅在第一个操作数的计算结果为 true 时才计算第二个操作数。 它与 C# 中的 (a && b) 和 Visual Basic 中的 (a AndAlso b) 对应。
25 /// </summary>
26 AndAlso = 3,
27 //
28 /// <summary>
29 /// 获取一维数组长度的运算,如 array.Length。
30 /// </summary>
31 ArrayLength = 4,
32 //
33 /// <summary>
34 /// 一维数组中的索引运算,如 C# 中的 array[index] 或 Visual Basic 中的 array(index)。
35 /// </summary>
36 ArrayIndex = 5,
37 //
38 /// <summary>
39 /// 方法调用,如在 obj.sampleMethod() 表达式中。
40 /// </summary>
41 Call = 6,
42 //
43 /// <summary>
44 /// 表示 null 合并运算的节点,如 C# 中的 (a ?? b) 或 Visual Basic 中的 If(a, b)。
45 /// </summary>
46 Coalesce = 7,
47 //
48 /// <summary>
49 /// 条件运算,如 C# 中的 a > b ? a : b 或 Visual Basic 中的 If(a > b, a, b)。
50 /// </summary>
51 Conditional = 8,
52 //
53 /// <summary>
54 /// 一个常量值。
55 /// </summary>
56 Constant = 9,
57 //
58 /// <summary>
59 /// 强制转换或转换运算,如 C#中的 (SampleType)obj 或 Visual Basic 中的 CType(obj, SampleType)。
60 /// 对于数值转换,如果转换后的值对于目标类型来说太大,这不会引发异常。
61 /// </summary>
62 Convert = 10,
63 //
64 /// <summary>
65 /// 强制转换或转换运算,如 C#中的 (SampleType)obj 或 Visual Basic 中的 CType(obj, SampleType)。
66 /// 对于数值转换,如果转换后的值与目标类型大小不符,则引发异常。
67 /// </summary>
68 ConvertChecked = 11,
69 //
70 /// <summary>
71 /// 除法运算,如 (a / b),针对数值操作数。
72 /// </summary>
73 Divide = 12,
74 //
75 /// <summary>
76 /// 表示相等比较的节点,如 C# 中的 (a == b) 或 Visual Basic 中的 (a = b)。
77 /// </summary>
78 Equal = 13,
79 //
80 /// <summary>
81 /// 按位或逻辑 XOR 运算,如 C# 中的 (a ^ b) 或 Visual Basic 中的 (a Xor b)。
82 /// </summary>
83 ExclusiveOr = 14,
84 //
85 /// <summary>
86 /// “大于”比较,如 (a > b)。
87 /// </summary>
88 GreaterThan = 15,
89 //
90 /// <summary>
91 /// “大于或等于”比较,如 (a >= b)。
92 /// </summary>
93 GreaterThanOrEqual = 16,
94 //
95 /// <summary>
96 /// 调用委托或 lambda 表达式的运算,如 sampleDelegate.Invoke()。
97 /// </summary>
98 Invoke = 17,
99 //
100 /// <summary>
101 /// lambda 表达式,如 C# 中的 a => a + a 或 Visual Basic 中的 Function(a) a + a。
102 /// </summary>
103 Lambda = 18,
104 //
105 /// <summary>
106 /// 按位左移运算,如 (a << b)。
107 /// </summary>
108 LeftShift = 19,
109 //
110 /// <summary>
111 /// “小于”比较,如 (a < b)。
112 /// </summary>
113 LessThan = 20,
114 //
115 /// <summary>
116 /// “小于或等于”比较,如 (a <= b)。
117 /// </summary>
118 LessThanOrEqual = 21,
119 //
120 /// <summary>
121 /// 创建新的 System.Collections.IEnumerable 对象并从元素列表中初始化该对象的运算,如 C# 中的 new List<SampleType>(){
122 /// a, b, c } 或 Visual Basic 中的 Dim sampleList = { a, b, c }。
123 /// </summary>
124 ListInit = 22,
125 //
126 /// <summary>
127 /// 从字段或属性进行读取的运算,如 obj.SampleProperty。
128 /// </summary>
129 MemberAccess = 23,
130 //
131 /// <summary>
132 /// 创建新的对象并初始化其一个或多个成员的运算,如 C# 中的 new Point { X = 1, Y = 2 } 或 Visual Basic 中的
133 /// New Point With {.X = 1, .Y = 2}。
134 /// </summary>
135 MemberInit = 24,
136 //
137 /// <summary>
138 /// 算术余数运算,如 C# 中的 (a % b) 或 Visual Basic 中的 (a Mod b)。
139 /// </summary>
140 Modulo = 25,
141 //
142 /// <summary>
143 /// 乘法运算,如 (a * b),针对数值操作数,不进行溢出检查。
144 /// </summary>
145 Multiply = 26,
146 //
147 /// <summary>
148 /// 乘法运算,如 (a * b),针对数值操作数,进行溢出检查。
149 /// </summary>
150 MultiplyChecked = 27,
151 //
152 /// <summary>
153 /// 算术求反运算,如 (-a)。 不应就地修改 a 对象。
154 /// </summary>
155 Negate = 28,
156 //
157 /// <summary>
158 /// 一元加法运算,如 (+a)。 预定义的一元加法运算的结果是操作数的值,但用户定义的实现可以产生特殊结果。
159 /// </summary>
160 UnaryPlus = 29,
161 //
162 /// <summary>
163 /// 算术求反运算,如 (-a),进行溢出检查。 不应就地修改 a 对象。
164 /// </summary>
165 NegateChecked = 30,
166 //
167 /// <summary>
168 /// 调用构造函数创建新对象的运算,如 new SampleType()。
169 /// </summary>
170 New = 31,
171 //
172 /// <summary>
173 /// 创建新的一维数组并从元素列表中初始化该数组的运算,如 C# 中的 new SampleType[]{a, b, c} 或 Visual Basic
174 /// 中的 New SampleType(){a, b, c}。
175 /// </summary>
176 NewArrayInit = 32,
177 //
178 /// <summary>
179 /// 创建新数组(其中每个维度的界限均已指定)的运算,如 C# 中的 new SampleType[dim1, dim2] 或 Visual Basic
180 /// 中的 New SampleType(dim1, dim2)。
181 /// </summary>
182 NewArrayBounds = 33,
183 //
184 /// <summary>
185 /// 按位求补运算或逻辑求反运算。 在 C# 中,它与整型的 (~a) 和布尔值的 (!a) 等效。 在 Visual Basic 中,它与 (Not
186 /// a) 等效。 不应就地修改 a 对象。
187 /// </summary>
188 Not = 34,
189 //
190 /// <summary>
191 /// 不相等比较,如 C# 中的 (a != b) 或 Visual Basic 中的 (a <> b)。
192 /// </summary>
193 NotEqual = 35,
194 //
195 /// <summary>
196 /// 按位或逻辑 OR 运算,如 C# 中的 (a | b) 或 Visual Basic 中的 (a Or b)。
197 /// </summary>
198 Or = 36,
199 //
200 /// <summary>
201 /// 短路条件 OR 运算,如 C# 中的 (a || b) 或 Visual Basic 中的 (a OrElse b)。
202 /// </summary>
203 OrElse = 37,
204 //
205 /// <summary>
206 /// 对在表达式上下文中定义的参数或变量的引用。 有关更多信息,请参见 System.Linq.Expressions.ParameterExpression。
207 /// </summary>
208 Parameter = 38,
209 //
210 /// <summary>
211 /// 对某个数字进行幂运算的数学运算,如 Visual Basic 中的 (a ^ b)。
212 /// </summary>
213 Power = 39,
214 //
215 /// <summary>
216 /// 具有类型为 System.Linq.Expressions.Expression 的常量值的表达式。 System.Linq.Expressions.ExpressionType.Quote
217 /// 节点可包含对参数的引用,这些参数在该节点表示的表达式的上下文中定义。
218 /// </summary>
219 Quote = 40,
220 //
221 /// <summary>
222 /// 按位右移运算,如 (a >> b)。
223 /// </summary>
224 RightShift = 41,
225 //
226 /// <summary>
227 /// 减法运算,如 (a - b),针对数值操作数,不进行溢出检查。
228 /// </summary>
229 Subtract = 42,
230 //
231 /// <summary>
232 /// 算术减法运算,如 (a - b),针对数值操作数,进行溢出检查。
233 /// </summary>
234 SubtractChecked = 43,
235 //
236 /// <summary>
237 /// 显式引用或装箱转换,其中如果转换失败则提供 null,如 C# 中的 (obj as SampleType) 或 Visual Basic 中的
238 /// TryCast(obj, SampleType)。
239 /// </summary>
240 TypeAs = 44,
241 //
242 /// <summary>
243 /// 类型测试,如 C# 中的 obj is SampleType 或 Visual Basic 中的 TypeOf obj is SampleType。
244 /// </summary>
245 TypeIs = 45,
246 //
247 /// <summary>
248 /// 赋值运算,如 (a = b)。
249 /// </summary>
250 Assign = 46,
251 //
252 /// <summary>
253 /// 表达式块。
254 /// </summary>
255 Block = 47,
256 //
257 /// <summary>
258 /// 调试信息。
259 /// </summary>
260 DebugInfo = 48,
261 //
262 /// <summary>
263 /// 一元递减运算,如 C# 和 Visual Basic 中的 (a - 1)。 不应就地修改 a 对象。
264 /// </summary>
265 Decrement = 49,
266 //
267 /// <summary>
268 /// 动态操作。
269 /// </summary>
270 Dynamic = 50,
271 //
272 /// <summary>
273 /// 默认值。
274 /// </summary>
275 Default = 51,
276 //
277 /// <summary>
278 /// 扩展表达式。
279 /// </summary>
280 Extension = 52,
281 //
282 /// <summary>
283 /// “跳转”表达式,如 C# 中的 goto Label 或 Visual Basic 中的 GoTo Label。
284 /// </summary>
285 Goto = 53,
286 //
287 /// <summary>
288 /// 一元递增运算,如 C# 和 Visual Basic 中的 (a + 1)。 不应就地修改 a 对象。
289 /// </summary>
290 Increment = 54,
291 //
292 /// <summary>
293 /// 索引运算或访问使用参数的属性的运算。
294 /// </summary>
295 Index = 55,
296 //
297 /// <summary>
298 /// 标签。
299 /// </summary>
300 Label = 56,
301 //
302 /// <summary>
303 /// 运行时变量的列表。 有关更多信息,请参见 System.Linq.Expressions.RuntimeVariablesExpression。
304 /// </summary>
305 RuntimeVariables = 57,
306 //
307 /// <summary>
308 /// 循环,如 for 或 while。
309 /// </summary>
310 Loop = 58,
311 //
312 /// <summary>
313 /// 多分支选择运算,如 C# 中的 switch 或 Visual Basic 中的 Select Case。
314 /// </summary>
315 Switch = 59,
316 //
317 /// <summary>
318 /// 引发异常的运算,如 throw new Exception()。
319 /// </summary>
320 Throw = 60,
321 //
322 /// <summary>
323 /// try-catch 表达式。
324 /// </summary>
325 Try = 61,
326 //
327 /// <summary>
328 /// 取消装箱值类型运算,如 MSIL 中的 unbox 和 unbox.any 指令。
329 /// </summary>
330 Unbox = 62,
331 //
332 /// <summary>
333 /// 加法复合赋值运算,如 (a += b),针对数值操作数,不进行溢出检查。
334 /// </summary>
335 AddAssign = 63,
336 //
337 /// <summary>
338 /// 按位或逻辑 AND 复合赋值运算,如 C# 中的 (a &= b)。
339 /// </summary>
340 AndAssign = 64,
341 //
342 /// <summary>
343 /// 除法复合赋值运算,如 (a /= b),针对数值操作数。
344 /// </summary>
345 DivideAssign = 65,
346 //
347 /// <summary>
348 /// 按位或逻辑 XOR 复合赋值运算,如 C# 中的 (a ^= b)。
349 /// </summary>
350 ExclusiveOrAssign = 66,
351 //
352 /// <summary>
353 /// 按位左移复合赋值运算,如 (a <<= b)。
354 /// </summary>
355 LeftShiftAssign = 67,
356 //
357 /// <summary>
358 /// 算术余数复合赋值运算,如 C# 中的 (a %= b)。
359 /// </summary>
360 ModuloAssign = 68,
361 //
362 /// <summary>
363 /// 乘法复合赋值运算,如 (a *= b),针对数值操作数,不进行溢出检查。
364 /// </summary>
365 MultiplyAssign = 69,
366 //
367 /// <summary>
368 /// 按位或逻辑 OR 复合赋值运算,如 C# 中的 (a |= b)。
369 /// </summary>
370 OrAssign = 70,
371 //
372 /// <summary>
373 /// 对某个数字进行幂运算的复合赋值运算,如 Visual Basic 中的 (a ^= b)。
374 /// </summary>
375 PowerAssign = 71,
376 //
377 /// <summary>
378 /// 按位右移复合赋值运算,如 (a >>= b)。
379 /// </summary>
380 RightShiftAssign = 72,
381 //
382 /// <summary>
383 /// 减法复合赋值运算,如 (a -= b),针对数值操作数,不进行溢出检查。
384 /// </summary>
385 SubtractAssign = 73,
386 //
387 /// <summary>
388 /// 加法复合赋值运算,如 (a += b),针对数值操作数,进行溢出检查。
389 /// </summary>
390 AddAssignChecked = 74,
391 //
392 /// <summary>
393 /// 乘法复合赋值运算,如 (a *= b),针对数值操作数,进行溢出检查。
394 /// </summary>
395 MultiplyAssignChecked = 75,
396 //
397 /// <summary>
398 /// 减法复合赋值运算,如 (a -= b),针对数值操作数,进行溢出检查。
399 /// </summary>
400 SubtractAssignChecked = 76,
401 //
402 /// <summary>
403 /// 一元前缀递增,如 (++a)。 应就地修改 a 对象。
404 /// </summary>
405 PreIncrementAssign = 77,
406 //
407 /// <summary>
408 /// 一元前缀递减,如 (--a)。 应就地修改 a 对象。
409 /// </summary>
410 PreDecrementAssign = 78,
411 //
412 /// <summary>
413 /// 一元后缀递增,如 (a++)。 应就地修改 a 对象。
414 /// </summary>
415 PostIncrementAssign = 79,
416 //
417 /// <summary>
418 /// 一元后缀递减,如 (a--)。 应就地修改 a 对象。
419 /// </summary>
420 PostDecrementAssign = 80,
421 //
422 /// <summary>
423 /// 确切类型测试。
424 /// </summary>
425 TypeEqual = 81,
426 //
427 /// <summary>
428 /// 二进制反码运算,如 C# 中的 (~a)。
429 /// </summary>
430 OnesComplement = 82,
431 //
432 /// <summary>
433 /// true 条件值。
434 /// </summary>
435 IsTrue = 83,
436 //
437 /// <summary>
438 /// false 条件值。
439 /// </summary>
440 IsFalse = 84,
441 }
442 }
ExpressionType
在查询条件方面,要做的就是解析其中一些类型的表达式。
常用表达式举例

下面列举出常用的查询语句。
1 System.Linq.Expressions.Expression<Func<Cat, bool>> pre = null;
2
3 pre = x => x.Price == 10;
4 pre = x => x.Price < 10;
5 pre = x => x.Price > 10;
6 pre = x => x.Price < 10 || x.Price > 20;
7 pre = x => 10 < x.Price && x.Price < 20;
8 pre = x => x.KittyName.Contains("2");
9 pre = x => x.KittyName.StartsWith("kitty");
10 pre = x => x.KittyName.EndsWith("2");
数据库文件的逻辑结构
块(Block)

数据库文件中要保存所有的表(Table)信息、各个表(Table)的索引(Index)信息、各个索引下的Skip List结点(Skip List Node)信息、各个Skip List Node的key和value(这是所有的数据库记录对象所在的位置)信息和所有的数据库记录。我们为不同种类的的信息分别设计一个类型,称为XXXBlock,它们都继承抽象类型Block。我们还规定,不同类型的Block只能存放在相应类型的页里(只有一个例外)。这样似乎效率更高。

文件链表

一个数据库,会有多个表(Table)。数据库里的表的数量随时会增加减少。要想把多个表存储到文件里,以后还能全部读出来,最好使用链表结构。我们用TableBlock描述存储到数据库文件里的一个表(Table)。TableBlock是在文件中的一个链表结点,其NextPos是指向文件中的某个位置的指针。只要有NextPos,就可以反序列化出NextObj,也就是下一个TableBlock。我把这种在文件中存在的链表称为文件链表。以前所见所用的链表则是内存链表。
一个表里,会有多个索引(Index),类似的,IndexBlock也是一个文件链表。
SkipListNodeBlock存储的是Skip List的一个结点,而Skip List的结点有Down和Right两个指针,所以SkipListNodeBlock要存储两个指向文件中某处位置的指针DownPos和RightPos。就是说,SkipListNodeBlock是一个扩展了的文件链表。
了解了这些概念,就可以继续设计了。
Block

任何一个块,都必须知道自己应该存放到数据库文件的位置(ThisPos)。为了能够进行序列化和反序列化,都要有[Serializable]特性。为了控制序列化和反序列化过程,要实现ISerializable接口。
1 /// <summary>
2 /// 存储到数据库文件的一块内容。
3 /// </summary>
4 [Serializable]
5 public abstract class Block : ISerializable
6 {
7
8 #if DEBUG
9
10 /// <summary>
11 /// 创建新<see cref="Block"/>时应设置其<see cref="Block.blockID"/>为计数器,并增长此计数器值。
12 /// </summary>
13 internal static long IDCounter = 0;
14
15 /// <summary>
16 /// 用于给此块标记一个编号,仅为便于调试之用。
17 /// </summary>
18 public long blockID;
19 #endif
20
21 /// <summary>
22 /// 此对象自身在数据库文件中的位置。为0时说明尚未指定位置。只有<see cref="DBHeaderBlock"/>的位置才应该为0。
23 /// <para>请注意在读写时设定此值。</para>
24 /// </summary>
25 public long ThisPos { get; set; }
26
27 /// <summary>
28 /// 存储到数据库文件的一块内容。
29 /// </summary>
30 public Block()
31 {
32 #if DEBUG
33 this.blockID = IDCounter++;
34 #endif
35 BlockCache.AddFloatingBlock(this);
36 }
37
38 #if DEBUG
39 const string strBlockID = "";
40 #endif
41
42 #region ISerializable 成员
43
44 /// <summary>
45 /// 序列化时系统会调用此方法。
46 /// </summary>
47 /// <param name="info"></param>
48 /// <param name="context"></param>
49 public virtual void GetObjectData(SerializationInfo info, StreamingContext context)
50 {
51 #if DEBUG
52 info.AddValue(strBlockID, this.blockID);
53 #endif
54 }
55
56 #endregion
57
58 /// <summary>
59 /// BinaryFormatter会通过调用此方法来反序列化此块。
60 /// </summary>
61 /// <param name="info"></param>
62 /// <param name="context"></param>
63 protected Block(SerializationInfo info, StreamingContext context)
64 {
65 #if DEBUG
66 this.blockID = info.GetInt64(strBlockID);
67 #endif
68 }
69
70 /// <summary>
71 /// 显示此块的信息,便于调试。
72 /// </summary>
73 /// <returns></returns>
74 public override string ToString()
75 {
76 #if DEBUG
77 return string.Format("{0}: ID:{1}, Pos: {2}", this.GetType().Name, this.blockID, this.ThisPos);
78 #else
79 return string.Format("{0}: Pos: {1}", this.GetType().Name, this.ThisPos);
80 #endif
81 }
82
83 /// <summary>
84 /// 安排所有文件指针。如果全部安排完毕,返回true,否则返回false。
85 /// </summary>
86 /// <returns></returns>
87 public abstract bool ArrangePos();
88 }
DBHeaderBlock

这是整个数据库的头部,用于保存在数据库范围内的全局变量。它在整个数据库中只有一个,并且放在数据库的第一页(0~4095字节里)。
TableBlock

TableBlock存放某种类型的表(Table)的信息,包括索引的头结点位置和下一个TableBlock的位置。前面说过,TableBlock是内存链表的一个结点。链表最好有个头结点,头结点不存储具有业务价值的数据,但是它会为编码提供方便。考虑到数据库的第一页只存放着一个DBHeaderBlock,我们就把TableBlock的头结点紧挨着放到DBHeaderBlock后面。这就是上面所说的唯一的例外。由于TableBlock的头结点不会移动位置,其序列化后的字节数也不会变,所以放这里是没有问题的。
IndexBlock

IndexBlock存储Table的一个索引。IndexBlock也是内存链表的一个结点。而它内部含有指向SkipListNodeBlock的指针,所以,实际上IndexBlock就充当了SkipList。
SkipListNodeBlock

如前所述,这是一个扩展了的文件链表的结点。此结点的key和value都是指向实际数据的文件指针。如果直接保存实际数据,那么每个结点都保存一份完整的数据会造成很大的浪费。特别是value,如果value里有一个序列化了的图片,那是不可想象的。而且这样一来,所有的SkipListNodeBlock序列化的长度都是相同的。
DataBlock

DataBlock也是文件链表的一个结点。由于某些数据库记录会很大(比如要存储一个System.Drawing.Image),一个页只有4KB,无法放下。所以可能需要把一条记录划分为多个数据块,放到多个DataBlock里。也就是说,一个数据库记录是用一个链表保存的。
PageHeaderBlock

为了以后管理页(申请新页、释放不再使用的页、申请一定长度的空闲空间),我们在每个页的起始位置都放置一个PageHeaderBlock,用来保存此页的状态(可以字节数等)。并且,每个页都包含一个指向下一相同类型的页的位置的文件指针。这样,所有存放TableBlock的页就成为一个文件链表,所有存放IndexBlock的页就成为另一个文件链表,所有存放SkipListNodeBlock的页也成为一个文件链表,所有存放DataBlock的页也一样。
另外,在删除某些记录后,有的页里存放的块可能为0,这时就成为一个空白页(Empty Page),所以我们还要把这些空白页串联成一个文件链表。
总之,文件里的链表关系无处不在。
块(Block)在数据库文件里

下面是我画的一个数据库文件的逻辑上的结构图。它展示了各种类型的块在数据库文件里的生存状态。
首先,刚刚创建一个数据库文件时,文件里是这样的:

当前只有一个DBHeaderBlock和一个TableBlock(作为头结点)。
注意:此时我们忽略"页"这个概念,所以在每个页最开始处的PageHeaderBlock就不考虑了。
之后我们Insert一条记录,这会在数据库里新建一个表及其索引信息,然后插入此记录。指向完毕后,数据库文件里就是这样的。

之前的TableBlock头结点指向了新建的TableBlock的位置,新建的TableBlock创建了自己的索引。
索引有两个结点,上面的那个是索引的头结点,其不包含有业务价值的信息,只指向下一个索引结点。
下一个索引结点是第一个有业务意义的索引结点,也是一个存在于文件中的SkipList,它有自己的一群SkipListNodeBlock。在插入第一条记录前,这群SkipListNodeBlock只有竖直方向的那5个(实际上我在数据库文件里设定的是32个,不过没法画那么多,就用5个指代了)。
现在表和索引创建完毕,开始插入第一条记录。这会随机创建若干个(这里是2个)SkipListNodeBlock(这是Skip List数据结构的特性,具体请参考维基百科。这两个SkipListNodeBlock的keyPos和valuePos都指向了key和value所在的DataBlock的位置。用于存储value的DataBlock有2个结点,说明value(数据库记录序列化后的字节数)比较大,一个页占不下。
这就是我们期望的情况。为了实现这种文件链表,还需要后续一些遍历操作。我们将结合事务来完成它。
如果你感兴趣,下面是继续插入第二条记录后的情况:

注:为了避免图纸太乱,我只画出了最下面的K1, V1和K2, V2的指针指向DataBlock。实际上,各个K1, V1和K2, V2都是指向DataBlock的。
为块(Block)安排其在文件中的位置

根据依赖关系依次分配
新创建一个Block时,其在数据库文件中的位置(Block.ThisPos)都没有指定,那么在其它Block中指向它的那些字段/属性值就无法确定。我们通过两个步骤来解决此问题。
首先,我们给每个文件链表结点的NextPos都配备一个对应的NextObj。就是说,新创建的Block虽然在文件链表方面还没有安排好指针,但是在内存链表方面已经安排好了。
然后,等所需的所有Block都创建完毕,遍历这些Block,那些在内存链表中处于最后一个的结点,其字段/属性值不依赖其它Block的位置,因此可以直接为其分配好在文件里的位置和空间。之后再次遍历这些Block,那些依赖最后一个结点的结点,此时也就可以为其设置字段/属性值了。以此类推,多次遍历,直到所有Block的字段/属性值都设置完毕。
1 // 给所有的块安排数据库文件中的位置。
2 List<Block> arrangedBlocks = new List<Block>();
3 while (arrangedBlocks.Count < this.blockList.Count)
4 {
5 for (int i = this.blockList.Count - 1; i >= 0; i--)// 后加入列表的先处理。
6 {
7 Block block = this.blockList[i];
8 if (arrangedBlocks.Contains(block)) { continue; }
9 bool done = block.ArrangePos();
10 if (done)
11 {
12 if (block.ThisPos == 0)
13 {
14 byte[] bytes = block.ToBytes();
15 if (bytes.Length > Consts.maxAvailableSpaceInPage)
16 { throw new Exception("Block size is toooo large!"); }
17 AllocPageTypes pageType = block.BelongedPageType();
18 AllocatedSpace space = this.fileDBContext.Alloc(bytes.LongLength, pageType);
19 block.ThisPos = space.position;
20 }
21
22 arrangedBlocks.Add(block);
23 }
24 }
25 }
我们要为不同类型的块执行各自的字段/属性值的设置方法,通过继承Block基类的abstract bool ArrangePos();来实现。实际上,只要添加到blockList里的顺序得当,只需一次遍历即可完成所有的自动/属性值的设置。
DBHeaderBlock
此类型的字段/属性值不依赖其它任何Block,永远都是实时分配完成的。
1 internal override bool ArrangePos()
2 {
3 return true;// 此类型比较特殊,应该在更新时立即指定各项文件指针。
4 }
TableBlock
作为头结点的那个TableBlock不含索引,因此其字段/属性值不需设置。其它TableBlock则需要保存索引头结点的位置。
作为链表的最后一个结点的那个TableBlock的字段/属性值不依赖其它TableBlock的位置,其它TableBLock则需要其下一个TableBlock的位置。这一规则对每个文件链表都适用。
1 public override bool ArrangePos()
2 {
3 bool allArranged = true;
4
5 if (this.IndexBlockHead != null)// 如果IndexBlockHead == null,则说明此块为TableBlock的头结点。头结点是不需要持有索引块的。
6 {
7 if (this.IndexBlockHead.ThisPos != 0)
8 { this.IndexBlockHeadPos = this.IndexBlockHead.ThisPos; }
9 else
10 { allArranged = false; }
11 }
12
13 if (this.NextObj != null)
14 {
15 if (this.NextObj.ThisPos != 0)
16 { this.NextPos = this.NextObj.ThisPos; }
17 else
18 { allArranged = false; }
19 }
20
21 return allArranged;
22 }
IndexBlock
IndexBlock也是文件链表的一个结点,其字段/属性值的设置方式与TableBlock相似。
1 public override bool ArrangePos()
2 {
3 bool allArranged = true;
4
5 if (this.SkipListHeadNodes != null)// 如果这里的SkipListHeadNodes == null,则说明此索引块是索引链表里的头结点。头结点是不需要SkipListHeadNodes有数据的。
6 {
7 int length = this.SkipListHeadNodes.Length;
8 if (length == 0)
9 { throw new Exception("SKip List's head nodes has 0 element!"); }
10 long pos = this.SkipListHeadNodes[length - 1].ThisPos;
11 if (pos != 0)
12 { this.SkipListHeadNodePos = pos; }
13 else
14 { allArranged = false; }
15 }
16
17 if (this.SkipListTailNode != null)// 如果这里的SkipListTailNodes == null,则说明此索引块是索引链表里的头结点。头结点是不需要SkipListTailNodes有数据的。
18 {
19 long pos = this.SkipListTailNode.ThisPos;
20 if (pos != 0)
21 { this.SkipListTailNodePos = pos; }
22 else
23 { allArranged = false; }
24 }
25
26 if (this.NextObj != null)
27 {
28 if (this.NextObj.ThisPos != 0)
29 { this.NextPos = this.NextObj.ThisPos; }
30 else
31 { allArranged = false; }
32 }
33
34 return allArranged;
35 }
SkipListNodeBlock
SkipListNodeBlock是扩展了的文件链表,关于指向下一结点的指针的处理与前面类似。作为头结点的SkipListNodeBlock的Key和Value都是null,是不依赖其它Block的。非头结点的SkipListNodeBlock的Key和Value则依赖保存着序列化后的Key和Value的DataBlock。
1 public override bool ArrangePos()
2 {
3 bool allArranged = true;
4
5 if (this.Key != null)
6 {
7 if (this.Key.ThisPos != 0)
8 { this.KeyPos = this.Key.ThisPos; }
9 else
10 { allArranged = false; }
11 }
12
13 if (this.Value != null)
14 {
15 if (this.Value[0].ThisPos != 0)
16 { this.ValuePos = this.Value[0].ThisPos; }
17 else
18 { allArranged = false; }
19 }
20
21 if (this.DownObj != null)// 此结点不是最下方的结点。
22 {
23 if (this.DownObj.ThisPos != 0)
24 { this.DownPos = this.DownObj.ThisPos; }
25 else
26 { allArranged = false; }
27 }
28
29 if (this.RightObj != null)// 此结点不是最右方的结点。
30 {
31 if (this.RightObj.ThisPos != 0)
32 { this.RightPos = this.RightObj.ThisPos; }
33 else
34 { allArranged = false; }
35 }
36
37 return allArranged;
38 }
DataBlock
DataBlock就是一个很单纯的文件链表结点。
1 public override bool ArrangePos()
2 {
3 bool allArranged = true;
4
5 if (NextObj != null)
6 {
7 if (NextObj.ThisPos != 0)
8 { this.NextPos = NextObj.ThisPos; }
9 else
10 { allArranged = false; }
11 }
12
13 return allArranged;
14 }
PageHeaderBlock
此类型只在创建新页和申请已有页空间时出现,不会参与上面各类Block的位置分配,而是在创建时就为其安排好NextPagePos等属性。
1 internal override bool ArrangePos()
2 {
3 return true;// 此类型比较特殊,应该在创建时就为其安排好NextPagePos等属性。
4 }
Demo和工具

为了方便调试和使用SharpFileDB,我做了下面这些工具和示例Demo。
Demo:MyNote

这是一个非常简单的Demo,实现一个简单的便签列表,演示了如何使用SharpFileDB。虽然界面不好看,但是用作Demo也不应该有太多的无关代码。

查看数据库状态

为了能够直观地查看数据库的状态(包含哪些表、索引、数据记录),方便调试,这里顺便提供一个Winform程序"SharpFileDB Viewer"。这样可以看到数据库的几乎全部信息,调试起来就方便多了。
点击"Refresh"会重新加载所有的表、索引和记录信息,简单粗暴。

点击"Skip Lists"会把数据库里所有表的所有索引的所有结点和所有数据都画到BMP图片上。比如上面看到的MyNote.db的索引分别情况如下图所示。

此图绘制了Note表的唯一一个索引和表里的全部记录(共10条)。
由于为Skip List指定了最大层数为8,且现在数据库里只有10条记录,所以图示上方比较空旷。
下面是局部视图,看得比较清楚。

点击"Blocks"会把数据库各个页上包含的各个块的占用情况画到多个宽为4096高为100的BMP图片上。例如下面6张图是添加了一个表、一个索引和一条记录后,数据库文件的全部6个页的情况。






如上图所示,每一页头部都含有一个PageHeaderBlock,用浅绿色表示。
第一页还有一个数据库头部DBHeaderBlock(用青紫色表示)和一个TableBlock头结点(用橙色表示)。第六页也有一个TableBlock,它代表目前数据库的唯一一个表。Table头结点的TableType属性是空的,所以其长度比第六页的TableBlock要短。这些图片是完全准确地依照各个Block在数据库文件中存储的位置和长度绘制的。
第二页是2个DataBlock,用金色表示。(DataBlock里存放的才是有业务价值的数据,所以是金子的颜色)
第三、第四页存放的都是SkipListNodeBlock(用绿色表示)。可见索引是比较占地方的。
第五页存放了两个IndexBlock(其中一个是IndexBlock的头结点),用灰色表示。
这些图片就比前面手工画的草图好看多了。
以后有时间我把这些图片画到Form上,当鼠标停留在一个块上时,会显示此块的具体信息(如位置、长度、类型、相关联的块等),那就更方便监视数据库的状态了。
后续我会根据需要增加显示更多信息的功能。
可视化的数据库设计器

如果能像MSSQLServer那样用可视化的方法创建自定义表,做成自己的数据库,那就最好了。所以我写了这样一个可视化的数据库设计器,你可以用可视化方式设计你的数据库,然后一键生成所有代码。

规则/坑

各种各样的库、工具包都有一些隐晦的规则,一旦触及就会引发各种奇怪的问题。这种规则其实就是坑。SharpFileDB尽可能不设坑或不设深坑。那些实在无法阻挡的坑,我就让它浅浅地、明显地存在着,即使掉进去了也能马上跳出来。另外,通过使用可视化的设计器,还可以自动避免掉坑里,因为设计器在生成代码前是会提醒你是否已经一脚进坑了。
SharpFileDB有如下几条规则(几个坑)你需要知道:
继承Table的表类型序列化后不能太大

你设计的Table类型序列化后的长度不能超过Int32.MaxValue个字节(= 2097151KB = 2047MB ≈2GB)。这个坑够浅了吧。如果一个对象的能占据2GB,那早就不该用SharpFileDB了。所以这个坑应该不会有人踩到。
只能在属性上添加索引

索引必须加在属性上,否则无效。为什么呢?因为我在实现SharpFileDB的时候只检测了表类型的各个PropertyInfo是否附带[TableIndex]特性。我想,这算是人为赋予属性的一种荣誉吧。
目前为止,这两个坑算是最深的了。但愿它们的恶劣影响不大。
剩下的几个坑是给SharpFileDB开发者的(目前就是我)。我会在各种可能发现bug的地方直接抛出异常。等这些throw消停了,就说明SharpFileDB稳定了。我再想个办法把这些难看的throw收拾收拾。
总结

现在的SharpFileDB很多方面(编号、分页、索引、查询、块)都受到LiteDB的启示,再次表示感谢。
您可以到我的Github上浏览此项目。
也许我做的这个SharpFileDB很幼稚,不过我相信它可以用于实践,我也尽量写了注释、提供了最简单的使用方法,还提供了Demo。还是那句话,欢迎您指出我的代码有哪些不足,我应该学习补充哪些知识,但请不要无意义地谩骂和人身攻击。
PS:我国大多数县的人口为几万到几十万。目前,县里各种政府部门急需实现信息化网络化办公办事,但他们一般用不起那种月薪上万的开发者和高端软件公司。我注意到,一个县级政府部门日常应对的人群数量就是万人左右,甚至常常是千人左右。所以他们不需要太高端复杂的系统设计,用支持万人级别的数据库就可以了。另一方面,初级开发者也不能充分利用那些看似高端复杂的数据库的优势。做个小型系统而已,还是简单一点好。
所以我就想做这样一个小型文件数据库,我相信这会帮助很多人。能以己所学惠及大众,才是我们的价值所在。