https://github.com/c-ehrlich/vocab-learn-order
Determine the optimal order to learn vocabulary and find sample sentences
https://github.com/c-ehrlich/vocab-learn-order
express material-ui mongodb nodejs react supertest typescript zod zustand
Last synced: 3 months ago
JSON representation
Determine the optimal order to learn vocabulary and find sample sentences
- Host: GitHub
- URL: https://github.com/c-ehrlich/vocab-learn-order
- Owner: c-ehrlich
- Created: 2022-02-14T18:25:45.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2022-07-04T12:32:25.000Z (almost 4 years ago)
- Last Synced: 2024-10-11T15:48:09.705Z (over 1 year ago)
- Topics: express, material-ui, mongodb, nodejs, react, supertest, typescript, zod, zustand
- Language: TypeScript
- Homepage: https://c-ehrlich.github.io/vocab-learn-order/
- Size: 44.7 MB
- Stars: 2
- Watchers: 1
- Forks: 0
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Vocab Learn Order
Live Demo: [https://c-ehrlich.github.io/vocab-learn-order](https://c-ehrlich.github.io/vocab-learn-order)
The backend is on a free Heroku instance, so please allow it a few seconds to spin up :)
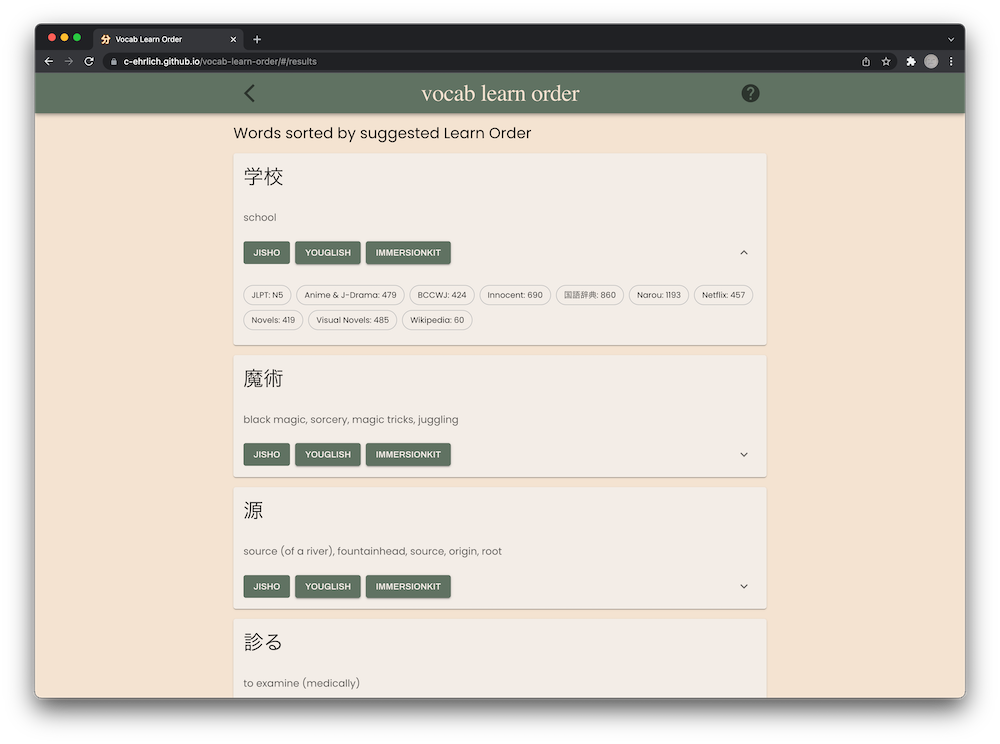
Vocab Learn Order is a web app for Japanese learners. Many immersion learners know the experience of listening to podcasts or other audio material in their target language, looking up unknown words, and then saving those words in a Notes file with the intent to learn them later with a tool such as Anki. But suddenly the file is several hundred words long and it's difficult to know which words to learn first to get the greatest benefit.
Frequency lists help with this somewhat, but as each frequency list is computed from a type of media, no single frequency list can give a realistic representation of how useful a given word is. Additionally, different learners have different goals - for some the highest priority is reading, for some it's business conversation, for some it's casual conversation, and so on.
By letting users decide how highly to weigh each frequency list, this app is able to create a much more accurate learn order than other methods. Additionally it makes Anki card creation much easier by giving access to sample sentences for each word through YouGlish and ImmersionKit. It's suitable for learners of all skill levels as the database is built on a dataset created specifically for this app, which contains frequency information for about 200,000 words, significantly more than most individual frequency lists.
## Table of Contents
- [Technologies](#technologies)
- [Installation and Setup](#installation-and-setup)
- [Development](#development)
- [Deployment](#deployment)
- [Reflection](#reflection)
## Technologies
* __Backend__: MongoDB, Node / Express with TypeScript, Mongoose / TypeGoose, Zod, Jest / Supertest
* __Frontend__: React with TypeScript, Zustand, React Router, Material UI, Jest / React Testing Library
* __Sample Deployment__: MongoDB Atlas (Database), Heroku (Backend), GitHub Pages (Frontend)
## Installation and Setup
### Development
1. Clone the repo
```
git clone https://github.com/c-ehrlich/vocab-learn-order.git
```
2. Run a local instance of MongoDB
```
mongod
```
3. Create .env files in `/backend` and `/frontend`, based on respective `sample.env` files
4. Install backend dependencies and start the backend development server
```
cd backend
yarn
yarn dev
```
5. Populate the development database
```
curl -X POST http://localhost:1337/api/filldatabase
-H 'Content-Type: application/json'
-d '{"privateKey": ""}'
```
6. Install frontend dependencies and start the frontend development server
```
cd frontend
yarn
yarn start
```
### Deployment
#### Database (MongoDB Atlas)
1. Create a new Database on MongoDB Atlas
2. Get the URI for the database and put in `/backend/.env`
3. After deploying the backend, populate the database
```
curl -X POST /api/filldatabase
-H 'Content-Type: application/json'
-d '{"privateKey": ""}'
```
#### Backend (Heroku)
1. Create a new Heroku app
2. Add environment variables to Heroku's "Config Vars" in the app settings, see `sample.env` for example
3. Add a `heroku` remote
```
heroku git:remote -a
```
4. From the project root directory, deploy the `/backend` folder
```
git subtree push --prefix backend heroku main
```
#### Frontend (GitHub Pages)
See the [Create React App documentation](https://create-react-app.dev/docs/deployment/) for more details.
1. Add a "homepage" item to `package.json` that points to where the app will be deployed. Example:
```
"homepage": "http://mywebsite.com/relativepath",
```
2. Add predeploy and deploy scripts to package.json
```
"scripts": {
+ "predeploy": "npm run build",
+ "deploy": "gh-pages -d build",
"start": "react-scripts start",
...
```
3. Run the `deploy` script
```
cd frontend
yarn deploy
```
#### Create custom Database Seed data
This is not necessary for a normal deployment. However it might be desireable in the future, for example in order to implement additional frequency lists, or to create a similar application for a different langauge. To achieve this:
* Most frequency lists come with a `-index.json` file. That file includes a `format` key. For this process to work, the format must be `3`. Fortunately most frequency lists are in that format. For frequency lists in a non-standard format, you will need to analyse their structure and adapt one of the existing algorithms in `/create-data/src/combine-frequency-lists.ts` to parse them.
* In `combine-frequency-lists.ts`:
1. Add the new frequency list to the `TWord` interface
2. Import the list
```ts
const listName: Format3Entry[] = require(`${fileLocation}`);
```
3. If the list is made up of multiple JSON files, import them all and concatenate into one array
4. Add the list to the `lists` variable
```ts
const lists: { list: Format3Entry[]; name: string }[] = [
{
list: ,
name: '',
},
...
```
* Create the combined Dictionary / Frequency List file __(warning: this will take quite long as we are iterating over several million items)__
```
cd create-data/src
npx ts-node combine-frequency-lists.ts
```
* Place the resulting `words-jmdict.json` file in `/backend/src/data`
* Register the new model fields in the backend in `/backend/src/model/word.model.ts` and `/backend/src/schema/word.schema.ts`
* Register the new model fields in the frontend in `/frontend/src/types/TWord.type.ts` and `/frontend/src/types/TFrequencyListWeights.type.ts`
* Delete the database if it is already populated
```
curl -X POST /api/deletedatabase
-H 'Content-Type: application/json'
-d '{"privateKey": ""}'
```
* Populate the database
```
curl -X POST /api/filldatabase
-H 'Content-Type: application/json'
-d '{"privateKey": ""}'
```
## Reflection
This app represented several new steps in my development as a Full Stack Engineer:
* Backend and Frontend developed fully in TypeScript
* Test suites for both backend and frontend
* Uses an established backend design framework (Route - Middleware - Controller - Service - Schema - Database)
I am proud of building another app that has real users, and of creating a well structured and maintaible full stack app for the first time. I made a lot of progress from the spaghetti code backends of my previous projects, and now have a template for developing good backends in the future. I was impressed by both the Developer Experience of using TypeScript, and the new development possiblities it gives, such as validating requests based on DB schema in a single line of code.
On the frontend, it was my first time building a significant UI using a Component Library (Material UI). In the past I had mostly just built my own UIs from scratch using Styled Components. I was impressed by how much time and how many lines of code it is possible to save by creating a themeing/design system before starting to build individual components, and how much a library helps with accessibility. It takes a bit of work to make a Material UI project not look like a stock Google app, but the result is worth it.
The part of the project that is quite messy is the `create-data` component. However given the current dictionaries and frequency lists it creates the desired output, and I don't think it will be necessary to change in the future. So in the spirit of YAGNI I decided to leave it as is for now and build it out in a more proper way if I do ever decide to build a new dataset.]
Due to how GitHub Pages hosts static content, I used HashRouter instead of BrowserRouter for url routing. This means that accessing for example `https://c-ehrlich.github.io/vocab-learn-order/foo` will result in a blank page instead of redirecting to the homepage or showing a 404. If this app were to be deployed somewhere else, this would be easy to fix by switching the routing implementation to BrowserRouter.
Populating the database through a backend route that is protected by a private key is not ideal as such a feature should not have a public endpoint at all. Keeping this functionality within the backend package means the Database Schema can be used to verify the incoming data, but putting this functionality in its own file that needs to be executed from the command line on the server would be a better approach in terms of security.
## Acknowledgements
* JLPT Vocab List from [stephenmk/yomichan-jkpt-vocab](https://github.com/stephenmk/yomichan-jlpt-vocab)