https://github.com/cdimascio/essence
Automatically extract the main text content (and more) from an HTML document
https://github.com/cdimascio/essence
extractor hacktoberfest html-extractor scraper web-content-extractor webpage-extractor website-extractor
Last synced: about 1 year ago
JSON representation
Automatically extract the main text content (and more) from an HTML document
- Host: GitHub
- URL: https://github.com/cdimascio/essence
- Owner: cdimascio
- License: apache-2.0
- Created: 2018-11-22T17:16:46.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2022-09-01T22:59:29.000Z (almost 4 years ago)
- Last Synced: 2025-03-28T08:11:13.334Z (about 1 year ago)
- Topics: extractor, hacktoberfest, html-extractor, scraper, web-content-extractor, webpage-extractor, website-extractor
- Language: Kotlin
- Homepage:
- Size: 1.93 MB
- Stars: 117
- Watchers: 6
- Forks: 16
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# essence
 [](https://search.maven.org/search?q=g:%22io.github.cdimascio%22%20AND%20a:%22essence%22) 
[](#contributors-)
An automatic web page content extractor for _Kotlin_ and _Java_.
Given an HTML document, **essence** automatically extracts the main text content (and much more).
[Try out the demo](https://essence.mybluemix.net) - _a simple webapp to demonstrate essence_.

_This library is inspired by [node-unfluff](https://github.com/ageitgey/node-unfluff) and its [lineage](#credits)_
## Usage
**Java**
```Java
import io.github.cdimascio.essence.Essence;
EssenceResult data = Essence.extract(html);
System.out.println(data.getText());
```
**Kotlin**
```Kotlin
val data = Essence.extract(html)
println(data.text)
```
See [Extracted data elements](#extracted-data-elements) for additional extracted metadata.
## Install
**Maven**
```xml
io.github.cdimascio
essence
0.13.0
pom
```
**Gradle**
```groovy
compile 'io.github.cdimascio:essence:0.13.0'
```
## Try the Essence web demo
[Essence web](https://essence.mybluemix.net) is a simple web page that fetches content at a given url and passes the HTML to this essence library.
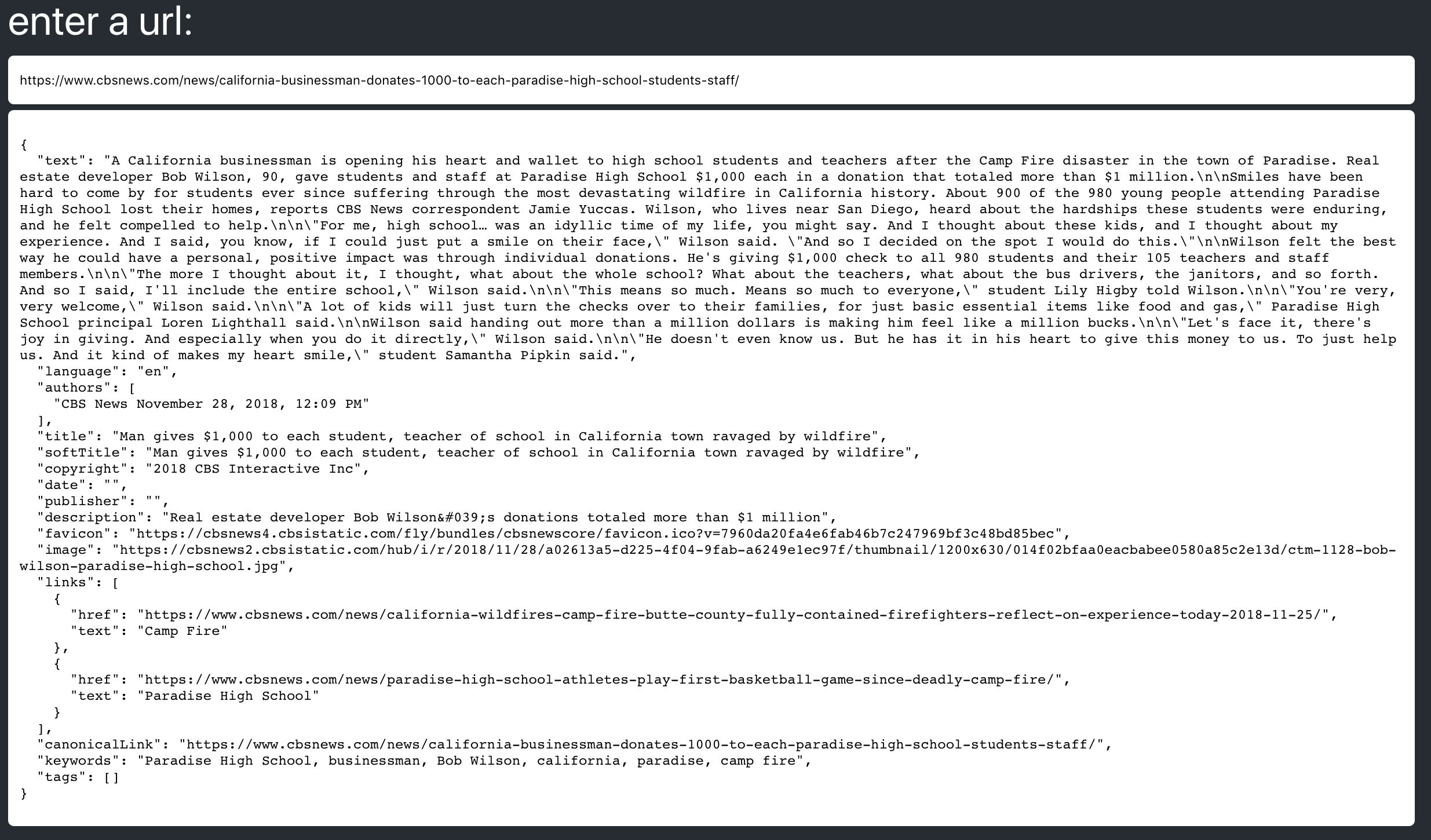
The essence web project lives [here](https://github.com/cdimascio/essence-web)
## Extracted data elements
**essence** attempts to extract the following content:
- `title` - The document's title
- `softTitle` - A version of `title` with less truncation
- `date` - The document's publication date
- `copyright` - The document's copyright line, if present
- `author` - The document's author
- `publisher` - The document's publisher (website name)
- `text` - The main text of the document with all the junk thrown away
- `image` - The main image for the document (what's used by facebook, etc.)
- *(coming soon...)*`videos` - An array of videos that were embedded in the article. Each video has src, width and height.
- `tags`- Any tags or keywords that could be found by checking <rel> tags or by looking at href urls.
- `canonicalLink` - The [canonical url](https://support.google.com/webmasters/answer/139066?hl=en) of the document, if given.
- `lang` - The language of the document, either detected or supplied by you.
- `description` - The description of the document, from <meta> tags
- `favicon` - The url of the document's [favicon](http://en.wikipedia.org/wiki/Favicon).
- `links` - An array of links embedded within the article text. (text and href for each)
## Credits
- node-unfluff by [https://github.com/ageitgey](ageitgey)
- python-goose by [Xavier Grangier](https://github.com/grangier)
- goose by [Gravity Labs](https://github.com/GravityLabs)
## License
[Apache 2.0](LICENSE)

## Contributors ✨
Thanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):
This project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome!
