https://github.com/bwconrad/soft-moe
PyTorch implementation of "From Sparse to Soft Mixtures of Experts"
https://github.com/bwconrad/soft-moe
computer-vision machine-learning mixture-of-experts pytorch transformer vision-transformer
Last synced: about 1 year ago
JSON representation
PyTorch implementation of "From Sparse to Soft Mixtures of Experts"
- Host: GitHub
- URL: https://github.com/bwconrad/soft-moe
- Owner: bwconrad
- License: apache-2.0
- Created: 2023-08-16T17:48:22.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2023-08-22T20:01:27.000Z (almost 3 years ago)
- Last Synced: 2025-04-11T04:04:30.333Z (about 1 year ago)
- Topics: computer-vision, machine-learning, mixture-of-experts, pytorch, transformer, vision-transformer
- Language: Python
- Homepage:
- Size: 344 KB
- Stars: 53
- Watchers: 2
- Forks: 3
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
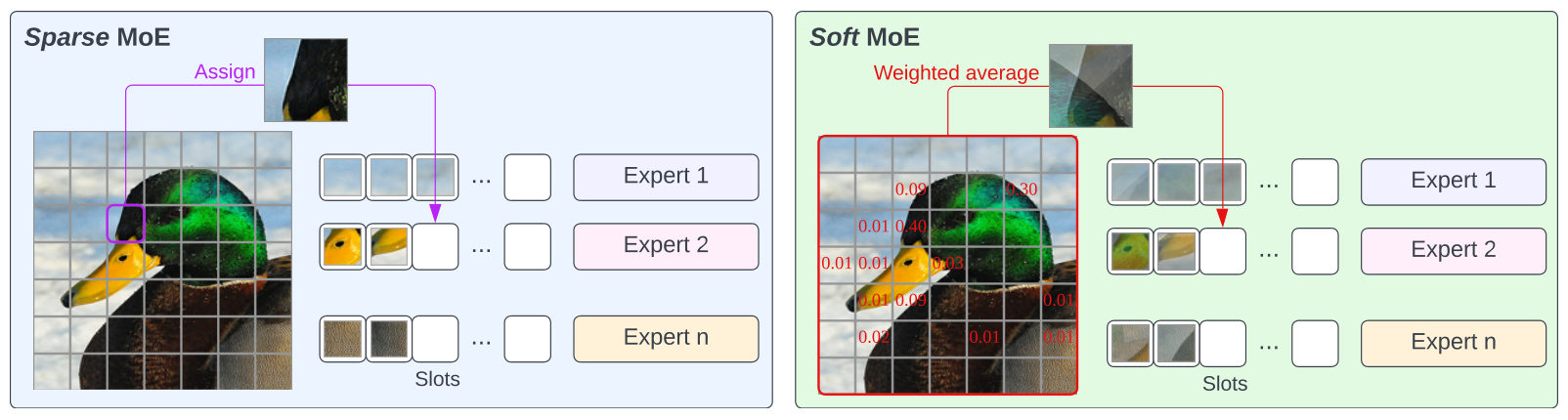
# Soft Mixture of Experts
PyTorch implementation of Soft Mixture of Experts (Soft-MoE) from ["From Sparse to Soft Mixtures of Experts"](https://arxiv.org/abs/2308.00951v1).
This implementation extends the [`timm`](https://github.com/huggingface/pytorch-image-models) library's `VisionTransformer` class to support Soft-MoE MLP layers.
## Installation
```
pip install soft-moe
```
Or install the entire repo with:
```
git clone https://github.com/bwconrad/soft-moe
cd soft-moe/
pip install -r requirements.txt
```
## Usage
### Initializing a Soft Mixture of Experts Vision Transformer
```python
import torch
from soft_moe import SoftMoEVisionTransformer
net = SoftMoEVisionTransformer(
num_experts=128,
slots_per_expert=1,
moe_layer_index=6,
img_size=224,
patch_size=32,
num_classes=1000,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4,
)
img = torch.randn(1, 3, 224, 224)
preds = net(img)
```
Functions are also available to initialize default network configurations:
```python
from soft_moe import (soft_moe_vit_base, soft_moe_vit_huge,
soft_moe_vit_large, soft_moe_vit_small,
soft_moe_vit_tiny)
net = soft_moe_vit_tiny()
net = soft_moe_vit_small()
net = soft_moe_vit_base()
net = soft_moe_vit_large()
net = soft_moe_vit_huge()
net = soft_moe_vit_tiny(num_experts=64, slots_per_expert=2, img_size=128)
```
#### Setting the Mixture of Expert Layers
The `moe_layer_index` argument sets at which layer indices to use MoE MLP layers instead of regular MLP layers.
When an `int` is given, all layers starting from that depth index will be MoE layers.
```python
net = SoftMoEVisionTransformer(
moe_layer_index=6, # Blocks 6-12
depth=12,
)
```
When a `list` is given, all specified layers will be MoE layers.
```python
net = SoftMoEVisionTransformer(
moe_layer_index=[0, 2, 4], # Blocks 0, 2 and 4
depth=12,
)
```
- __Note__: `moe_layer_index` uses __0-index__ convention.
### Creating a Soft Mixture of Experts Layer
The `SoftMoELayerWrapper` class can be used to make any network layer, that takes a tensor of shape `[batch, length, dim]`, into a Soft Mixture of Experts layer.
```python
import torch
import torch.nn as nn
from soft_moe import SoftMoELayerWrapper
x = torch.rand(1, 16, 128)
layer = SoftMoELayerWrapper(
dim=128,
slots_per_expert=2,
num_experts=32,
layer=nn.Linear,
# nn.Linear arguments
in_features=128,
out_features=32,
)
y = layer(x)
layer = SoftMoELayerWrapper(
dim=128,
slots_per_expert=1,
num_experts=16,
layer=nn.TransformerEncoderLayer,
# nn.TransformerEncoderLayer arguments
d_model=128,
nhead=8,
)
y = layer(x)
```
- __Note__: If the name of a layer argument overlaps with one of other arguments (e.g. `dim`) you can pass a partial function to `layer`.
- e.g. `layer=partial(MyCustomLayer, dim=128)`
## Citation
```bibtex
@article{puigcerver2023sparse,
title={From Sparse to Soft Mixtures of Experts},
author={Puigcerver, Joan and Riquelme, Carlos and Mustafa, Basil and Houlsby, Neil},
journal={arXiv preprint arXiv:2308.00951},
year={2023}
}
```