https://github.com/cjams/whispertux
Simple GUI around whisper.cpp for voice dictation on Linux
https://github.com/cjams/whispertux
dictation linux openai prompt voice voice-assistant whisper
Last synced: 2 months ago
JSON representation
Simple GUI around whisper.cpp for voice dictation on Linux
- Host: GitHub
- URL: https://github.com/cjams/whispertux
- Owner: cjams
- License: mit
- Created: 2025-08-06T20:39:38.000Z (2 months ago)
- Default Branch: main
- Last Pushed: 2025-08-06T21:38:16.000Z (2 months ago)
- Last Synced: 2025-08-06T23:31:51.984Z (2 months ago)
- Topics: dictation, linux, openai, prompt, voice, voice-assistant, whisper
- Language: Python
- Homepage:
- Size: 4.03 MB
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# WhisperTux
Simple voice dictation application for Linux. Press the shortcut key, speak, press the shortcut key again, and text will appear in whatever app owns the cursor at the time.
Uses [whisper.cpp](https://github.com/ggml-org/whisper.cpp) for offline speech-to-text transcription.
No fancy GPUs are required although whisper.cpp is capable of using them if you have one available. Once your speech is transcribed, it is sent to a
[ydotool daemon](https://github.com/ReimuNotMoe/ydotool) that will write the text into the focused application.
Super useful for voice prompting AI models and speaking terminal commands.
Here's a quick [demo](https://www.youtube.com/watch?v=6uY2WySVNQE)
## Screenshots
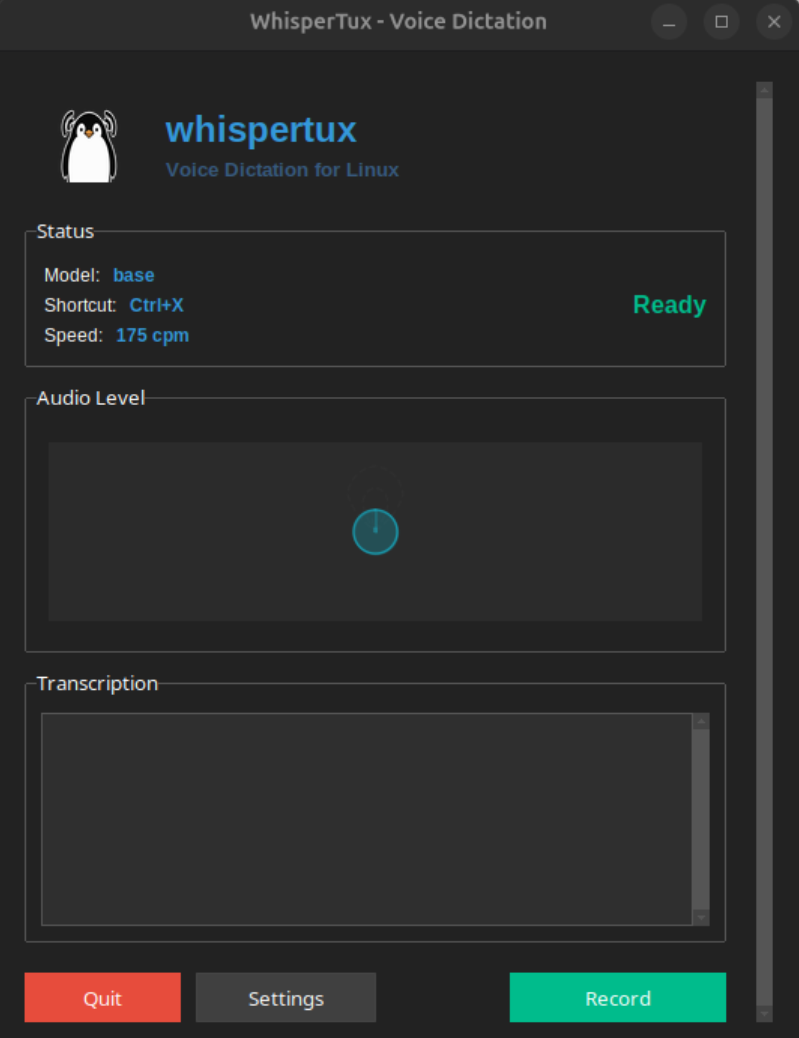
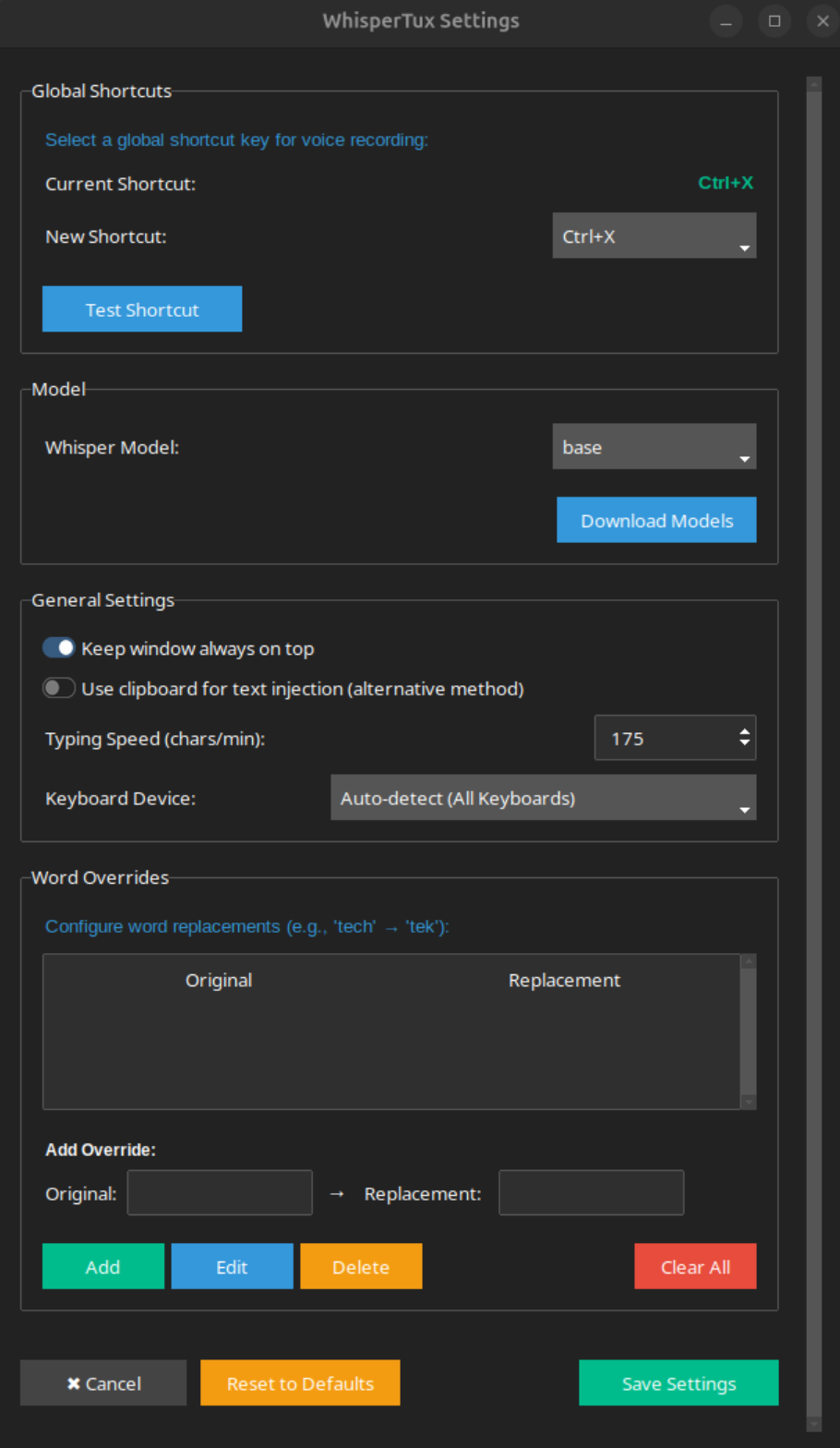
## Features
- Local speech-to-text processing via whisper.cpp (no cloud dependencies)
- No expensive hardware required (works well on a plain x86 laptop with AVX instructions)
- Global keyboard shortcuts for system-wide operation
- Automatic text injection into focused applications
- Configurable [whisper](https://github.com/openai/whisper) models and shortcuts
## Installation
Run the setup script:
```bash
git clone https://github.com/cjams/whispertux
cd whispertux
python3 setup.py
```
The setup script handles everything: system dependencies, creating Python virtual environment, building whisper.cpp, downloading models, configuring services, and testing the installation. See [setup.md](docs/setup.md) for details.
## Usage
Start the application:
```bash
./whispertux
# or
python3 main.py
```
### Desktop Integration (Optional)
After building the project, you can add WhisperTux to your desktop environment's applications menu:
```bash
# Create desktop entry for GNOME/KDE/other desktop environments
bash scripts/create-desktop-entry.sh
```
This will:
- Add WhisperTux to your applications menu
- Optionally configure it to start automatically on login
- Create proper desktop integration for launching from GUI
### Basic Operation
1. Press $GLOBAL_SHORTCUT (configurable within the app) to start recording
2. Speak clearly into your microphone
3. Press $GLOBAL_SHORTCUT again to stop recording
4. Transcribed text appears in the currently focused application
You can say 'tux enter' to simulate Enter keypress after you're done speaking for
automated carriage return.
You can also add overrides that will replace words before writing the
final output text. For example, if you want every instance of 'duck' to
be replaced by 'squirrel', you would add an override in the Word Overrides
section with Original being 'duck'.
## Configuration
Settings are stored in `~/.config/whispertux/config.json`:
```json
{
"primary_shortcut": "F12",
"model": "base",
"typing_speed": 150,
"use_clipboard": false,
"always_on_top": true,
"theme": "darkly",
"audio_device": null
}
```
### Available Models
Any [whisper](https://github.com/openai/whisper) model is usable. By default the
base model is downloaded and used. You can download additional models from within the app.
## System Requirements
- Linux with a GUI. Has only been tested on GNOME/Ubuntu but should work on others. Depends on evdev for handling low-level input events
- Python 3
- Microphone access
## Troubleshooting
### Global Shortcuts Not Working
Test shortcut functionality:
```bash
python3 -c "from src.global_shortcuts import test_key_accessibility; test_key_accessibility()"
```
### Audio Issues
Check microphone access:
```bash
python3 -c "from src.audio_capture import AudioCapture; print(AudioCapture().is_available())"
```
List available audio devices:
```bash
python3 -c "from src.audio_capture import AudioCapture; AudioCapture().list_devices()"
```
### Text Injection Problems
If you see `failed to open uinput device` errors, run the fix script:
```bash
./scripts/fix-uinput-permissions.sh
```
This script will:
- Add your user to the `input` and `tty` groups
- Create the necessary udev rule for `/dev/uinput` access
- Reload udev rules
You may need to log out and back in or reboot for group changes to take effect.
Verify ydotoold service status:
```bash
systemctl status ydotoold
sudo systemctl restart ydotoold # if needed
```
Test text injection directly:
```bash
ydotool type "test message"
```
### Whisper Model Issues
Check available models:
```bash
python3 -c "from src.whisper_manager import WhisperManager; print(WhisperManager().get_available_models())"
```
Download models manually:
```bash
cd whisper.cpp/models
bash download-ggml-model.sh base.en
```
## Documentation
- [Architecture](docs/architecture.md) - Technical architecture and component design
- [Setup Details](docs/setup.md) - Manual installation and system configuration
## License
MIT License