https://github.com/crownpku/somiao-pinyin
Somiao Pinyin: Train your own Chinese Input Method with Seq2seq Model 搜喵拼音输入法
https://github.com/crownpku/somiao-pinyin
chinese input-method pinyin seq2seq-model
Last synced: over 1 year ago
JSON representation
Somiao Pinyin: Train your own Chinese Input Method with Seq2seq Model 搜喵拼音输入法
- Host: GitHub
- URL: https://github.com/crownpku/somiao-pinyin
- Owner: crownpku
- Created: 2017-08-29T06:08:38.000Z (almost 9 years ago)
- Default Branch: master
- Last Pushed: 2020-03-29T08:44:00.000Z (over 6 years ago)
- Last Synced: 2025-04-10T03:56:51.927Z (over 1 year ago)
- Topics: chinese, input-method, pinyin, seq2seq-model
- Language: Python
- Homepage:
- Size: 143 KB
- Stars: 266
- Watchers: 15
- Forks: 78
- Open Issues: 10
-
Metadata Files:
- Readme: README.md
- Funding: .github/FUNDING.yml
Awesome Lists containing this project
README
# Somiao Pinyin: Train your own Chinese Input Method with Seq2seq Model
### [中文Blog](http://www.crownpku.com/2017/09/10/%E6%90%9C%E5%96%B5%E8%BE%93%E5%85%A5%E6%B3%95-%E7%94%A8seq2seq%E8%AE%AD%E7%BB%83%E8%87%AA%E5%B7%B1%E7%9A%84%E6%8B%BC%E9%9F%B3%E8%BE%93%E5%85%A5%E6%B3%95.html)
Personalized Chinese Pinyin Input Method with Seq2seq model
Original code in https://github.com/Kyubyong/neural_chinese_transliterator for research purpose.
This repository intends to experiment with different training data and interactive user inputs, and possibly develop towards a real data-personalized and model-localized Pinyin Input product.
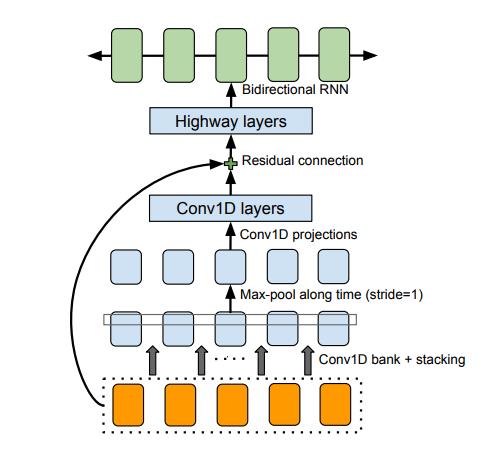
## Requrements
* Python (>=3.5)
* TensorFlow (>=r1.2)
* xpinyin (for Chinese pinyin annotation)
* distance (for calculating the similarity score between two strings)
* tqdm
## Usage
### Training:
* STEP 1. Download [Leipzig Chinese Corpus](http://wortschatz.uni-leipzig.de/en/download/)
Extract it and copy zho_news_2007-2009_1M-sentences.txt to data/ folder.
Or use your own Chinese Corpus with the same format.
* STEP 2. Build a Pinyin-Chinese parallel corpus.
```
#python3 build_corpus.py
```
* STEP 3. Run `prepro.py` to make vocabulary and training data.
```
#python3 prepro.py
```
* STEP 4. Adjust hyperparameters in `hyperparams.py` if necessary.
* STEP 5. Train the model
```
#python3 train.py
```
### Inference with command line input:
For command line input testing, run:
```
python3 eval.py
```
You may change the main function name to use the original testing data evaluation.
### Testing with pre-trained models:
Download the pre-trained model from [blog](http://www.crownpku.com/2017/09/10/%E6%90%9C%E5%96%B5%E8%BE%93%E5%85%A5%E6%B3%95-%E7%94%A8seq2seq%E8%AE%AD%E7%BB%83%E8%87%AA%E5%B7%B1%E7%9A%84%E6%8B%BC%E9%9F%B3%E8%BE%93%E5%85%A5%E6%B3%95.html), unzip it to generate /log and /data.
Remember to overwrite the pickle files in /data with the pre-trained model data.
Then run for command line input testing:
```
python3 eval.py
```
## Sample Results
Model is trained from Chinese News in 2007-2009. So many now common Chinese sayings are not learned.
```
请输入测试拼音:nihao
你好
请输入测试拼音:chenggongle
成功了
请输入测试拼音:wolegequ
我了个曲
请输入测试拼音:taibangla
太棒啦
请输入测试拼音:dacolehuizenmeyang
打破了会怎么样
请输入测试拼音:pujinghehujintaotongdianhua
普京和胡锦涛通电话
请输入测试拼音:xiangbuqilaishinianqianfashengleshenme
想不起来十年前发生了什么
请输入测试拼音:meiguohongzhawomenzainansilafudedashiguan
美国轰炸我们在南斯拉夫的大事馆
请输入测试拼音:liudehuanageshihouhaonianqing
刘德华那个时候好年轻
请输入测试拼音:shishihouxunlianyixiabilibilideyuliaole
是时候训练一下比例比例的预料了
```
## TODOLIST
* Pretrained models on different contexts
* Model selection for using different models while input different things (chatting? writing scientific papers? etc...)
* Function to record LOCALLY what user has input as personalized corpus
* User Interface
* ...