https://github.com/bytewax/bytewax
Python Stream Processing
https://github.com/bytewax/bytewax
data-engineering data-processing data-science dataflow machine-learning python rust stream-processing streaming-data
Last synced: about 1 month ago
JSON representation
Python Stream Processing
- Host: GitHub
- URL: https://github.com/bytewax/bytewax
- Owner: bytewax
- License: apache-2.0
- Created: 2022-02-04T18:29:36.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2025-03-27T13:25:59.000Z (3 months ago)
- Last Synced: 2025-05-08T05:44:18.789Z (about 1 month ago)
- Topics: data-engineering, data-processing, data-science, dataflow, machine-learning, python, rust, stream-processing, streaming-data
- Language: Python
- Homepage: https://docs.bytewax.io/
- Size: 12 MB
- Stars: 1,726
- Watchers: 18
- Forks: 79
- Open Issues: 33
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
Awesome Lists containing this project
- awesome-streaming - Bytewax - data parallel, distributed, stateful stream processing framework. (Table of Contents / Streaming Engine)
- awesome-production-machine-learning - Bytewax - Flexible Python-centric stateful stream processing framework built on top of Rust engine. (Data Stream Processing)
README
# Bytewax: Python Stateful Stream Processing Framework





**Bytewax** is a Python framework and Rust-based distributed processing engine for stateful event and stream processing. Inspired by capabilities found in tools like Apache Flink, Spark, and Kafka Streams, Bytewax makes stream processing simpler and more accessible by integrating directly with the Python ecosystem you already know and trust.
**Key Features:**
- **Python-first:** Leverage your existing Python libraries, frameworks, and tooling.
- **Stateful Stream Processing:** Maintain and recover state automatically, enabling advanced online machine learning and complex event-driven applications.
- **Scalable & Distributed:** Easily scale from local development to multi-node, multi-worker deployments on Kubernetes or other infrastructures.
- **Rich Connector Ecosystem:** Ingest data from sources like Kafka, filesystems, or WebSockets, and output to data lakes, key-value stores, or other systems.
- **Flexible Dataflow API:** Compose pipelines using operators (e.g., `map`, `filter`, `join`, `fold_window`) to express complex logic.
---
## Table of Contents
- [Quick Start](#quick-start)
- [How Bytewax Works](#how-bytewax-works)
- [Operators Overview](#operators-overview)
- [Connectors (Module Hub)](#connectors-module-hub)
- [Local Development, Testing, and Production](#local-development-testing-and-production)
- [Deployment Options](#deployment-options)
- [Running Locally](#running-locally)
- [Containerized Execution](#containerized-execution)
- [Scaling on Kubernetes](#scaling-on-kubernetes)
- [Examples](#examples)
- [Community and Contributing](#community-and-contributing)
- [License](#license)
---
## Quick Start
Install Bytewax from PyPI:
```sh
pip install bytewax
```
[Install `waxctl`](https://bytewax.io/waxctl) to manage deployments at scale.
**Minimal Example:**
```python
from bytewax.dataflow import Dataflow
from bytewax import operators as op
from bytewax.testing import TestingSource
flow = Dataflow("quickstart")
# Input: Local test source for demonstration
inp = op.input("inp", flow, TestingSource([1, 2, 3, 4, 5]))
# Transform: Filter even numbers and multiply by 10
filtered = op.filter("keep_even", inp, lambda x: x % 2 == 0)
results = op.map("multiply_by_10", filtered, lambda x: x * 10)
# Output: Print results to stdout
op.inspect("print_results", results)
```
Run it locally:
```sh
python -m bytewax.run quickstart.py
```
---
## How Bytewax Works
Bytewax uses a **dataflow computational model**, similar to systems like Flink or Spark, but with a Pythonic interface. You define a dataflow graph of operators and connectors:
1. **Input:** Data sources (Kafka, file systems, S3, WebSockets, custom connectors)
2. **Operators:** Stateful transformations (map, filter, fold_window, join) defined in Python.
3. **Output:** Data sinks (databases, storage systems, message queues).
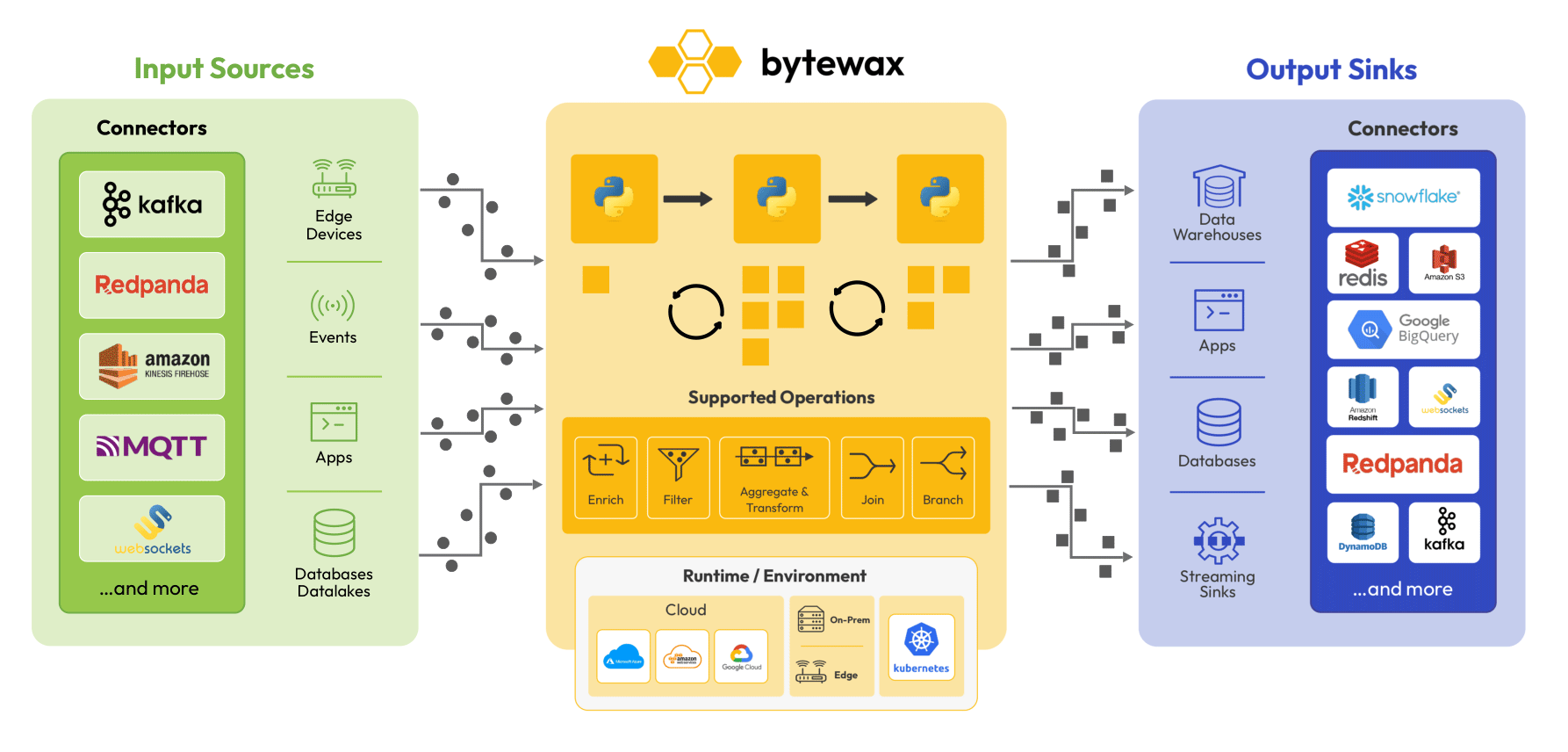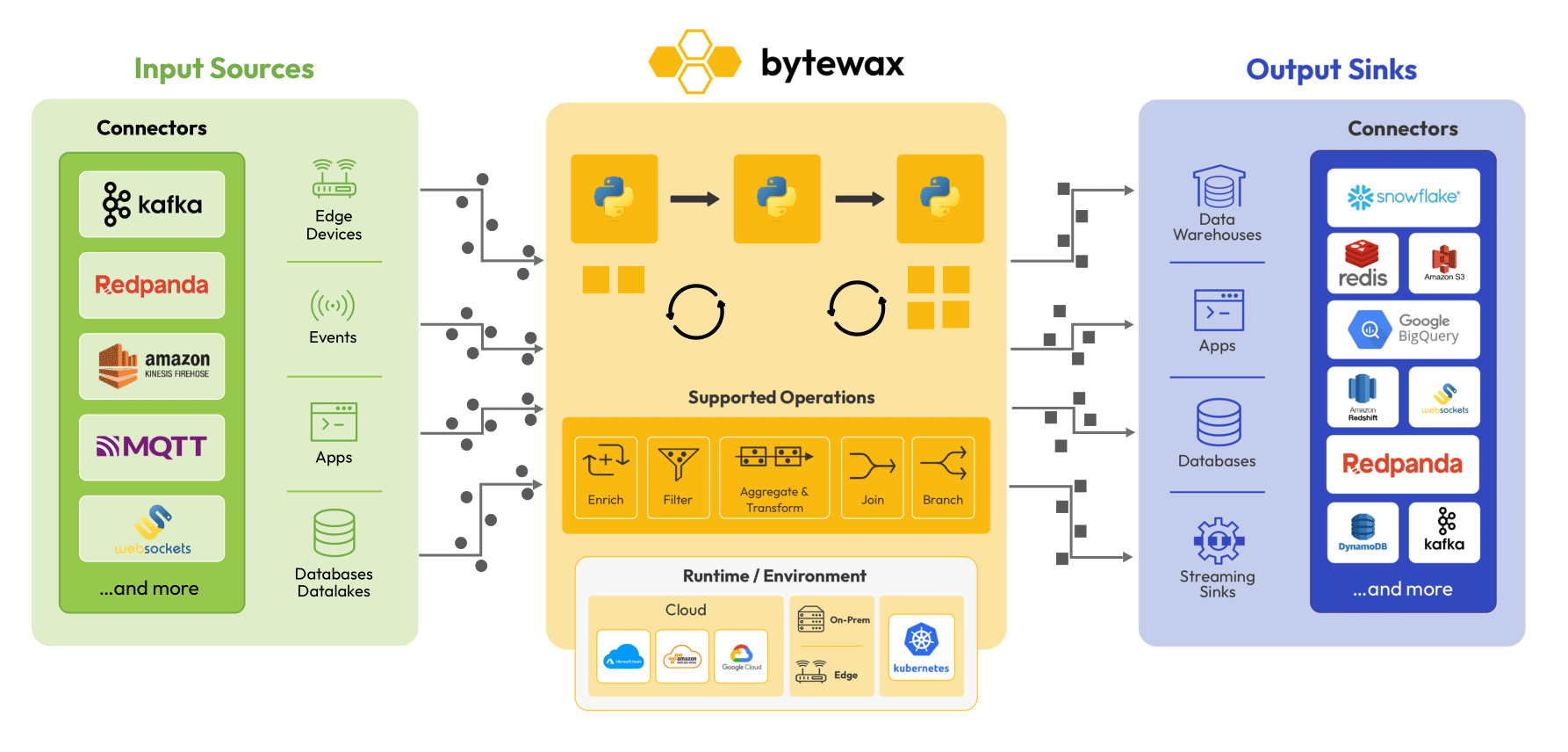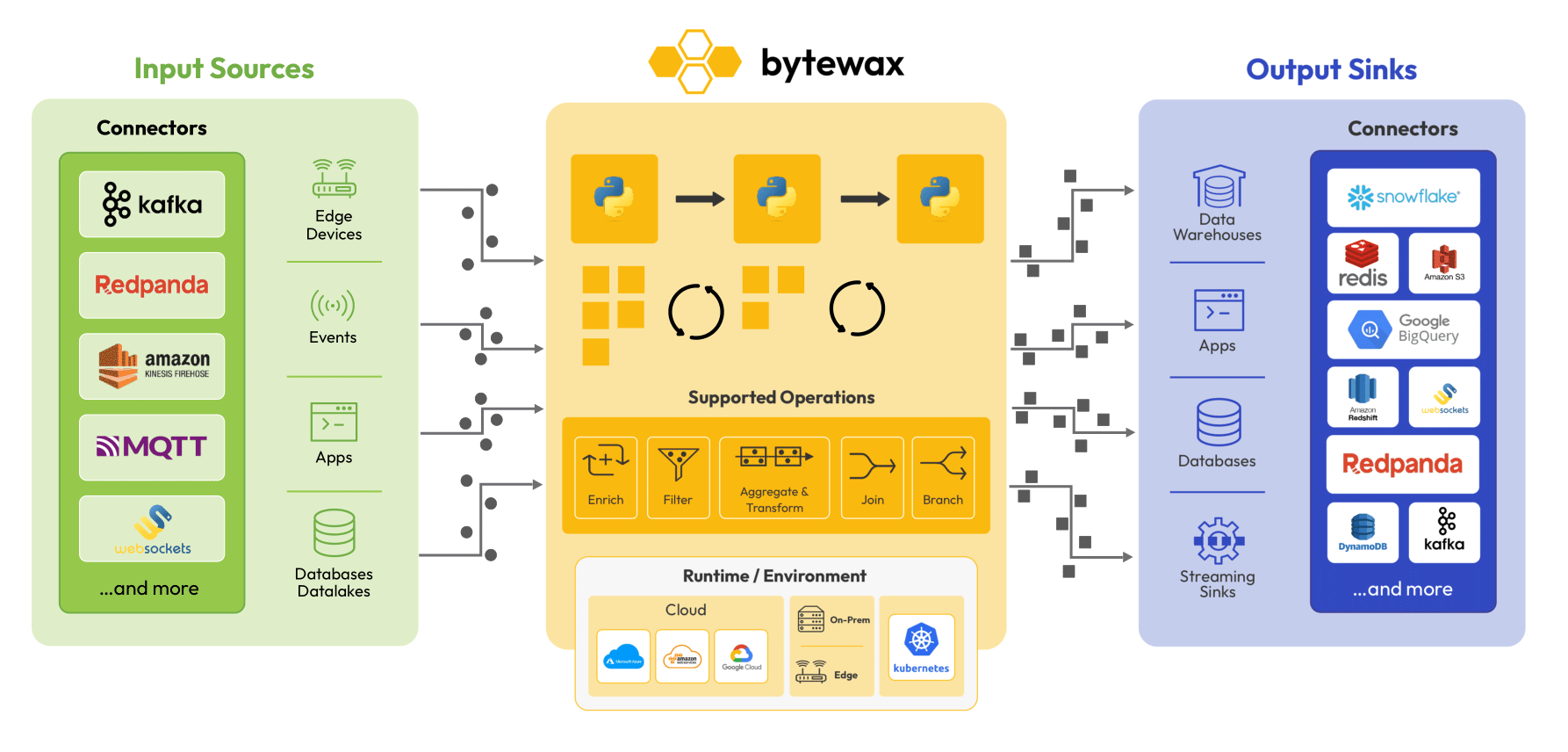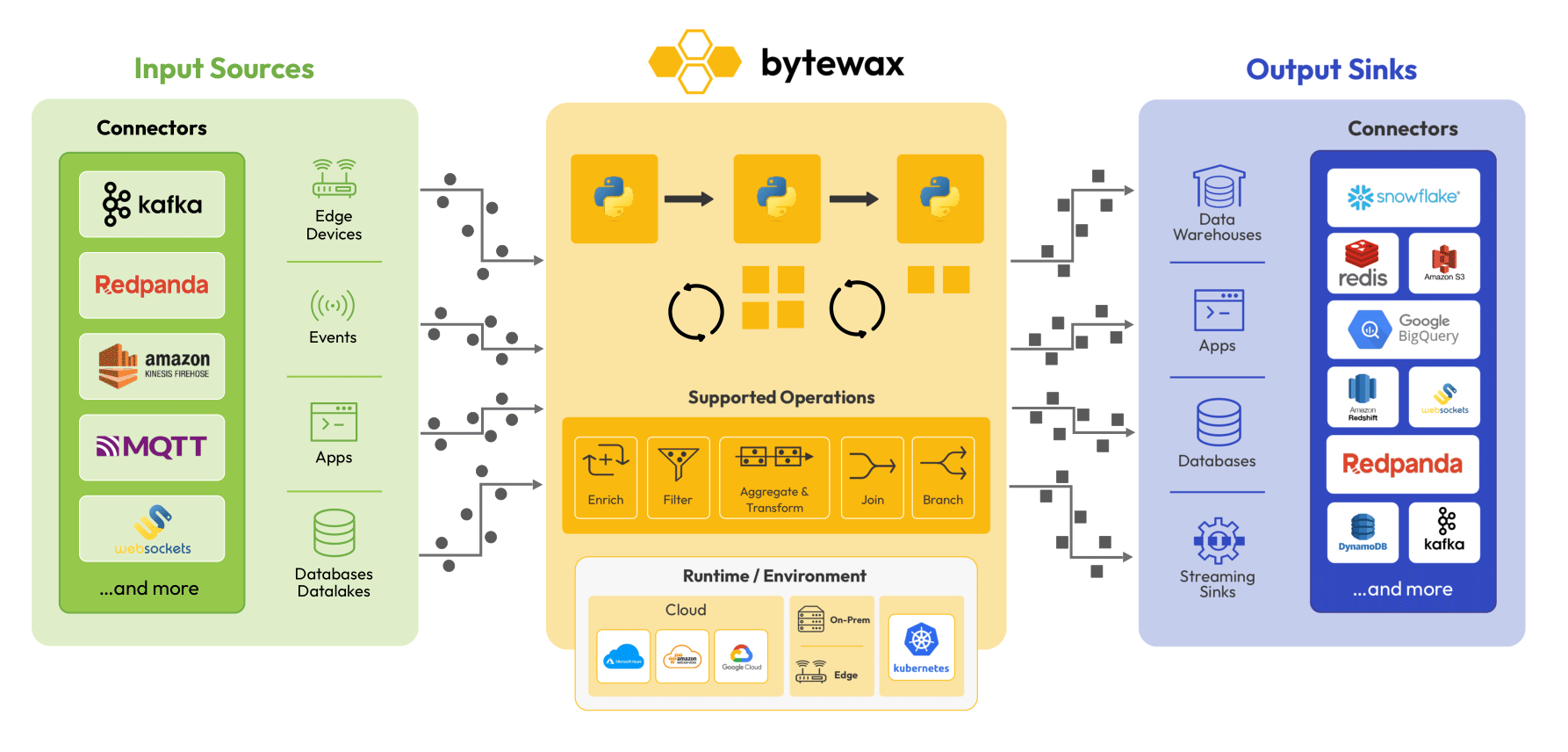
**Stateful operations:** Bytewax maintains distributed state, allows for fault tolerance and state recovery, and supports event-time windowing for advanced analytics and machine learning workloads.
**`waxctl`:** Bytewax’s CLI tool for deploying and managing dataflows on cloud servers or Kubernetes clusters. [Download `waxctl` here](https://bytewax.io/waxctl).
---
## Operators Overview
Operators are the building blocks of Bytewax dataflows:
- **Stateless Operators:** `map`, `filter`, `inspect`
- **Stateful Operators:** `reduce`, `fold_window`, `stateful_map`
- **Windowing & Aggregations:** Event-time, processing-time windows, tumbling, sliding, and session windows.
- **Joins & Merges:** Combine multiple input streams with `merge`, `join`, or advanced join patterns.
- **Premium Operators:**
For a comprehensive list, see the [Operators API Documentation](https://docs.bytewax.io/stable/api/bytewax/bytewax.operators.html).
---
## Connectors
Bytewax provides built-in connectors for common data sources and sinks such as Kafka, files, and stdout. You can also write your own [custom connectors](https://docs.bytewax.io/stable/guide/advanced-concepts/custom-connectors.html).
**Examples of Built-in Connectors:**
- **Kafka:** `bytewax.connectors.kafka`
- **StdIn/StdOut:** `bytewax.connectors.stdio`
- **Redis, S3, and More:** See [Bytewax connectors](https://docs.bytewax.io/stable/api/bytewax/bytewax.connectors.html).
**Community & Partner Connectors:** Check out the [Bytewax Module Hub](https://bytewax.io/modules) for additional connectors contributed by the community.
---
## Local Development, Testing, and Production
**Local Development:**
- Use `TestingSource` and `inspect` operators for debugging.
- Iterate quickly by running your flow with `python -m bytewax.run my_flow.py`.
- Develop custom connectors and sinks locally with Python tooling you already know.
**Testing:**
- Integration tests: Use `TestingSource` and run flows directly in CI environments.
- Unit tests: Test individual functions and operators as normal Python code.
- [More on Testing](https://docs.bytewax.io/stable/guide/contributing/testing.html)
**Production:**
- Scale horizontally by running multiple workers on multiple machines.
- Integrate with Kubernetes for dynamic scaling, monitoring, and resilience.
- Utilize `waxctl` for standardized deployments and lifecycle management.
---
## Deployment Options
### Running Locally
For experimentation and small-scale jobs:
```sh
python -m bytewax.run my_dataflow.py
```
Multiple workers and threads:
```sh
python -m bytewax.run my_dataflow.py -w 2
```
### Containerized Execution
Run Bytewax inside Docker containers for easy integration with container platforms. See the [Bytewax Container Guide](https://docs.bytewax.io/stable/guide/deployment/container.html).
### Scaling on Kubernetes
Use `waxctl` to package and deploy Bytewax dataflows to Kubernetes clusters for production workloads:
```sh
waxctl df deploy my_dataflow.py --name my-dataflow
```
[Learn more about Kubernetes deployment](https://docs.bytewax.io/stable/guide/deployment/waxctl.html).
### Scaling with the Bytewax Platform
Our commerically licensed Platform
---
## Examples
- [User Guide](https://docs.bytewax.io/stable/guide/index.html): End-to-end tutorials and advanced topics.
- [`/examples` Folder](examples): Additional sample dataflows and connector usage.
---
## Community and Contributing
Join us on [Slack](https://join.slack.com/t/bytewaxcommunity/shared_invite/zt-vkos2f6r-_SeT9pF2~n9ArOaeI3ND2w) for support and discussion.
Open issues on [GitHub Issues](https://github.com/bytewax/bytewax/issues) for bug reports and feature requests. (For general help, use Slack.)
**Contributions Welcome:**
- Check out the [Contribution Guide](https://docs.bytewax.io/stable/guide/contributing/contributing.html) to learn how to get started.
- We follow a [Code of Conduct](https://github.com/bytewax/bytewax/blob/main/CODE_OF_CONDUCT.md).
---
## License
Bytewax is licensed under the [Apache-2.0](https://opensource.org/licenses/APACHE-2.0) license.
---
Built with ❤️ by the Bytewax community