https://github.com/cploutarchou/web-scraping-with-python
A StackOverflow Web Scaper in python and MongoDB
https://github.com/cploutarchou/web-scraping-with-python
beautifulsoup dashboard docker dockercompose mongodb numpy pandas python scraper scraping
Last synced: about 1 year ago
JSON representation
A StackOverflow Web Scaper in python and MongoDB
- Host: GitHub
- URL: https://github.com/cploutarchou/web-scraping-with-python
- Owner: cploutarchou
- License: gpl-3.0
- Created: 2021-09-02T20:32:48.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2021-10-17T14:56:56.000Z (over 4 years ago)
- Last Synced: 2025-04-06T04:51:10.619Z (over 1 year ago)
- Topics: beautifulsoup, dashboard, docker, dockercompose, mongodb, numpy, pandas, python, scraper, scraping
- Language: CSS
- Homepage:
- Size: 6 MB
- Stars: 2
- Watchers: 1
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# StackOverflow-scraper-using-python
A simple scraper app for StackOverflow using MongoDB.
## How to Run
* For the first time you need to run ./init.sh
* You can stop the infrastructure usinf ./stop.sh
* You can start the infrastructure usinf ./start.sh
## Requirements:
* docker
* docker-compose
## Graylog :
* http://172.21.0.35:9000/
* Usename : admin
* password : admin
To be able to receive application logs to Graylog you need to make the followings
1. Create one GelfTCP input stream
1. Click on System/inputs/gelf
2. Select Gelf TCP from the dropdown
3. Click on Launch new input
4. add a Title for the input
5. Click save
6. Now, you can access the application log by Click on Show Received Messages
## Application UI:
* Url : http://172.21.0.25
## MongoDB
* Url : http://172.21.0.20
* Database name : webscrapper
* Database User : admin
* Database password : admin
## Cron JOB:
if is required to update cron job run you can edit the followings:
* Docker/scripts/entrypoint.sh and update the default expression (*/30 * * * *) bases on your requirements.
* Docker/scripts/scheduler.txt and update the default expression (*/30 * * * *) bases on your requirements.
## Important notes
* The application, by default, fetches the first ten pages from StackOverflow every 30 minutes.
A cron job runs the scraper and updates the application database.
* It is required to fetch more pages. You can update the passed parameters of method execute_job() from 10 to any other value between 10 and 1000. The file is located on app/scraper.py
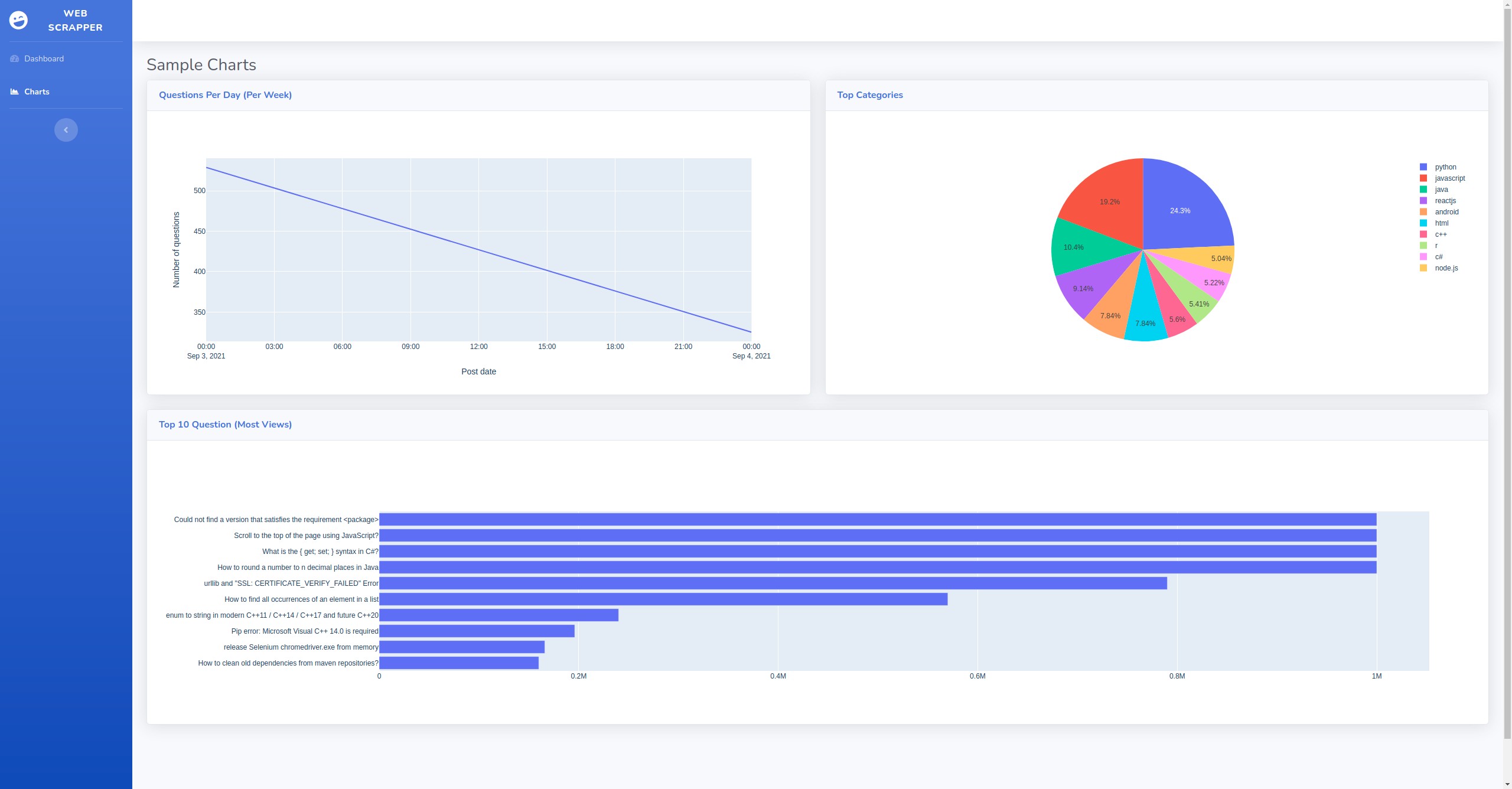
## Screenshots
### Dash
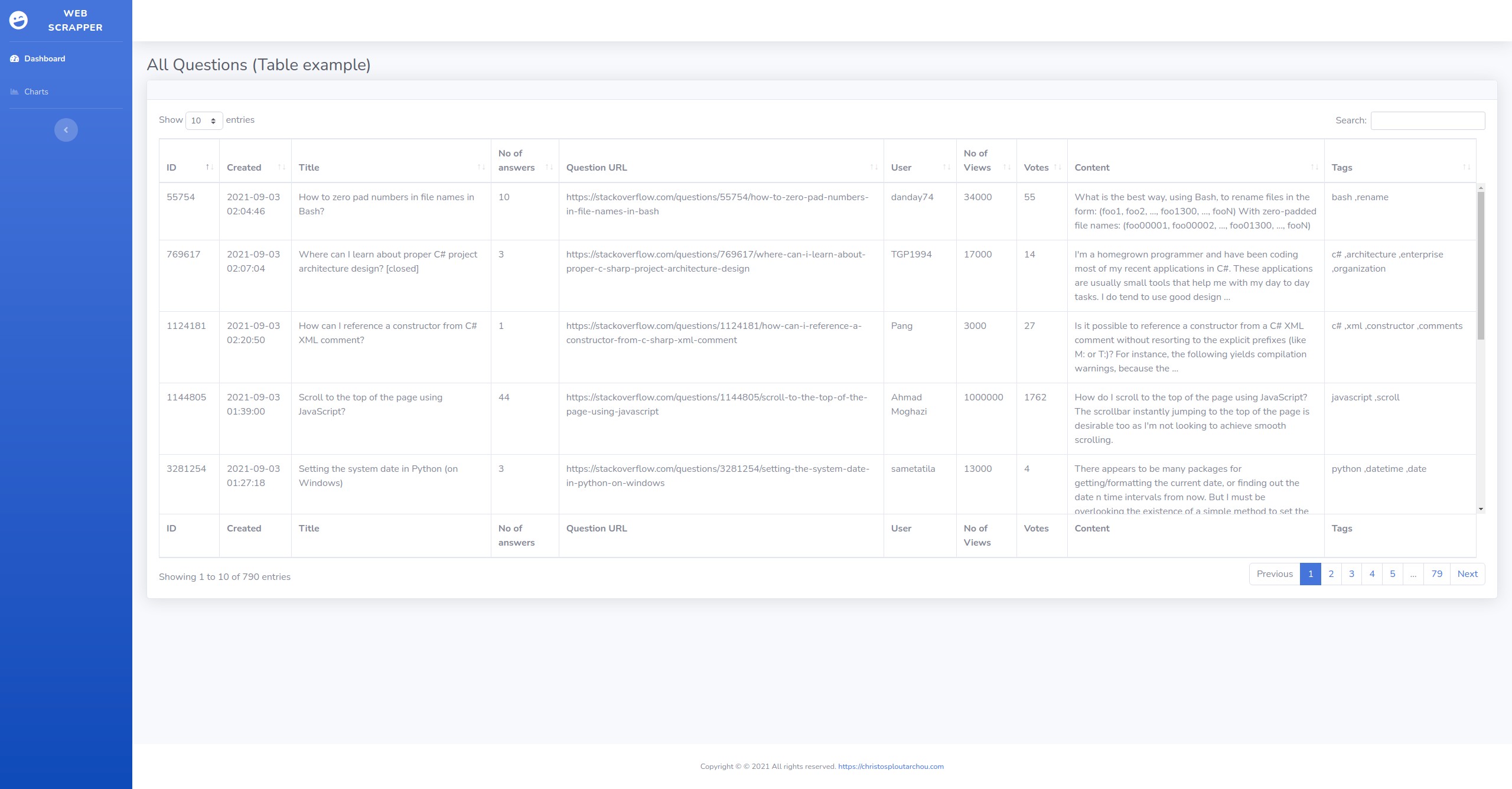
### Charts