https://github.com/brianway/webporter
基于 webmagic 的 Java 爬虫应用
https://github.com/brianway/webporter
elasticsearch kibana zhihu
Last synced: about 1 year ago
JSON representation
基于 webmagic 的 Java 爬虫应用
- Host: GitHub
- URL: https://github.com/brianway/webporter
- Owner: brianway
- Created: 2016-11-24T04:44:44.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2022-01-08T13:14:10.000Z (over 4 years ago)
- Last Synced: 2025-04-14T03:07:37.249Z (about 1 year ago)
- Topics: elasticsearch, kibana, zhihu
- Language: Java
- Homepage:
- Size: 128 KB
- Stars: 2,781
- Watchers: 221
- Forks: 859
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# webporter
webporter 是一个基于垂直爬虫框架 [webmagic](http://webmagic.io/) 的 Java 爬虫应用,旨在提供一套完整的数据爬取,持久化存储和可视化展示的实践样例。
webporter 寓意“我们不生产数据,我们只是互联网的搬运工~”
**如果觉得不错,请先在这个仓库上点个 star 吧**,这也是对我的肯定和鼓励,谢谢了。
目前只提供了知乎用户数据的爬虫示例。不定时进行调整和补充,需要关注更新的请 watch、star、fork
---
webporter 的主要特色:
- 基于国产 Java 爬虫框架 webmagic,是众多 Python 爬虫中的一股清流
- 完全模块化的设计,强大的可扩展性
- 核心简单,但是涵盖爬虫应用的完整流程,是爬虫应用的实践样例
- 使用 JSON 配置,无需改动源码
- 支持多线程
- 支持向 Elasticsearch 批量导入
**注意:webporter 不是爬虫框架,而是如何使用爬虫框架进行实战的样例,偏休闲性质,不建议使用在生产环境。** 生产环境建议使用 webmagic 或者 scrapy
webporter 核心模块的架构和设计主要参考了 **webmagic**
[https://github.com/code4craft/webmagic](https://github.com/code4craft/webmagic)
webporter 的 github 地址:[https://github.com/brianway/webporter](https://github.com/brianway/webporter)
## 效果展示
详细的数据分析文章请看我的博客 [《爬取知乎60万用户信息之后的简单分析》](http://brianway.github.io/2016/12/20/webporter-zhihu-user-analysis/)
- 下载数据:去重导入 Elasticsearch 后大概有 60+ 万用户数据(目前没有遇到反爬限制)
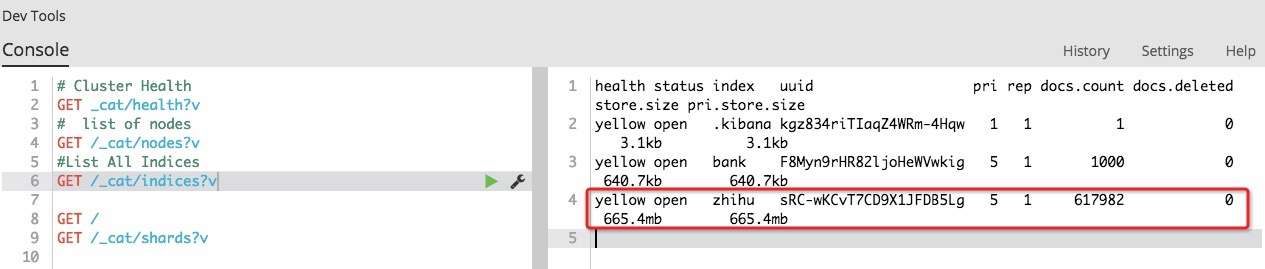
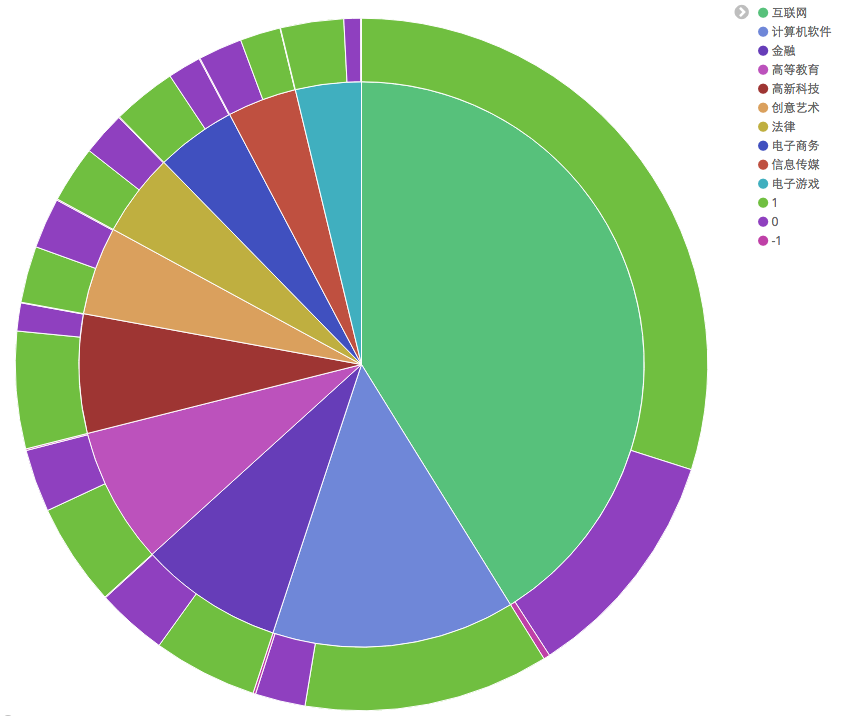
- 示例分析:通过聚合得到知乎用户 top 10 行业分布情况(1:男,0:女,-1:未知)
## 仓库目录
- [webporter-core](/webporter-core):核心基础模块,包括自动配置,抽象逻辑等部分
- [webporter-data-elasticsearch](/webporter-data-elasticsearch):将数据导入 Elasticsearch 的工具模块
- [webporter-collector-zhihu](/webporter-collector-zhihu):知乎用户信息的业务模块,完成爬取和持久化存储的功能
## 环境要求
- JDK 1.8+
- Maven 3.3+
- Elasticsearch 5.0.1
- Kibana 5.0.1
新手可参考我的博客 [《Elasticsearch 5.0-安装使用》](http://brianway.github.io/2016/12/13/elasticsearch-installation/)快速上手 Elasticsearch+Kibana
## 快速开始
以爬取知乎用户数据为例
1.定制配置文件
配置文件位于 `webporter-collector-zhihu/src/main/resources/config.json`, 示例:
```json
{
"site": {
"domain": "www.zhihu.com",
"headers": {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36",
"authorization": "Your own authorization here."
},
"retryTimes": 3,
"sleepTime": 500
},
"base_dir": "/Users/brian/todo/data/zhihu/"
}
```
**仅需要修改两处:`authorization` 和 `base_dir` 即可**
- `authorization`: 需要知乎账户在已登录状态下自行在浏览器抓包提取该 HTTP 响应头。若有疑问请参考 [issue 3](https://github.com/brianway/webporter/issues/3)
- `base_dir`: 为保存数据文件的根目录,需具有写权限
配完就可以直接使用了。更多关于 `site` 的属性配置请参考 [WebMagic in Action - Site Config](http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/spider-config.html)
2.启动爬虫
依次运行 `webporter-collector-zhihu` 模块的下面两个类的 `main` 方法即可。(*注意:由于这两个阶段是串行的,不要同时启动这两个类*)
- [`ZhihuFolloweePageProcessor`](/webporter-collector-zhihu/src/main/java/com/brianway/webporter/collector/zhihu/download/ZhihuFolloweePageProcessor.java):该类用于从知乎下载用户信息,下载的数据可以复制粘贴在 [在线 json 格式化工具](http://tool.oschina.net/codeformat/json)中查看
- [`FolloweeUploader`](/webporter-collector-zhihu/src/main/java/com/brianway/webporter/collector/zhihu/upload/FolloweeUploader.java):该类用于将用户信息上传到 Elasticsearch (需要提前安装并运行 Elasticsearch),知乎数据的 index 名称为 `zhihu`
3.可视化
安装好 [Elasticsearch](https://www.elastic.co/guide/en/elasticsearch/reference/5.0/index.html) 和 [Kibana](https://www.elastic.co/guide/en/kibana/5.0/index.html) 后,在 Kibana 中使用 Visualize 对数据可视化即可
## 赞助
如果您觉得该项目对您有帮助,请扫描下方二维码对我进行鼓励,以便我更好的维护和更新,谢谢支持!


## TODO
* [x] 数据爬取,获取知乎用户数据
* [x] 数据持久化,将数据导入到 Elasticsearch 中
* [x] 可视化展示,通过前端框架对数据进行简单的分析和展示
* [ ] 使用 Java 8 新特性完善代码
* [ ] Dockerize 这个仓库,方便用户直接使用
-----
## 联系作者
- [Brian's Personal Website](http://brianway.github.io/)
- [CSDN](http://blog.csdn.net/h3243212/)
- [oschina](http://my.oschina.net/brianway)
Email: weichuyang@163.com
## Lisence
Lisenced under [Apache 2.0 lisence](http://opensource.org/licenses/Apache-2.0)