https://github.com/bshall/zerospeech
VQ-VAE for Acoustic Unit Discovery and Voice Conversion
https://github.com/bshall/zerospeech
acoustic-features pytorch speech-synthesis voice-conversion vq-vae zerospeech
Last synced: 6 months ago
JSON representation
VQ-VAE for Acoustic Unit Discovery and Voice Conversion
- Host: GitHub
- URL: https://github.com/bshall/zerospeech
- Owner: bshall
- Created: 2019-06-25T17:44:16.000Z (over 6 years ago)
- Default Branch: master
- Last Pushed: 2023-07-06T21:56:08.000Z (over 2 years ago)
- Last Synced: 2025-03-30T18:08:33.602Z (7 months ago)
- Topics: acoustic-features, pytorch, speech-synthesis, voice-conversion, vq-vae, zerospeech
- Language: Python
- Homepage: https://bshall.github.io/ZeroSpeech/
- Size: 17.3 MB
- Stars: 334
- Watchers: 9
- Forks: 45
- Open Issues: 11
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# VQ-VAE for Acoustic Unit Discovery and Voice Conversion
Train and evaluate the VQ-VAE model for our submission to the [ZeroSpeech 2020 challenge](https://zerospeech.com/).
Voice conversion samples can be found [here](https://bshall.github.io/ZeroSpeech/).
Pretrained weights for the 2019 English and Indonesian datasets can be found [here](https://github.com/bshall/ZeroSpeech/releases/tag/v0.1).
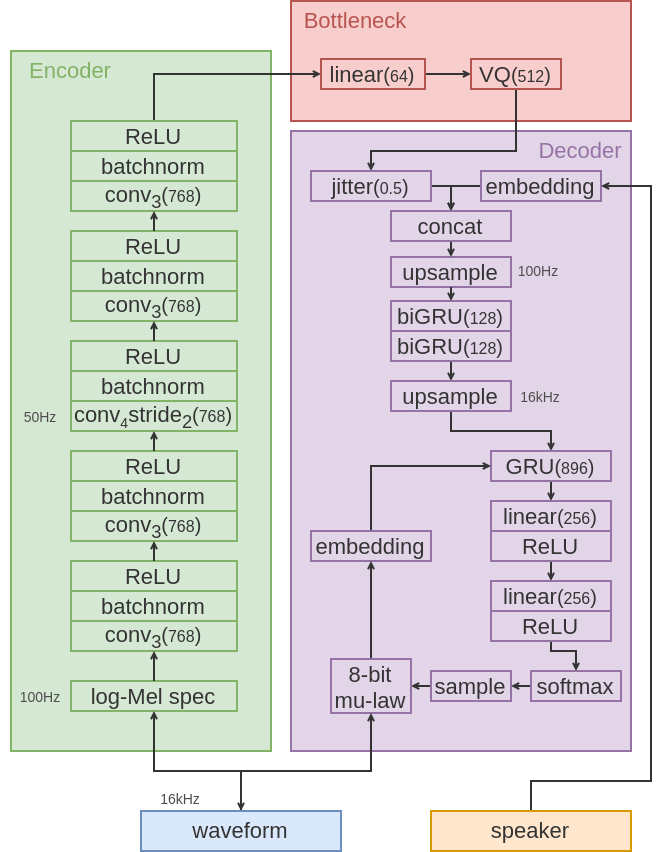
Fig 1: VQ-VAE model architecture.
# Quick Start
## Requirements
1. Ensure you have Python 3 and PyTorch 1.4 or greater.
2. Install [NVIDIA/apex](https://github.com/NVIDIA/apex) for mixed precision training.
3. Install pip dependencies:
```
pip install -r requirements.txt
```
4. For evaluation install [bootphon/zerospeech2020](https://github.com/bootphon/zerospeech2020).
## Data and Preprocessing
1. Download and extract the [ZeroSpeech2020 datasets](https://download.zerospeech.com/).
2. Download the train/test splits [here](https://github.com/bshall/ZeroSpeech/releases/tag/v0.1)
and extract in the root directory of the repo.
3. Preprocess audio and extract train/test log-Mel spectrograms:
```
python preprocess.py in_dir=/path/to/dataset dataset=[2019/english or 2019/surprise]
```
Note: `in_dir` must be the path to the `2019` folder.
For `dataset` choose between `2019/english` or `2019/surprise`.
Other datasets will be added in the future.
```
e.g. python preprocess.py in_dir=../datasets/2020/2019 dataset=2019/english
```
## Training
Train the models or download pretrained weights [here](https://github.com/bshall/ZeroSpeech/releases/tag/v0.1):
```
python train.py checkpoint_dir=path/to/checkpoint_dir dataset=[2019/english or 2019/surprise]
```
```
e.g. python train.py checkpoint_dir=checkpoints/2019english dataset=2019/english
```
## Evaluation
### Voice conversion
```
python convert.py checkpoint=path/to/checkpoint in_dir=path/to/wavs out_dir=path/to/out_dir synthesis_list=path/to/synthesis_list dataset=[2019/english or 2019/surprise]
```
Note: the `synthesis list` is a `json` file:
```
[
[
"english/test/S002_0379088085",
"V002",
"V002_0379088085"
]
]
```
containing a list of items with a) the path (relative to `in_dir`) of the source `wav` files;
b) the target speaker (see `datasets/2019/english/speakers.json` for a list of options);
and c) the target file name.
```
e.g. python convert.py checkpoint=checkpoints/2019english/model.ckpt-500000.pt in_dir=../datasets/2020/2019 out_dir=submission/2019/english/test synthesis_list=datasets/2019/english/synthesis.json dataset=2019/english
```
Voice conversion samples can be found [here](https://bshall.github.io/ZeroSpeech/).
### ABX Score
1. Encode test data for evaluation:
```
python encode.py checkpoint=path/to/checkpoint out_dir=path/to/out_dir dataset=[2019/english or 2019/surprise]
```
```
e.g. python encode.py checkpoint=checkpoints/2019english/model.ckpt-500000.pt out_dir=submission/2019/english/test dataset=2019/english
```
2. Run ABX evaluation script (see [bootphon/zerospeech2020](https://github.com/bootphon/zerospeech2020)).
The ABX score for the pretrained english model (available [here](https://github.com/bshall/ZeroSpeech/releases/tag/v0.1)) is:
```
{
"2019": {
"english": {
"scores": {
"abx": 14.043611615570672,
"bitrate": 412.2387509949519
},
"details_bitrate": {
"test": 412.2387509949519
},
"details_abx": {
"test": {
"cosine": 14.043611615570672,
"KL": 50.0,
"levenshtein": 35.927825062038984
}
}
}
}
}
```
## References
This work is based on:
1. Chorowski, Jan, et al. ["Unsupervised speech representation learning using wavenet autoencoders."](https://arxiv.org/abs/1901.08810)
IEEE/ACM transactions on audio, speech, and language processing 27.12 (2019): 2041-2053.
2. Lorenzo-Trueba, Jaime, et al. ["Towards achieving robust universal neural vocoding."](https://arxiv.org/abs/1811.06292)
INTERSPEECH. 2019.
3. van den Oord, Aaron, and Oriol Vinyals. ["Neural discrete representation learning."](https://arxiv.org/abs/1711.00937)
Advances in Neural Information Processing Systems. 2017.