https://github.com/core-go/io
csv csv-parser export file file-export file-import file-reader file-writer filereader files filewriter fix-length fix-length-parser import io zip
Last synced: 2 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/core-go/io
- Owner: core-go
- Created: 2020-06-24T04:14:30.000Z (about 6 years ago)
- Default Branch: main
- Last Pushed: 2024-09-08T16:59:13.000Z (almost 2 years ago)
- Last Synced: 2025-01-10T04:14:56.570Z (over 1 year ago)
- Topics: csv, csv-parser, export, file, file-export, file-import, file-reader, file-writer, filereader, files, filewriter, fix-length, fix-length-parser, import, io, zip
- Language: Go
- Homepage:
- Size: 115 KB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# IO
- Utilities to load file, save file, zip file
- File Stream Writer
- File Stream Reader
- Implement ETL process for Data Processing, Business Intelligence
You can refer to [ETL Tool Programming vs Traditional Programming](https://www.linkedin.com/pulse/etl-tool-programming-vs-traditional-duc-nguyen-jb2gc) and [Data Processing](https://www.linkedin.com/pulse/data-processing-golang-nodejs-duc-nguyen-wv33c) at my [Linked In](https://vn.linkedin.com/in/duc-nguyen-437240239?trk=article-ssr-frontend-pulse_publisher-author-card) for more details.
## ETL (Extract-Transform-Load)
Extract-Transform-Load (ETL) is a data integration process involving the extraction of data from various sources, transformation into a suitable format, and loading into a target database or data warehouse.
- Extracting data from various sources.
- Transforming the data into a suitable format/structure.
- Loading the transformed data into a target database or data warehouse.
## Batch processing
- [core-go/io](https://github.com/core-go/io) is designed for batch processing, enabling the development of complex batch applications. It supports operations such as reading, processing, and writing large volumes of data.
- [core-go/io](https://github.com/core-go/io) is not an ETL tool. It provides the necessary libraries for implementing ETL processes. It allows developers to create jobs that extract data from sources, transform it, and load it into destinations, effectively supporting ETL operations.
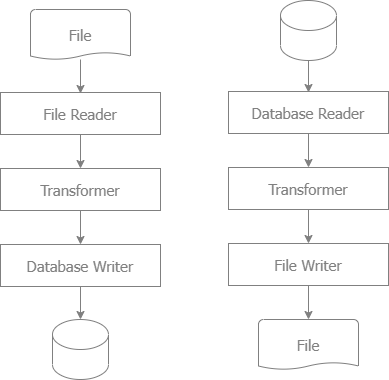
### Use Cases of [core-go/io](https://github.com/core-go/io) in ETL:
- Data Migration: Moving and transforming data from legacy systems to new systems.
- Data Processing: Handling large-scale data processing tasks like data cleansing and transformation
- Data Warehousing: Loading and transforming data into data warehouses.
- Business Intelligence: Transforming raw data into meaningful insights for decision-making, to provide valuable business insights and trends.
## Specific Use Cases of [core-go/io](https://github.com/core-go/io)
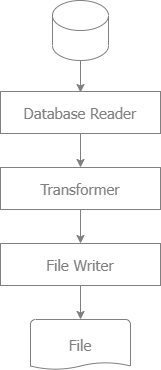
### Export from database to file
#### Common Mistakes
- Inefficient Writing to I/O: Large writing to I/O can slow down performance. Writing each record immediately without buffering is inefficient due to the high overhead of repeated I/O operations.
- Solution: Use "bufio.Writer" for more efficient writing.
- Loading All Data Into Memory: Fetching all records at once can consume a lot of memory, causing the program to slow down or crash. Use streaming with cursors instead.
- Solution: Loop on each cursor. On each cursor, use bufio.Writer to write to database
- Inefficient Query: Full scan the table. Do not filter on the index.
- Solution: If you export the whole table, you can scan the full table. If not, you need to filter on the index.
#### Flow to export from SQL to files

#### Implementation
#### Data Reader for SQL
1. Build Query: For efficient query, you need to filter on the index, avoid to scan the full table. In my sample, I created index on field createdDate. In my 6 use cases, I use 4 use cases to filter on indexing field: createdDate.
2. Scan the GO row into an appropriate GO struct:
We provide a function to map a row to a GO struct. We use gorm tag, so that this struct can be reused for gorm later, with these benefits:
- Simplifies the process of converting database rows into Go objects.
- Reduces repetitive code and potential errors in manual data mapping.
- Enhances code readability and maintainability.
```go
type User struct {
Id string `gorm:"column:id;primary_key" format:"%011s" length:"11"`
Username string `gorm:"column:username" length:"10"`
Email string `gorm:"column:email" length:"31"`
Phone string `gorm:"column:phone" length:"20"`
Status bool `gorm:"column:status" true:"1" false:"0" format:"%5s" length:"5"`
CreatedDate *time.Time `gorm:"column:createdDate" length:"10" format:"dateFormat:2006-01-02"`
}
```
#### Transformer
Transform a GO struct to a string (CSV or fixed-length format). We created 2 providers already:
- CSV Transformer: read GO tags to transform CSV line.
- Fixed Length Transformer: read GO tags to transform Fixed Length line.
To improve performance, we cache the struct of CSV or Fixed Length Format.
#### File Writer
- It is a wrapper of "bufio.Writer" to buffer writes to the file. This reduces the number of I/O operations.
#### Key Aspects to improve performance:
- Streaming: The code uses db.QueryContext to fetch records in a streaming manner. This prevents loading all records into memory at once.
- Memory Management: Since rows are processed one by one, memory usage remains low, even when handling a large number of records.
- Cache Scanning: to improve performance: based on gorm tag, cache column structure when scanning the GO row into an appropriate GO struct.
- Cache Transforming: to improve performance, cache CSV or fixed-length format structure when transforming a GO struct into CSV format or fixed-length format.
#### Samples:
- [go-sql-export](https://github.com/project-samples/go-sql-export): export data from sql to fix-length or csv file.
- [go-hive-export](https://github.com/project-samples/go-hive-export): export data from hive to fix-length or csv file.
- [go-cassandra-export](https://github.com/project-samples/go-cassandra-export): export data from cassandra to fix-length or csv file.
- [go-mongo-export](https://github.com/project-samples/go-mongo-export): export data from mongo to fix-length or csv file.
- [go-firestore-export](https://github.com/project-samples/go-firestore-export): export data from firestore to fix-length or csv file.
### Import from file to database

- Detailed flow to import from file to database

#### Samples:
- [go-sql-import](https://github.com/project-samples/go-sql-import): import data from fix-length or csv file to sql.
- [go-hive-import](https://github.com/project-samples/go-hive-import): import data from fix-length or csv file to hive.
- [go-cassandra-import](https://github.com/project-samples/go-cassandra-import): import data from fix-length or csv file to cassandra.
- [go-elasticsearch-import](https://github.com/project-samples/go-elasticsearch-import): import data from fix-length or csv file to elasticsearch.
- [go-mongo-import](https://github.com/project-samples/go-mongo-import): import data from fix-length or csv file to mongo.
- [go-firestore-import](https://github.com/project-samples/go-firestore-import): import data from fix-length or csv file to firestore.
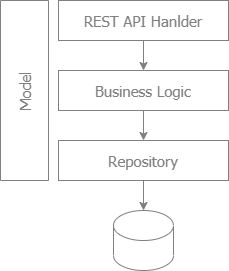
##### Layer Architecture
- Popular for web development
##### Hexagonal Architecture
- Suitable for Import Flow
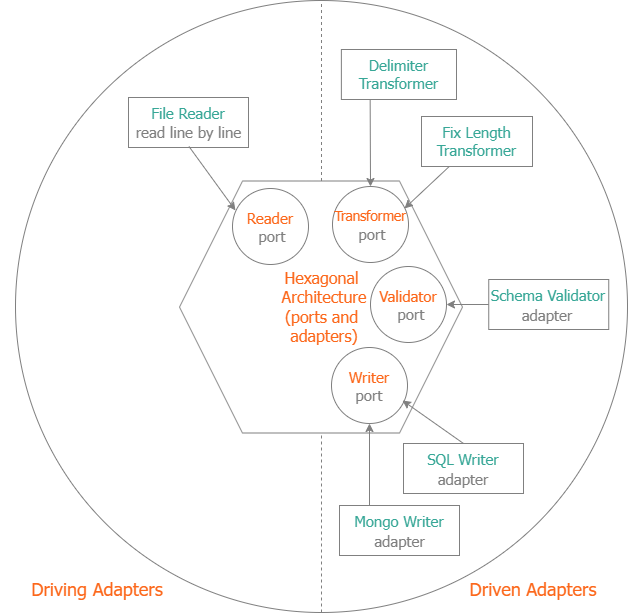
##### Based on the flow, there are 4 main components (4 main ports):
- Reader, Validator, Transformer, Writer
##### Reader
Reader Adapter Sample: File Reader. We provide 2 file reader adapters:
- Delimiter (CSV format) File Reader
- Fix Length File Reader
##### Validator
- Validator Adapter Sample: Schema Validator
- We provide the Schema validator based on GOLANG Tags
##### Transformer
We provide 2 transformer adapters
- Delimiter Transformer (CSV)
- Fix Length Transformer
##### Writer
We provide many writer adapters:
- SQL:
- [SQL Writer](https://github.com/core-go/sql/blob/main/writer/writer.go): to insert or update data
- [SQL Inserter](https://github.com/core-go/sql/blob/main/writer/inserter.go): to insert data
- [SQL Updater](https://github.com/core-go/sql/blob/main/writer/updater.go): to update data
- [SQL Stream Writer](https://github.com/core-go/sql/blob/main/writer/stream_writer.go): to insert or update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- [SQL Stream Inserter](https://github.com/core-go/sql/blob/main/writer/stream_inserter.go): to insert data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush. Especially, we build 1 single SQL statement to improve the performance.
- [SQL Stream Updater](https://github.com/core-go/sql/blob/main/writer/stream_updater.go): to update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- Mongo:
- [Mongo Writer](https://github.com/core-go/mongo/blob/main/writer/writer.go): to insert or update data
- [Mongo Inserter](https://github.com/core-go/mongo/blob/main/writer/inserter.go): to insert data
- [Mongo Updater](https://github.com/core-go/mongo/blob/main/writer/updater.go): to update data
- [Mongo Stream Writer](https://github.com/core-go/mongo/blob/main/batch/stream_writer.go): to insert or update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- [Mongo Stream Inserter](https://github.com/core-go/mongo/blob/main/batch/stream_inserter.go): to insert data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- [Mongo Stream Updater](https://github.com/core-go/mongo/blob/main/batch/stream_updater.go): to update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- Elastic Search
- [Elastic Search Writer](https://github.com/core-go/elasticsearch/blob/main/writer/writer.go): to insert or update data
- [Elastic Search Creator](https://github.com/core-go/elasticsearch/blob/main/writer/creator.go): to create data
- [Elastic Search Updater](https://github.com/core-go/elasticsearch/blob/main/writer/updater.go): to update data
- [Elastic Search Stream Writer](https://github.com/core-go/elasticsearch/blob/main/batch/stream_writer.go): to insert or update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- [Elastic Search Stream Creator](https://github.com/core-go/elasticsearch/blob/main/batch/stream_creator.go): to create data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- [Elastic Search Stream Updater](https://github.com/core-go/elasticsearch/blob/main/batch/stream_updater.go): to update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- Firestore
- [Firestore Writer](https://github.com/core-go/firestore/blob/main/writer/writer.go): to insert or update data
- [Firestore Updater](https://github.com/core-go/firestore/blob/main/writer/updater.go): to update data
- Cassandra
- [Cassandra Writer](https://github.com/core-go/cassandra/blob/main/writer/writer.go): to insert or update data
- [Cassandra Inserter](https://github.com/core-go/cassandra/blob/main/writer/inserter.go): to insert data
- [Cassandra Updater](https://github.com/core-go/cassandra/blob/main/writer/updater.go): to update data
- Hive
- [Hive Writer](https://github.com/core-go/hive/blob/main/writer/writer.go): to insert or update data
- [Hive Inserter](https://github.com/core-go/hive/blob/main/writer/inserter.go): to insert data
- [Hive Updater](https://github.com/core-go/hive/blob/main/writer/updater.go): to update data
- [Hive Stream Updater](https://github.com/core-go/hive/blob/main/batch/stream_writer.go): to update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
## ETL Tool Programming vs Traditional Programming
#### ETL for Simple Transformations
- Ease of Use: ETL tools are designed to handle straightforward data extraction, transformation, and loading processes efficiently. Simple operations like data type conversions, string manipulations, and basic arithmetic are typically easy to implement and perform well.
- Graphical Interfaces: Many ETL tools provide intuitive graphical interfaces that allow users to design and implement simple transformations without deep programming knowledge, speeding up the development process.
#### ETL for Complex Transformations
- Performance Concerns: When dealing with more complex logic such as loops and conditional statements, ETL processes can become less efficient. This is because ETL tools are often optimized for set-based operations rather than iterative ones, which can lead to slower performance compared to traditional programming languages.
- Increased Complexity: Writing complex logic in ETL tools can be cumbersome and less readable compared to general-purpose programming languages. The logic might be scattered across various transformation steps, making it harder to maintain and debug.
- Limited Flexibility: ETL tools may have limitations in terms of the programming constructs they support. This can make it challenging to implement certain algorithms or logic that would be straightforward in a traditional programming language.
### Comparative Analysis
#### Programming Languages (e.g., Java, Go, Python, nodejs):
##### Advantages:
- Flexibility: Full programming languages offer greater flexibility and control over the code, allowing for complex logic, custom functions, and advanced algorithms.
- Performance: For complex transformations, especially those involving iterative processes or conditionals, programming languages can be optimized for better performance.
- Libraries and Frameworks: A rich ecosystem of libraries and frameworks can be leveraged to handle specific tasks efficiently.
##### Disadvantages:
- Development Time: Writing ETL processes from scratch in a programming language can be time-consuming, especially for simple tasks that ETL tools can handle out-of-the-box.
- Learning Curve: Requires more in-depth programming knowledge, which can be a barrier for non-developers or those new to programming.
#### ETL Tools (e.g., Talend, Informatica, Apache NiFi):
##### Advantages:
- Ease of Use: Designed to simplify the ETL process with user-friendly interfaces and pre-built connectors for various data sources.
- Speed for Simple Tasks: Quick to implement and deploy simple transformations and data movements.
- Maintenance: Easier to maintain for straightforward ETL tasks due to visual workflows and less code complexity.
##### Disadvantages:
- Performance: Can be less performant for complex logic involving loops and conditionals.
- Complexity for Advanced Tasks: As the complexity of the transformations increases, ETL tools can become cumbersome and harder to manage.
- Limited Control: Less flexibility in implementing highly customized logic or optimizations compared to traditional programming languages.
### Can we have a solution, which has the advantages of both ETL and traditional programming?
I am finding a solution, which has the advantages of both ETL and traditional programming. Let's analyze 2 common use cases of ETL:
#### ETL
- Reader and Writer: ETL is mostly useful.
- Transformation: ETL is useful for simple transformation only.
#### Programming Languages
##### For File Reader, Database Reader and File Writer, Database Writer:
- Libraries and Frameworks: Please refer to [core-go/io](https://github.com/core-go/io), we provide a rich ecosystem of libraries, which can be leveraged to handle specific tasks efficiently like ETL tool (The effort is still higher than ELT tool, but very small).
- We also have this advantage of ETL tool: Speed for Simple Tasks.
- Maintenance: with to [core-go/io](https://github.com/core-go/io), we provide the descriptive language for GO and nodejs, it is easier to maintain like ETL Tool.
##### For transformation:
- Flexibility: for complicated tasks, full programming languages offer greater flexibility and control over the code, allowing for complex logic, custom functions, and advanced algorithms.
- Performance: for complex transformations, especially those involving iterative processes or conditionals, programming languages can be optimized for better performance.
### Conclusion
- The above advantages and disadvantages are key considerations in choosing between ETL tools and traditional programming for data transformation tasks. For simple and straightforward ETL processes, ETL tools can offer significant advantages in terms of ease of use and development speed. However, for more complex transformations involving intricate logic, loops, and conditionals, traditional programming languages might offer better performance, flexibility, and maintainability.
- Ultimately, the choice depends on the specific requirements of the ETL process, the complexity of the transformations, and the skill set of the team involved. A hybrid approach, where simple tasks are handled by ETL tools and complex logic is implemented in a programming language, can also be a viable solution.
- With [core-go/io](https://github.com/core-go/io) for GOLANG and a rich ecosystem of libraries for nodejs, we offer a hybrid approach, which can handle complex logic in a programming language, but also leverage to handle specific tasks efficiently by programming at reader and writer.
## Summary
### File Reader
- File Stream Reader
- Delimiter (CSV format) File Reader
- Fix Length File Reader
### File Writer
- File Stream Writer
#### Delimiter (CSV format) Transformer
- Transform an object to Delimiter (CSV) format
- Transform an object to Fix Length format
## Appendix
### Import and export data for nodejs
#### Export data for nodejs:
##### Key features
- [onecore](https://www.npmjs.com/package/onecore): Standard interfaces for typescript to export data.
- [io-one](https://www.npmjs.com/package/io-one): File Stream Writer, to export data to CSV or fix-length files by stream.
##### Libraries to receive rows as stream, to export each record one by one:
- Postgres: [pg-exporter](https://www.npmjs.com/package/pg-exporter) to wrap [pg](https://www.npmjs.com/package/pg), [pg-query-stream](https://www.npmjs.com/package/pg-query-stream), [pg-promise](https://www.npmjs.com/package/pg-promise).
- Oracle: [oracle-core](https://www.npmjs.com/package/oracle-core) to wrap [oracledb](https://www.npmjs.com/package/oracledb).
- My SQL: [mysql2-core](https://www.npmjs.com/package/mysql2-core) to wrap [mysql2](https://www.npmjs.com/package/mysql2).
- MS SQL: [mssql-core](https://www.npmjs.com/package/mssql-core) to wrap [mssql](https://www.npmjs.com/package/mssql).
- SQLite: [sqlite3-core](https://www.npmjs.com/package/sqlite3-core) to wrap [sqlite3](https://www.npmjs.com/package/sqlite3).
##### Samples
- [oracle-export-sample](https://github.com/typescript-sample/oracle-export-sample): export data from Oracle to fix-length or csv file.
- [postgres-export-sample](https://github.com/typescript-sample/postgres-export-sample): export data from Posgres to fix-length or csv file.
- [mysql-export-sample](https://github.com/typescript-sample/mysql-export-sample): export data from My SQL to f11ix-length or csv file.
- [mssql-export-sample](https://github.com/typescript-sample/mssql-export-sample): export data from MS SQL to fix-length or csv file.
##### Import data for nodejs
###### Key features
- [onecore](https://www.npmjs.com/package/onecore): Standard interfaces for typescript to export data.
- [io-one](https://www.npmjs.com/package/io-one): File Stream Reader, to read CSV or fix-length files from files by stream.
- [xvalidators](https://www.npmjs.com/package/xvalidators): Validate data
- [import-service](https://www.npmjs.com/package/import-service): Implement import flow
###### Libraries to write data to database
- [query-core](https://www.npmjs.com/package/query-core): Simple writer to insert, update, delete, insert batch for Postgres, MySQL, MS SQL
- Oracle: [oracle-core](https://www.npmjs.com/package/oracle-core) to wrap [oracledb](https://www.npmjs.com/package/oracledb), to build insert or update SQL statement, insert batch for Oracle.
- My SQL: [mysql2-core](https://www.npmjs.com/package/mysql2-core) to wrap [mysql2](https://www.npmjs.com/package/mysql2), to build insert or update SQL statement.
- MS SQL: [mssql-core](https://www.npmjs.com/package/mssql-core) to wrap [mssql](https://www.npmjs.com/package/mssql), to build insert or update SQL statement.
- SQLite: [sqlite3-core](https://www.npmjs.com/package/sqlite3-core) to wrap [sqlite3](https://www.npmjs.com/package/sqlite3), to build insert or update SQL statement.
- Mongo: [mongodb-extension](https://www.npmjs.com/package/mongodb-extension) to wrap [mongodb](https://www.npmjs.com/package/mongodb), to insert, update, upsert, insert batch, update batch, upsert batch.
##### Sample
- [import-sample](https://github.com/typescript-sample/import-sample): nodejs sample to import data from fix-length or csv file to sql (Oracle, Postgres, My SQL, MS SQL, SQLite)
## Installation
Please make sure to initialize a Go module before installing core-go/io:
```shell
go get -u github.com/core-go/io
```
Import:
```go
import "github.com/core-go/io"
```