https://github.com/bryanoliveira/sliding-puzzles-gym
A scalable benchmark for state representation learning in visual reinforcement learning.
https://github.com/bryanoliveira/sliding-puzzles-gym
benchmark environment reinforcement-learning rl
Last synced: 6 months ago
JSON representation
A scalable benchmark for state representation learning in visual reinforcement learning.
- Host: GitHub
- URL: https://github.com/bryanoliveira/sliding-puzzles-gym
- Owner: bryanoliveira
- License: mit
- Created: 2023-10-31T17:21:21.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2025-04-18T20:24:22.000Z (6 months ago)
- Last Synced: 2025-04-19T05:15:43.606Z (6 months ago)
- Topics: benchmark, environment, reinforcement-learning, rl
- Language: Python
- Homepage:
- Size: 4.22 MB
- Stars: 3
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Sliding Puzzles Gym Environment



A PPO agent solving the environment.
## Table of Contents
1. [Introduction](#introduction)
2. [Installation](#installation)
3. [Usage](#usage)
4. [Environment Details](#environment-details)
5. [Environment Parameters](#environment-parameters)
6. [Contributing](#contributing)
7. [License](#license)
## Introduction
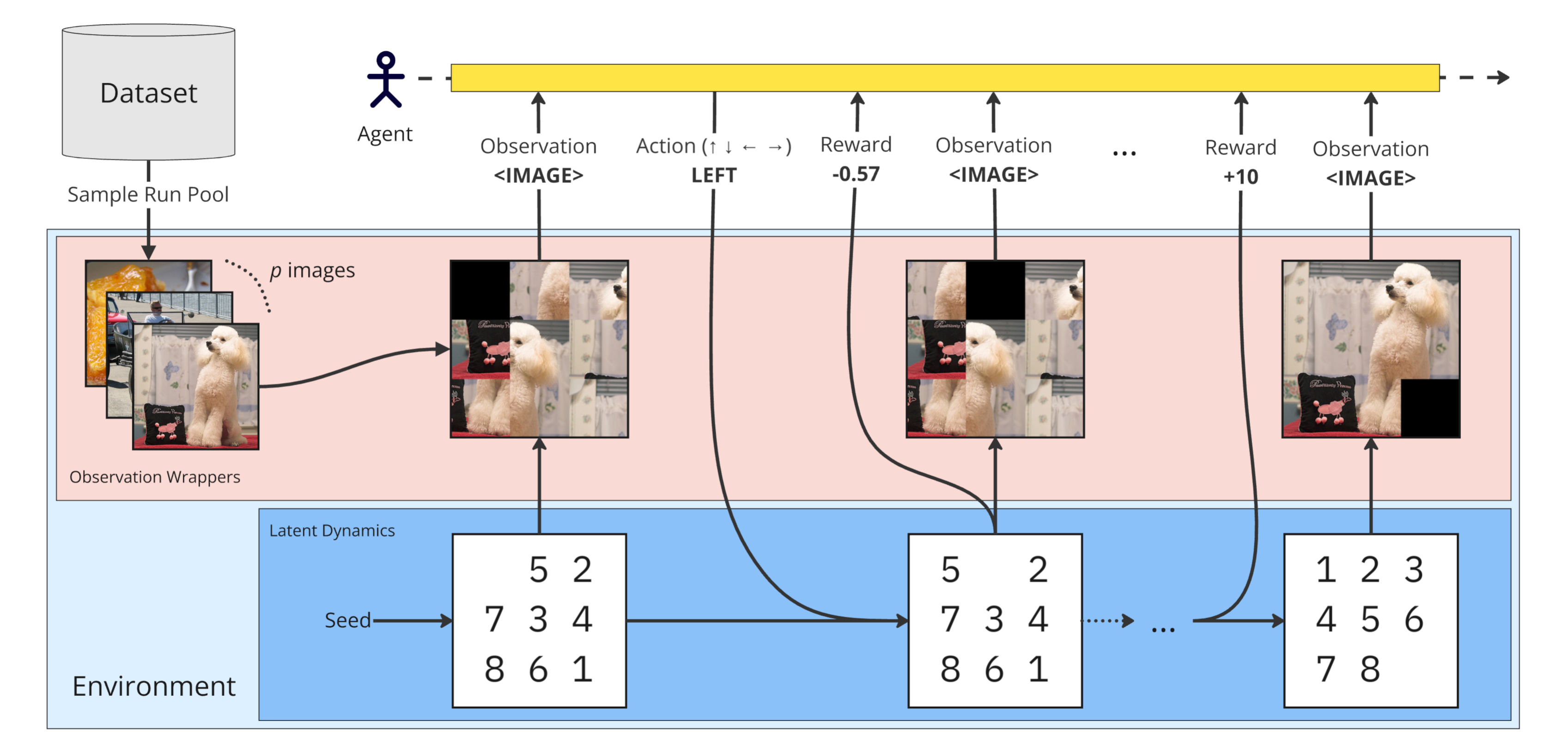
> Overview of the Sliding Puzzles Gym (SPGym). The framework extends the 15-tile puzzle by incorporating image-based tiles, allowing scalable representation complexity while maintaining fixed environment dynamics.
The Sliding Puzzles Gym (SPGym) is a customizable Gymnasium-compatible environment designed for training and evaluating reinforcement learning algorithms on sliding puzzle tasks. This environment, as described in our recent paper [Sliding Puzzles Gym: A Scalable Benchmark for State Representation in Visual Reinforcement Learning](), serves as a benchmark for assessing the representation learning capabilities of various RL algorithms. The code for reproducing the paper results can be found [here](https://github.com/bryanoliveira/spgym-experiments).
Our research demonstrates how sliding puzzles can be used to evaluate an RL agent's ability to learn and utilize spatial relationships and compositional visual representations. The environment supports various puzzle sizes, image-based puzzles, and different rendering modes, allowing for a comprehensive analysis of algorithm performance across different complexity levels and input modalities. Crucially, the visual complexity of the task can be controlled via the `image_pool_size` parameter, which defines how many different images the agent will see during training.
By using this environment, researchers can:
1. Compare the effectiveness of different RL algorithms in learning useful state representations
2. Analyze how well agents generalize across puzzle observation spaces
3. Investigate the impact of various environment parameters and algorithmic changes on representation learning performance
We encourage the use of this environment for further research in representation learning within reinforcement learning contexts.
## Installation
To install SPGym, run the following command:
```bash
pip install sliding-puzzles
```
You can alternatively clone this repository and install it as an editable package:
```bash
git clone https://github.com/bryanoliveira/sliding-puzzles-gym
cd sliding-puzzles-gym
pip install -e .
```
To use the `imagenet-1k` dataset you will also need to download the dataset from https://huggingface.co/datasets/ILSVRC/imagenet-1k/blob/main/data/val_images.tar.gz and extract it to `/imgs/imagenet-1k`. You can do this automatically by running the following command:
```bash
sliding-puzzles setup imagenet
```
## Usage
To use SPGym in your project, follow these steps:
1. Import the environment:
```python
import sliding_puzzles
# For image-based puzzles
env = sliding_puzzles.make(w=3, variation="image", image_folder="imagenet-1k", image_pool_size=2, render_mode="human")
# For number-based puzzles
env = sliding_puzzles.make(w=3, variation="onehot", render_mode="state")
# Alternatively, use Gymnasium to make the environment
import gymnasium
import sliding_puzzles
env = gymnasium.make("SlidingPuzzles-v0", w=3, variation="image", image_folder="imagenet-1k", image_pool_size=2, render_mode="human")
```
2. Interact with the environment using the standard Gym interface:
```python
obs = env.reset()
done = False
while not done:
action = env.action_space.sample() # Replace with your agent's action
obs, reward, terminated, truncated, info = env.step(action)
env.render()
env.close()
```
## Environment Details

> Different observation modalities in SPGym. Each modality presents a unique challenge for representation learning. The four presented observations represent the same latent puzzle state. Currently, text overlay modalities are not available.
- **Observation Space**: There are multiple available observation spaces, including raw (the 2D state array), onehot (the state array one-hot encoded in 1D), and image (an image overlayed on top of the puzzle).
- **Action Space**: The action space is discrete, with four possible actions: 0 (up), 1 (down), 2 (left), 3 (right). Other integers are allowed but are treated as no-op.
- **Reward Function**: The default reward is the negative normalized distances for all tiles to their target position at each step taken (a float between -1 and 0). By default the agent gets +10 for solving the puzzle.
- **Episode Termination**: An episode ends when the puzzle is solved (terminated) or a maximum number of steps is reached (truncated).
More information can be found in our [paper]().
## Environment Parameters
The Sliding Puzzle environment can be customized with the following parameters:
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `w` | Optional[int] | None | Width of the puzzle grid. If not specified, it will be set to the same value as `h`. |
| `h` | Optional[int] | None | Height of the puzzle grid. If not specified, it will be set to the same value as `w`. |
| `render_mode` | str | "state" | Determines how the environment is rendered. Options: "state", "human", "rgb_array". |
| `render_size` | tuple | (32, 32) | Size of the rendered image (Width x Height). |
| `sparse_rewards` | bool | False | If True, provides sparse rewards; otherwise, dense rewards. |
| `win_reward` | float | 10 | Reward given when the puzzle is solved. |
| `move_reward` | float | -0.1 | Reward given for each move (should be non-positive). |
| `invalid_move_reward` | Optional[float] | -1 | Reward given for invalid moves. If None, invalid moves are not penalized. |
| `circular_actions` | bool | False | If True, allows wrapping around the grid edges. |
| `blank_value` | int | -1 | Value used to represent the blank tile (must be non-positive). |
| `reward_mode` | str | "distances" | Determines how rewards are calculated. Options: "distances", "percent_solved". |
| `shuffle_mode` | str | "fast" | Method used to shuffle the puzzle. Options: "fast", "serial". |
| `shuffle_steps` | int | 100 | Number of steps to use when shuffling the puzzle (only for "serial" shuffle mode). |
| `shuffle_target_reward` | Optional[float] | None | Target reward to reach during shuffling (must be negative if specified). |
| `shuffle_render` | bool | False | If True, renders the environment during shuffling. |
| `max_episode_steps` | Optional[int] | 1000 | Maximum number of steps per episode. If None, there is no limit. |
| `seed` | Optional[int] | None | Seed for the random number generator. If None, a random seed will be generated. |
Note: At least one of `w` or `h` must be specified, and at least one dimension must be greater than 1.
### Image Variation Parameters
The image variation of the Sliding Puzzle environment accepts these additional parameters:
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `image_folder` | str | "single" | The folder containing the images to be used for the puzzle. |
| `image_pool_size` | Optional[int] | None | The number of images to use from the folder. If None, all images in the folder will be used. |
| `image_pool_seed` | Optional[int] | None | Seed for randomly selecting images from the pool. If None, a random seed will be used. |
| `image_size` | tuple | (84, 84) | Size of the rendered image (Width x Height). |
| `background_color_rgb` | tuple | (0, 0, 0) | RGB color of the background (Black by default). |
Note: These parameters are specific to the image variation of the Sliding Puzzle environment and are used in addition to the base environment parameters.
## Contributing
Contributions to the SPGym are welcome! Please follow these steps to contribute:
1. Fork the repository
2. Create a new branch for your feature
3. Commit your changes
4. Push to the branch
5. Create a new Pull Request
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.