https://github.com/bshall/acoustic-model
Acoustic models for: A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion
https://github.com/bshall/acoustic-model
pytorch representation-learning speech voice-conversion
Last synced: 10 months ago
JSON representation
Acoustic models for: A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion
- Host: GitHub
- URL: https://github.com/bshall/acoustic-model
- Owner: bshall
- License: mit
- Created: 2021-10-19T11:09:48.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2023-07-12T20:48:09.000Z (almost 3 years ago)
- Last Synced: 2025-06-18T05:39:52.196Z (about 1 year ago)
- Topics: pytorch, representation-learning, speech, voice-conversion
- Language: Python
- Homepage: https://bshall.github.io/soft-vc/
- Size: 164 KB
- Stars: 103
- Watchers: 7
- Forks: 25
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README

# Acoustic-Model
Training and inference scripts for the acoustic models in [A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion](https://ieeexplore.ieee.org/abstract/document/9746484). For more details see [soft-vc](https://github.com/bshall/soft-vc). Audio samples can be found [here](https://bshall.github.io/soft-vc/). Colab demo can be found [here](https://colab.research.google.com/github/bshall/soft-vc/blob/main/soft-vc-demo.ipynb).
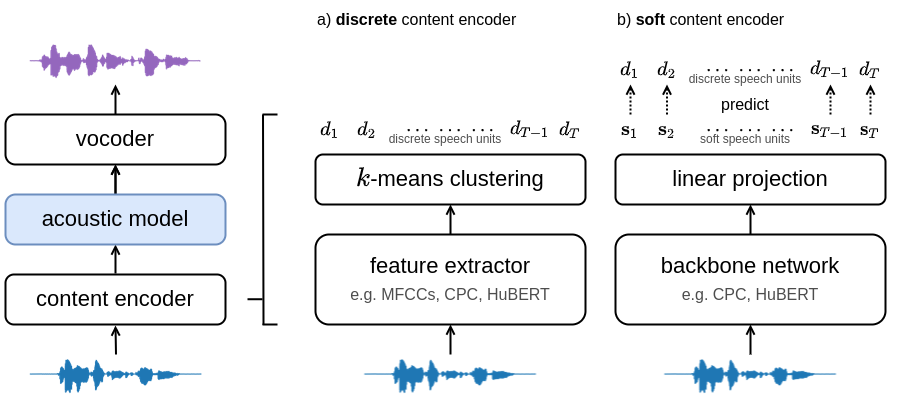
Fig 1: Architecture of the voice conversion system. a) The discrete content encoder clusters audio features to produce a sequence of discrete speech units. b) The soft content encoder is trained to predict the discrete units. The acoustic model transforms the discrete/soft speech units into a target spectrogram. The vocoder converts the spectrogram into an audio waveform.
## Example Usage
### Programmatic Usage
```python
import torch
import numpy as np
# Load checkpoint (either hubert_soft or hubert_discrete)
acoustic = torch.hub.load("bshall/acoustic-model:main", "hubert_soft").cuda()
# Load speech units
units = torch.from_numpy(np.load("path/to/units"))
# Generate mel-spectrogram
mel = acoustic.generate(units)
```
### Script-Based Usage
```
usage: generate.py [-h] {soft,discrete} in-dir out-dir
Generate spectrograms from input speech units (discrete or soft).
positional arguments:
{soft,discrete} available models (HuBERT-Soft or HuBERT-Discrete)
in-dir path to the dataset directory.
out-dir path to the output directory.
optional arguments:
-h, --help show this help message and exit
```
## Training
### Step 1: Dataset Preparation
Download and extract the [LJSpeech](https://keithito.com/LJ-Speech-Dataset/) dataset. The training script expects the following tree structure for the dataset directory:
```
└───wavs
├───dev
│ ├───LJ001-0001.wav
│ ├───...
│ └───LJ050-0278.wav
└───train
├───LJ002-0332.wav
├───...
└───LJ047-0007.wav
```
The `train` and `dev` directories should contain the training and validation splits respectively. The splits used for the paper can be found [here](https://github.com/bshall/acoustic-model/releases/tag/v0.1).
### Step 2: Extract Spectrograms
Extract mel-spectrograms using the `mel.py` script:
```
usage: mels.py [-h] in-dir out-dir
Extract mel-spectrograms for an audio dataset.
positional arguments:
in-dir path to the dataset directory.
out-dir path to the output directory.
optional arguments:
-h, --help show this help message and exit
```
for example:
```
python mel.py path/to/LJSpeech-1.1/wavs path/to/LJSpeech-1.1/mels
```
At this point the directory tree should look like:
```
├───mels
│ ├───...
└───wavs
├───...
```
### Step 3: Extract Discrete or Soft Speech Units
Use the HuBERT-Soft or HuBERT-Discrete content encoders to extract speech units. First clone the [content encoder repo](https://github.com/bshall/hubert) and then run `encode.py` (see the repo for details):
```
usage: encode.py [-h] [--extension EXTENSION] {soft,discrete} in-dir out-dir
Encode an audio dataset.
positional arguments:
{soft,discrete} available models (HuBERT-Soft or HuBERT-Discrete)
in-dir path to the dataset directory.
out-dir path to the output directory.
optional arguments:
-h, --help show this help message and exit
--extension EXTENSION
extension of the audio files (defaults to .flac).
```
for example:
```
python encode.py soft path/to/LJSpeech-1.1/wavs path/to/LJSpeech-1.1/soft --extension .wav
```
At this point the directory tree should look like:
```
├───mels
│ ├───...
├───soft/discrete
│ ├───...
└───wavs
├───...
```
### Step 4: Train the Acoustic-Model
```
usage: train.py [-h] [--resume RESUME] [--discrete] dataset-dir checkpoint-dir
Train the acoustic model.
positional arguments:
dataset-dir path to the data directory.
checkpoint-dir path to the checkpoint directory.
optional arguments:
-h, --help show this help message and exit
--resume RESUME path to the checkpoint to resume from.
--discrete Use discrete units.
```
## Links
- [Soft-VC repo](https://github.com/bshall/soft-vc)
- [Soft-VC paper](https://ieeexplore.ieee.org/abstract/document/9746484)
- [HuBERT content encoders](https://github.com/bshall/hubert)
- [HiFiGAN vocoder](https://github.com/bshall/hifigan)
## Citation
If you found this work helpful please consider citing our paper:
```
@inproceedings{
soft-vc-2022,
author={van Niekerk, Benjamin and Carbonneau, Marc-André and Zaïdi, Julian and Baas, Matthew and Seuté, Hugo and Kamper, Herman},
booktitle={ICASSP},
title={A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion},
year={2022}
}
```