https://github.com/couchbaselabs/couchversion
https://github.com/couchbaselabs/couchversion
couchbase database hacktoberfest java
Last synced: about 1 year ago
JSON representation
- Host: GitHub
- URL: https://github.com/couchbaselabs/couchversion
- Owner: couchbaselabs
- Created: 2020-09-24T14:05:23.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2022-10-26T19:11:47.000Z (over 3 years ago)
- Last Synced: 2025-03-31T00:41:20.198Z (over 1 year ago)
- Topics: couchbase, database, hacktoberfest, java
- Language: Java
- Homepage:
- Size: 85.9 KB
- Stars: 12
- Watchers: 17
- Forks: 6
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
**CouchVersion** is a Java framework which helps you to *manage changes* in your Couchbase and *synchronize* them with your application.
The concept is very similar to other db migration tools such as Liquibase or [Flyway](http://flywaydb.org) but *without using XML/JSON/YML files*.
# Quick Update:
We are testing the support for collections. Expectation is to get a new release by Nov 15th 2022.
CouchVersion provides new approach for adding changes (change sets) based on Java classes and methods with appropriate annotations.
The goal is to keep this tool simple and comfortable to use.
Watch more about it here: https://share.vidyard.com/watch/98GgKFiyi4tz2WuLQVVfzW
# Getting started
You can clone the sample project here https://github.com/deniswsrosa/CouchVersionDemo
# Release Notes
0.5.1 -> Minor bug fixes
## Add a dependency
*IMPORTANT:* https://oss.sonatype.org/content/groups/public/com/github/couchbaselabs/couchversion/
With Maven
```xml
com.github.couchbaselabs
couchversion
0.5.1
```
With Gradle
```groovy
compile 'org.javassist:javassist:3.18.2-GA' // workaround for ${javassist.version} placeholder issue*
compile 'com.github.couchversion:couchversion:0.5'
```
## Usage with Spring
You need to instantiate CouchVersion object and provide some configuration.
If you use Spring can be instantiated as a singleton bean in the Spring context.
In this case the migration process will be executed automatically on startup.
```java
@Autowired
private ApplicationContext context;
@Bean
public CouchVersion couchversion(){
CouchVersion runner = new CouchVersion(context); //It will grab all the data needed from the application.properties file
runner.setChangeLogsScanPackage(
"com.example.yourapp.changelogs"); // the package to be scanned for changesets
return runner;
}
```
For the case above, the following properties will be loaded from your **application.properties** file:
```properties
spring.couchbase.connection=
spring.couchbase.user=
spring.couchbase.password=
spring.couchbase.bucket=
```
With **Spring Data Couchbase 4** you can also reuse your class that extends *AbstractCouchbaseConfiguration* (used to connect with Couchbase) to configure CouchVersion:
```java
import org.springframework.context.annotation.Configuration;
import org.springframework.data.couchbase.config.AbstractCouchbaseConfiguration;
@Configuration
public class CouchbaseConfig extends AbstractCouchbaseConfiguration {
@Override
public String getConnectionString() {
return "couchbase://127.0.0.1";
}
@Override
public String getUserName() {
return "Administrator";
}
@Override
public String getPassword() {
return "password";
}
@Override
public String getBucketName() {
return "default";
}
}
```
and then:
```java
@Autowired
private CouchbaseConfig couchbaseConfig;
@Autowired
private ApplicationContext context;
@Bean
public CouchVersion couchVersions(){
CouchVersion runner = new CouchVersion(couchbaseConfig.getConnectionString(),
couchbaseConfig.getBucketName(), couchbaseConfig.getUserName(), couchbaseConfig.getPassword());
//if you don't set the application context, your migrations can't be autowired
runner.setApplicationContext(context);
runner.setChangeLogsScanPackage(
"com.cb.springdata.sample.migration"); // the package to be scanned for changesets
return runner;
}
```
## Usage without Spring
Using CouchVersion without a spring context has similar configuration but you have to remember to run `execute()` method to start a migration process.
```java
CouchVersion runner = new CouchVersion("couchbase://SOME_IP_ADDRESS", "yourBucketName", "bucketPasword");
runner.setChangeLogsScanPackage(
"com.example.yourapp.changelogs"); // package to scan for changesets
runner.execute(); // ------> starts migration changesets
```
Above examples provide minimal configuration. `CouchVersion` object provides some other possibilities (setters) to make the tool more flexible:
```java
runner.setEnabled(shouldBeEnabled); // default is true, migration won't start if set to false
```
## Creating change logs
`ChangeLog` contains bunch of `ChangeSet`s. `ChangeSet` is a single task (set of instructions made on a database). In other words `ChangeLog` is a class annotated with `@ChangeLog` and containing methods annotated with `@ChangeSet`.
```java
package com.example.yourapp.changelogs;
@ChangeLog
public class DatabaseChangelog {
@ChangeSet(order = "1", id = "someChangeId", author = "testAuthor")
public void importantWorkToDo(){
// task implementation
}
}
```
### @ChangeLog
Class with change sets must be annotated by `@ChangeLog`. There can be more than one change log class but in that case `order` argument should be provided:
```java
@ChangeLog(order = "001")
public class DatabaseChangelog {
//...
}
```
ChangeLogs are sorted *alphabetically* (that is why it is a good practice to start the order with zeros) by `order` argument and changesets are applied due to this order.
### @ChangeSet
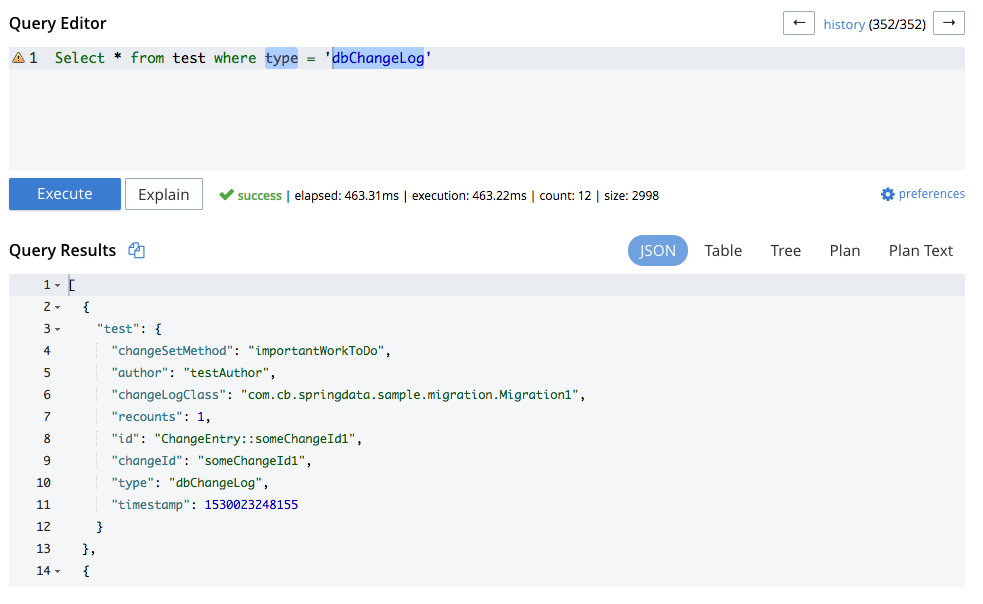
Method annotated by @ChangeSet is taken and applied to the database. History of applied change sets is stored in a document with type `dbChangeLog`:
#### Annotation parameters:
`order` - string for sorting change sets in one changelog. Sorting in alphabetical order, ascending. It can be a number, a date etc.
`id` - name of a change set, **must be unique** for all change logs in a database
`author` - author of a change set
`runAlways` - _[optional, default: false]_ changeset will always be executed but only the first execution event will be stored as a document
`restartInterrupted` - _[optional, default: true]_ changeset will be executed after an interruption, such as an application shutdown, or server a crash.
`retries` - _[optional, default: 0] If by some reason your changeSet throws an exception and you want to retry it instead of failing, you could set here the number of retries you want (Not sure if this feature is useful, let me know if you are using it). If all retries fail, an exception will be thrown an the application will fail to start.

#### Defining ChangeSet methods
Method annotated by `@ChangeSet` can have one of the following definition:
```java
/**
* If you are using Spring, you can Autowire your Services or Repositories
*/
@Component
@ChangeLog(order = "001")
public class Migration1 {
@Autowired // Yes, You can a
private UserService userService;
@Autowired
private UserRepository userRepository;
@ChangeSet(order = "001", id = "someChangeId1", author = "testAuthor")
public void importantWorkToDo(Cluster cluster, Bucket bucket){
System.out.println("----------Migration1 - Method1");
}
@ChangeSet(order = "002", id = "someChangeId2", author = "testAuthor")
public void method2(Bucket bucket, Cluster cluster){
System.out.println("----------Migration1 - Method2");
}
@ChangeSet(order = "003", id = "someChangeId3", author = "testAuthor")
public void method3(Cluster cluster){
System.out.println("----------Migration1 - Method3");
}
@ChangeSet(order = "004", id = "someChangeId4", author = "testAuthor")
public void method4(Bucket bucket){
System.out.println("----------Migration1 - Method4");
}
@ChangeSet(order = "005", id = "someChangeId4", author = "testAuthor")
public void method5(){
System.out.println("----------Migration1 - Method5 (The bucket parameter is not necessary here)");
}
}
```
##### Example
Here is an example of how a real migration could look like:
```java
/**
* This is an example of how to use it without Spring, in this case you can execute all the queries via the Bucket argument.
*/
@ChangeLog(order = "2")
public class Migration2 {
@ChangeSet(order = "001", id = "createDummyData", author = "testAuthor")
public void createDummyData(Bucket bucket){
User user1 = new User(UUID.randomUUID().toString(), "Denis", null, null, null, null);
userRepository.save(user1);
User user2 = new User(UUID.randomUUID().toString(), "John", null, null, null, null);
userRepository.save(user2);
}
@ChangeSet(order = "002", id = "createPrimaryIndex", author = "testAuthor")
public void createInitialIndes(Cluster cluster, Bucket bucket){
cluster.queryIndexes().createPrimaryIndex(bucket.name(),
CreatePrimaryQueryIndexOptions.createPrimaryQueryIndexOptions().ignoreIfExists(true));
}
@ChangeSet(order = "003", id = "someBasicIndes", author = "testAuthor")
public void createSomeBasicIndes(Cluster cluster, Bucket bucket){
cluster.queryIndexes().createIndex(bucket.name(), "nameIndex", Arrays.asList("name"),
CreateQueryIndexOptions.createQueryIndexOptions().ignoreIfExists(true));
}
@ChangeSet(order = "004", id = "userPartialIndex", author = "testAuthor")
public void createPartialIndex(Cluster cluster, Bucket bucket ){
cluster.query("CREATE INDEX user_idx ON `"+bucket.name()+"`(`_class`, `firstName`) WHERE (`_class` = '"+ User.class.getName()+"')");
}
@ChangeSet(order = "005", id = "copyNameToFirstName", author = "testAuthor")
public void copyNameToFirstName(Cluster cluster, Bucket bucket){
cluster.query("update `"+bucket.name()+"` set firstName = name WHERE (`_class` = '"+ User.class.getName()+"')");
}
@ChangeSet(order = "006", id = "deleteUserName", author = "testAuthor")
public void deleteUserName(Cluster cluster, Bucket bucket){
cluster.query(" UPDATE `"+bucket.name()+"` UNSET name WHERE (`_class` = '"+ User.class.getName()+"')");
}
}
```
## Using Spring profiles
**CouchVersion** accepts Spring's `org.springframework.context.annotation.Profile` annotation. If a change log or change set class is annotated with `@Profile`,
then it is activated for current application profiles.
_Example 1_: annotated change set will be invoked for a `dev` profile
```java
@Profile("dev")
@ChangeSet(author = "testuser", id = "myDevChangest", order = "01")
public void devEnvOnly(DB db){
// ...
}
```
_Example 2_: all change sets in a changelog will be invoked for a `test` profile
```java
@ChangeLog(order = "1")
@Profile("test")
public class ChangelogForTestEnv{
@ChangeSet(author = "testuser", id = "myTestChangest", order = "01")
public void testingEnvOnly(DB db){
// ...
}
}
```
### Enabling @Profile annotation (optional)
To enable the `@Profile` integration, please inject `org.springframework.context.ApplicationContext` to you runner.
```java
@Autowired
private ApplicationContext context;
@Bean
public CouchVersion couchversion() {
CouchVersion runner = new CouchVersion(context);
//... etc
}
```
## Locks and Race Conditions
**CouchVersion*** has an internal mechanism to avoid race conditions. Before running the migration, the framework will write a document with id **couchversion_lock** in the database to act as a lock.
Other instances of the application will check this lock before trying to run the migration, and if the lock is present, they will sleep in exponential intervals until it reaches 5 minutes of waiting. After this time, if the lock has not been released yet, the application will fail to start.
Once the migration finishes or fails, the document with id **couchversion_lock** will be removed from the database.
## Support
If you have any questions/requests, just ping me on twitter at [@deniswsrosa](https://twitter.com/deniswsrosa)
## Special Thanks
This project is a fork of MongoBee, so thanks to all guys involved with it.