Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/coderofsalvation/webpipe.bash
extend your bash using webpipes, aka bash-in-the-cloud
https://github.com/coderofsalvation/webpipe.bash
Last synced: 12 days ago
JSON representation
extend your bash using webpipes, aka bash-in-the-cloud
- Host: GitHub
- URL: https://github.com/coderofsalvation/webpipe.bash
- Owner: coderofsalvation
- Created: 2014-02-13T11:26:18.000Z (over 10 years ago)
- Default Branch: master
- Last Pushed: 2020-05-28T19:31:49.000Z (over 4 years ago)
- Last Synced: 2023-03-24T12:56:31.743Z (over 1 year ago)
- Language: Shell
- Size: 196 KB
- Stars: 4
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Funding: .github/FUNDING.yml
Awesome Lists containing this project
README
Webpipe.bash
============

Webpipes empower your bash-environment with remote executed applications, aka Bash in the Cloud.
### Why
Expose your webapplication as unix commands.
Write less html-interfaces, write more glue.
Mashup your webpipes, mashup your api.

### Installation
Its very simple, first get webpipe.bash
wget https://raw.github.com/coderofsalvation/webpipe.bash/master/webpipe
Now the only thing you need to do is index some online webpipes:
source webpipe
webpipe::index http://neon-semiotics-490.appspot.com
Done! Now you can just use a webpipe in your terminal as if it were a local unix command.
### Example of a webpipe
Show usage:
$ xpath
Usage: echo | xpath [options]
prints values from xml based on given xpath (can be commaseperated)
Options:
--dumppath dump xpath instead of values
--dumppathvalues dump xpath with values
--manual show examples/syntax
--html input is html instead of xml
--source dont strip tags
Examples:
echo '123' | xpath //foo/bar
echo '123' | xpath //* --dumppath
echo '123' | xpath //* --dumppathvalues
Execute it:
$ cat foo.xml | xpath //order/customer/name
John Doe
Would you believe this just happened in the cloud?
Well it did..
### How it works

### Indexing a single webpipe
You can also import a batch of webpipes all at once like this:
source webpipe
webpipe::set webpipe http://localhost/mypipe
Voila..now mypipe is indexed..
### Always anywhere
Put this in your .bashrc :
source ~/bin/webpipe
webpipe::indexcache # this loads webpipes from cache (faster)
### Show webpipes
$ webpipe::list
mypipe -> http://localhost/mypipe
xpath -> http://neon-semiotics-490.appspot.com/xpath
cssselect -> http://neon-semiotics-490.appspot.com/cssselect
csv2json -> http://neon-semiotics-490.appspot.com/csv2json
json2csv -> http://neon-semiotics-490.appspot.com/json2csv
json_print_r -> http://neon-semiotics-490.appspot.com/json_print_r
jsonpath -> http://neon-semiotics-490.appspot.com/jsonpath
markdown -> http://neon-semiotics-490.appspot.com/markdown
striphtml -> http://neon-semiotics-490.appspot.com/striphtml
url2html -> http://neon-semiotics-490.appspot.com/url2html
xml2json -> http://neon-semiotics-490.appspot.com/xml2json
mycommand -> http://foo.bar.com/mycommand
sendmail -> http://foo.bar.com/sendmail
notifypentagon -> http://foo.bar.com/notifypentagon
makecoffee -> http://foo.bar.com/makecoffee
notifypentagon -> http://foo.bar.com/notifypentagon
### Reset
Reset all your indexed webpipes
webpipe::reset
### How can I build my own webpipes in the cloud?
Simple, a webpipe is just a weburl which listens to a POST-request (for data) or OPTIONS-request (for displaying help).
Basically all GET-, POST- etc arguments are combined into one object, which processed by the webpipe.
The webpipe returns output which suits the content-type.
So with 'application/json':
{"output":["foo","bar"]}
Could be with 'text/plain' (a unix webpipe)
foo
bar
For php there's this skeleton [repository](https://github.com/coderofsalvation/webpipe.bash.php).
### But I'm in love with JSON/
The commandline is great, but yes, at some point JSON becomes preferrable (to avoid complex oneliners).
Lets take the xpath example above, imagine we have 10 other arguments.
In that case it might be handy to hide our complexity in a json payload file:
$ cat > payload.json
{
"path": "//order/customer/name"
"input": "$pipe"
}
(CTRL-D)
$ cat foo.xml | xpath payload.json
John Doe
Whenever the first argument is a jsonfile, Webpipe.bash will do a POST-request with content-type 'application/json'.
### Capture/Replay
You can inspect your payload anywhere in the pipeline.
$ cat foo.xml | CAPTURE=1 log --job | filter --inactive --retired | CAPTURE=1 xpath payload.json
written 'log.payload.10928391.json'
written 'xpath.payload.10928392.json'
And replay it (usefull for testing/debugging):
$ log log.payload.10928391.json
$ xpath xpath.payload.10928391.json
### RESTful?
$ cat foo.xml | X=DELETE TYPE="application/soap+xml" somewebpipe payload.json
However, this is not really the focus of webpipes, see [RESTY](https://github.com/micha/resty) for easily testing REST api's and such.
### Basic design of UNIX webpipe
Webpipes usually work with 'application/json' which is fine.
But unix output (tab-delimited e.g.) can be implemented by listening to content-type 'text/plain':
$ mywebpipe foobar --foo bar
would result in a 'text/plain' GET-request:
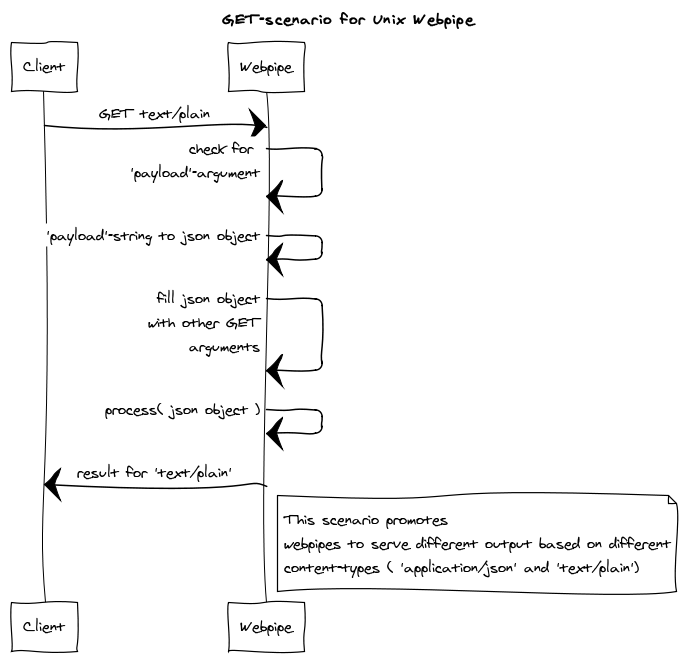
$ cat foo.json | webpipe --foo bar
would result in a 'text/plain' POST-request:
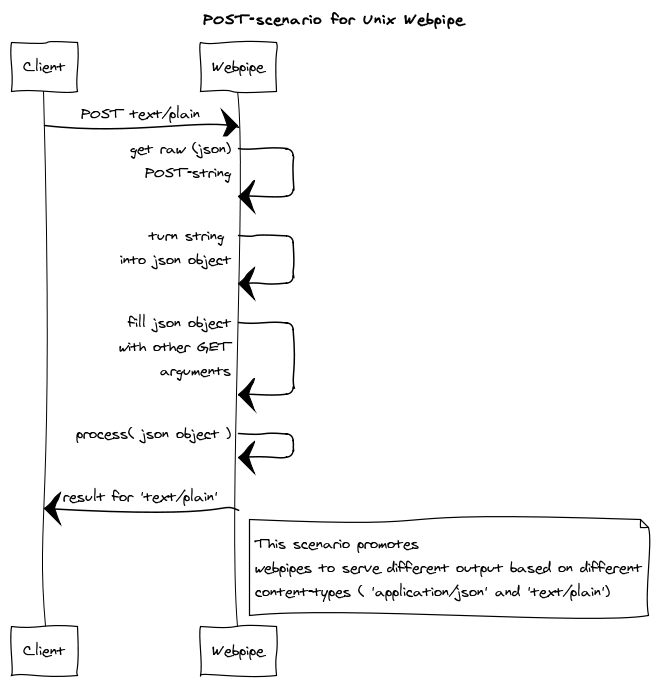
$ mywebpipe
Usage: mywebpipe [-foo ]
This would result in an 'text/plain' OPTIONS-request (which should return information on usage)
### Projects using webpipe.bash
* www.bashlive.com ( supernatural livecoding using bash )
### Security
Sourcing output of remote procedures from untrusted sources is never adviced.
However, in case your webpipes needs authorisation (.htaccess .htpasswd e.g.) run, decorate the curl calls with this:
webpipe::set curloptions http://foo.com "-user foo:bar"
By doing so, the webpipe (called by curl) will pass authorisation info.
# Compatibility with WebPipe Specification 0.2
The webpipes above are more or less compatible.
One exception is that requests (with content-type 'plain/text', used in the example above) uses single-input single-output.
This is to easify unix commandline development, in contrast to the multi-jsoninput multi-jsonoutput requirement of the webpipe 0.2.
`(Jeff: if you read this, please contact me)`
However, the multi-jsoninput multi-jsonoutput requirement *should* apply when you call it with content-type 'application/json'.
Some examples:
$ curl -X POST -H 'Content-Type: text/plain' http://localhost/foobar
# should return the processed value ("some value for bar" e.g.)
$ curl -X POST -H 'Content-Type: application/json' -d '{"inputs":[{"css":".foo { font-weight:bold; }"}]}' http://localhost/foobar
# should return: {"outputs": [{"bar": "some value for bar"}]}
$ curl -X OPTIONS -H 'Content-Type: text/plain' http://localhost/foobar
# should return usage text like 'Usage: foo ' e.g. (see top of this page)
$ curl -X OPTIONS -H 'Content-Type: application/json' http://localhost/foobar
# should return a json schema like so:
# {
# name: String
# url: String
# description: String
# inputs: {
# name: String
# type: String (Array, String, Number, Boolean)
# description: String
# optional?: Boolean
# default?: Any
# }
# outputs: {
# name: String
# type: String (Array, String, Number, Boolean)
# description: String
# }
# }
$ curl -X TRACE http://localhost/foobar
# debugs / runs unit test(s) e.g.
However, this multi-in multi-out-assumption of the specs doesnt really fit my needs, therefore for practical reasons contenttypes 'text/plain' and 'text/html' default to single-textinput single-textoutput..the default behaviour of any webserver.
### Commandline argument to getarguments
By default webpipe.bash will send http using the 'text/plain'-content-type.
Positional parameters will be converted to GET variable '1' / '2' and so on, like so:
mywebpipe somevar --foo bar --foo2 bar2
In the webpipe itself this will be received as GET variables:
'1': 'somevar',
'foo': 'bar',
'foo2': 'bar2'
This makes it easy to start developing a webpipe by using webpipe.bash as a startingpoint:
$ webpipe::set webpipe http://localhost/mynewwebpipe
$ mynewwebpipe hellowrodl --foo bar
404 Not found
method: GET
Get args: '1' => hellowrodl
'foo' => bar
$ echo "fooo" | mynewwebpipe hellowrodl --foo bar
404 Not found
method: POST
Get args: '1' => hellowrodl
'foo' => bar
Post payload: 'foooo'
### Further Thoughts
* webpipe is easy to scale
* install once, usable anywhere
* centralize certain functionality on certain server
* prevent a developer becoming 'the guy' within a team
* teams dont need graphical user interfaces
* teams need something pipable
* prevents a large codebase
* spread domainknowledge across webpipes instead of bundling in 1 codebase
* bash can be an interface between programmers with different backgrounds
* unix pipelining is a service bus in certain perspective
* webpipes need tests
* webpipes need to notify a central place in case of problems .e.g