https://github.com/cnelias/integerib.jl
Information bottleneck's (IB) principle applied to categorical data clustering.
https://github.com/cnelias/integerib.jl
categorical-data clustering information-bottleneck julia
Last synced: 3 months ago
JSON representation
Information bottleneck's (IB) principle applied to categorical data clustering.
- Host: GitHub
- URL: https://github.com/cnelias/integerib.jl
- Owner: CNelias
- License: mit
- Created: 2020-08-13T12:34:18.000Z (about 5 years ago)
- Default Branch: master
- Last Pushed: 2022-12-13T17:07:38.000Z (almost 3 years ago)
- Last Synced: 2025-07-01T00:07:06.267Z (3 months ago)
- Topics: categorical-data, clustering, information-bottleneck, julia
- Language: Julia
- Homepage:
- Size: 57.6 KB
- Stars: 2
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
README
# IntegerIB.jl
A julia module to apply the **information bottleneck** for clustering when dealing with **categorical data**. It is now part of the package [CategoricalTimeSeries.jl](https://github.com/johncwok/CategoricalTimeSeries.jl)
| **Appveyor** |
|:---------------:|
|[](https://ci.appveyor.com/project/johncwok/integerib-jl)|
The information bottleneck concept can be used in the context of categorical data analysis to do **clustering**,
or in other words, to look for categories which have equivalent functions.
Given a time-series, it looks for a **concise representation** of the data that preserves as much **meaningful information** as possible.
In a sense, it is a lossy compression algorithm. The information to preserve can be seen as the ability to make predictions :
given a specific **context**, how much of what is coming next can we predict ?
The goal of this algorithm is to cluster categorical data while preserving predictive power. To learn more about the information bottleneck
you can look at *https://arxiv.org/abs/1604.00268* or *https://doi.org/10.1080/09298215.2015.1036888*
## Quick overview
To do a simple IB clustering of categorical data do as follow, you just need to instantiate a model and optimize it:
```Julia
data = readdlm("/path/to/data/")
model = IB(x) #you can call IB(x, beta). beta is a real number that controls the amount of compression.
IB_optimize!(model)
```
Then, to see the results :
```Julia
print_results(model)
```
Rows are clusters and columns correspond to the input categories. The result is the probability `p(t|x)` of a category belonging to a given cluster. Since most of the probabilities are very low, ```print_results``` **sets every `p(t|x)` > 0.1 to 1, 0 otherwise** for ease of readability (see further usage for more options).
#### example:
Here is a concrete example with a dataset chorales from Bach. The input categories are the 7 types of diatonic chords described in classical music theory.
```Julia
bach = CSV.read("..\\data\\bach_histogram")
pxy = Matrix(bach)./sum(Matrix(bach))
model = IB(pxy, 1000) #You can also instantiate 'model' with a probability distribution instead of a time-series.
IB_optimize!(model)
print_results(model)
```
The output is in perfect accordance with western music theory. It tells us that we can group category 1, 3 and 6 together : this corresponds to the ```tonic``` function in classical harmony. Category 2 and 4 have been clustered together, this is what harmony calls ```subdominant```. Finall category 5 and 7 are joined : this is the ```dominant``` function.

## Further usage
#### Types of algorithm:
You can choose between the original IB algorithm (Tishby, 1999) which does *soft* clustering or the *deterministic* IB algorithm (DJ Strouse, 2016) doing *hard* clustering. The former seems to produce more meaningfull clustering. When instantiating a model ```IB(x::Array{Float64,1}, β = 200, algorithm = "IB")```, change the argument `algorithm` to "DIB" to use the deterministic IB algorithm.
#### Changing default parameters:
The two most important parameters for this kind of IB clustering are the amount **compression** and the definition of **relevant context**.
- The amount of compression is governed by the parameter `β` which you provide when instantiating an IB model ```IB(x::Array{Float64,1}, β = 200, algorithm = "IB")```. The smaller `β` is, the more compression. The higher `β`, the bigger the mutual information I(X;T) between cluster and original category is.
There are two undesirable situations :
- if `β` is too small, maximal compression is achieved and all information is lost.
- if `β` is too high, there is effectively no compression. With "DIB" algorithm, this can even happen even for `β` > ~5. **In the case of the "IB" algorithm this doesn't happen**, however for `β` values > ~1000, the algorithm doesnt optimize anything because all metrics are effectively 0. In practice, when using the "IB" algorithm, a high `β` value (~200) is a good starting point.
- The definition of **context** is essential to specify what the meaningfull information to preserve is. The default behavior is to care about predictions, context is defined as the next element. For example, if we have a time-series ```x = ["a","b","c","a","b"]```, the context vector y is ```y = ["b","c","a","b"]```. We try to compress `x` in a representation that share as much informations with `y` as possible. Other definition of the context are possible : one can take the next element and the previous one. To do that that you would call :
```Julia
data = CSV.read("..\\data\\coltrane")
context = get_y(data, "an") # "an" stands for adjacent neighbors.
model = IB(data, context, 500) # giving the context as input during instantiation.
IB_optimize!(model)
```
#### Other functionalities
To get the value of the different **metrics** (*H(T), I(X;T), I(Y;T)* and *L*) use the `calc_metrics(model::IB)` function.
Since the algorithm is not 100% guaranteed to converge to a **global maxima**, you can use the ```search_optima!(model::IB, n_iter = 10000)``` to initialize and optimize your model `n_iter` times and select the optimization with the lowest `L` value. This is an in-place modification so you do not need to call `IB_optimize!(model::IB)` after calling `search_optima!`.
If you want to get the **raw probabilities** `p(t|x)` after optimization (`print_results` filters it for ease of readability), you can access them with :
```Julia
pt_x = model.qt_x
```
Similarly, you can also get p(y|t) or p(t) with `model.qy_t` and `model.qt`.
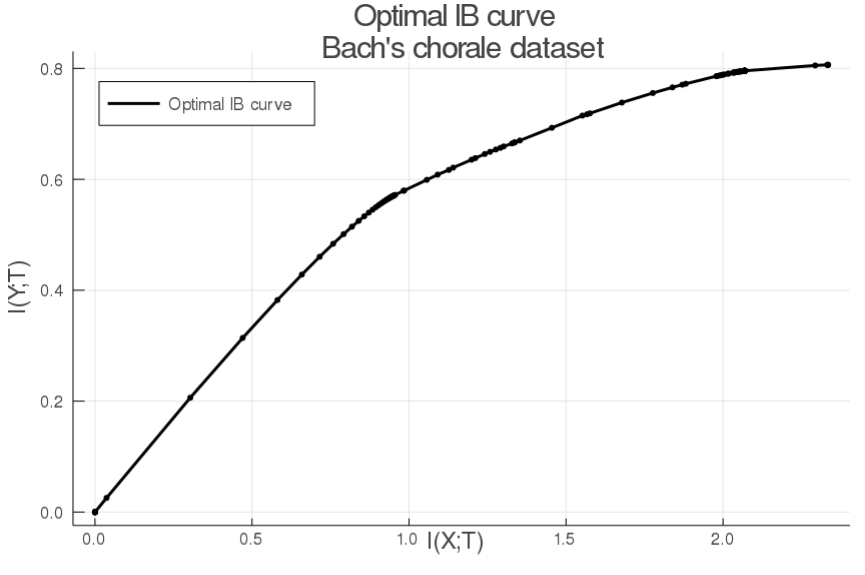
Finally, the function `get_IB_curve(m::IB, start = 0.1, stop = 400, step = 0.05; glob = false)` lets you plot the **"optimal" IB curve**. Here is an example with the bach chorale dataset:
```Julia
using Plots
bach = CSV.read("..\\data\\bach_histogram")
pxy = Matrix(bach)./sum(Matrix(bach))
model = IB(pxy, 1000)
x, y = get_IB_curve(model)
a = plot(x, y, color = "black", linewidth = 2, label = "Optimal IB curve", title = "Optimal IB curve \n Bach's chorale dataset")
scatter!(a, x, y, color = "black", markersize = 1.7, xlabel = "I(X;T) \n", ylabel = "- \n I(Y;T)", label = "", legend = :topleft)
```
### Citing
If you used this module in a scientific publication, please consider citing the package it came from:
```Bibtex
@article{nelias2021categoricaltimeseries,
title={CategoricalTimeSeries. jl: A toolbox for categorical time-series analysis},
author={Nelias, Corentin},
journal={Journal of Open Source Software},
volume={6},
number={67},
pages={3733},
year={2021}
}
```
#### Installation & import:
```Julia
Using Pkg
Pkg.clone(“https://github.com/johncwok/IntegerIB.jl.git”)
Using IntegerIB
```
## Acknowledgments
Special thanks to Nori jacoby from whom I learned a lot on the subject. The IB part of this code was tested with his data and reproduces his results.
The present implementation is adapted from DJ Strouse's paper https://arxiv.org/abs/1604.00268 and his python implementation.
## To-do
* improve display of results (with PrettyTables.jl ?)
* Implement simulated annealing to get global maxima in a more consistent fashion.