https://github.com/curiousily/ragbase
Completely local RAG. Chat with your PDF documents (with open LLM) and UI to that uses LangChain, Streamlit, Ollama (Llama 3.1), Qdrant and advanced methods like reranking and semantic chunking.
https://github.com/curiousily/ragbase
langchain llama3 llm pdf rag retrieval-augmented-generation streamlit
Last synced: about 1 year ago
JSON representation
Completely local RAG. Chat with your PDF documents (with open LLM) and UI to that uses LangChain, Streamlit, Ollama (Llama 3.1), Qdrant and advanced methods like reranking and semantic chunking.
- Host: GitHub
- URL: https://github.com/curiousily/ragbase
- Owner: curiousily
- License: mit
- Created: 2024-07-11T10:12:30.000Z (almost 2 years ago)
- Default Branch: master
- Last Pushed: 2024-07-26T12:01:41.000Z (almost 2 years ago)
- Last Synced: 2025-04-05T17:15:31.354Z (over 1 year ago)
- Topics: langchain, llama3, llm, pdf, rag, retrieval-augmented-generation, streamlit
- Language: Python
- Homepage: https://www.mlexpert.io/bootcamp/ragbase-local-rag
- Size: 409 KB
- Stars: 91
- Watchers: 2
- Forks: 32
- Open Issues: 9
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# RagBase - Private Chat with Your Documents
> Completely local RAG with chat UI
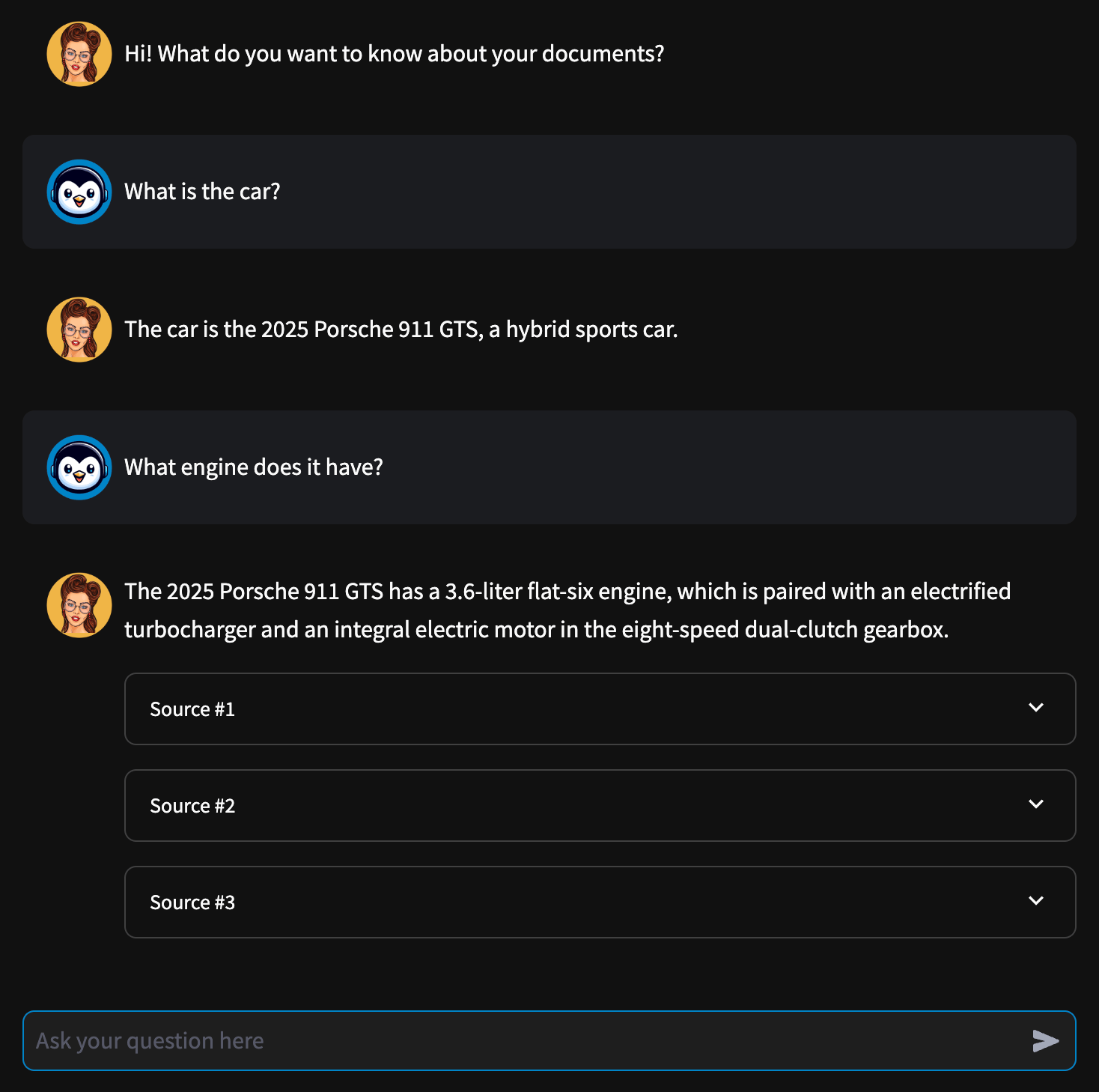
## Demo
Check out the [RagBase on Streamlit Cloud](https://ragbase.streamlit.app/). Runs with Groq API.
## Installation
Clone the repo:
```sh
git clone git@github.com:curiousily/ragbase.git
cd ragbase
```
Install the dependencies (requires Poetry):
```sh
poetry install
```
Fetch your LLM (gemma2:9b by default):
```sh
ollama pull gemma2:9b
```
Run the Ollama server
```sh
ollama serve
```
Start RagBase:
```sh
poetry run streamlit run app.py
```
## Architecture
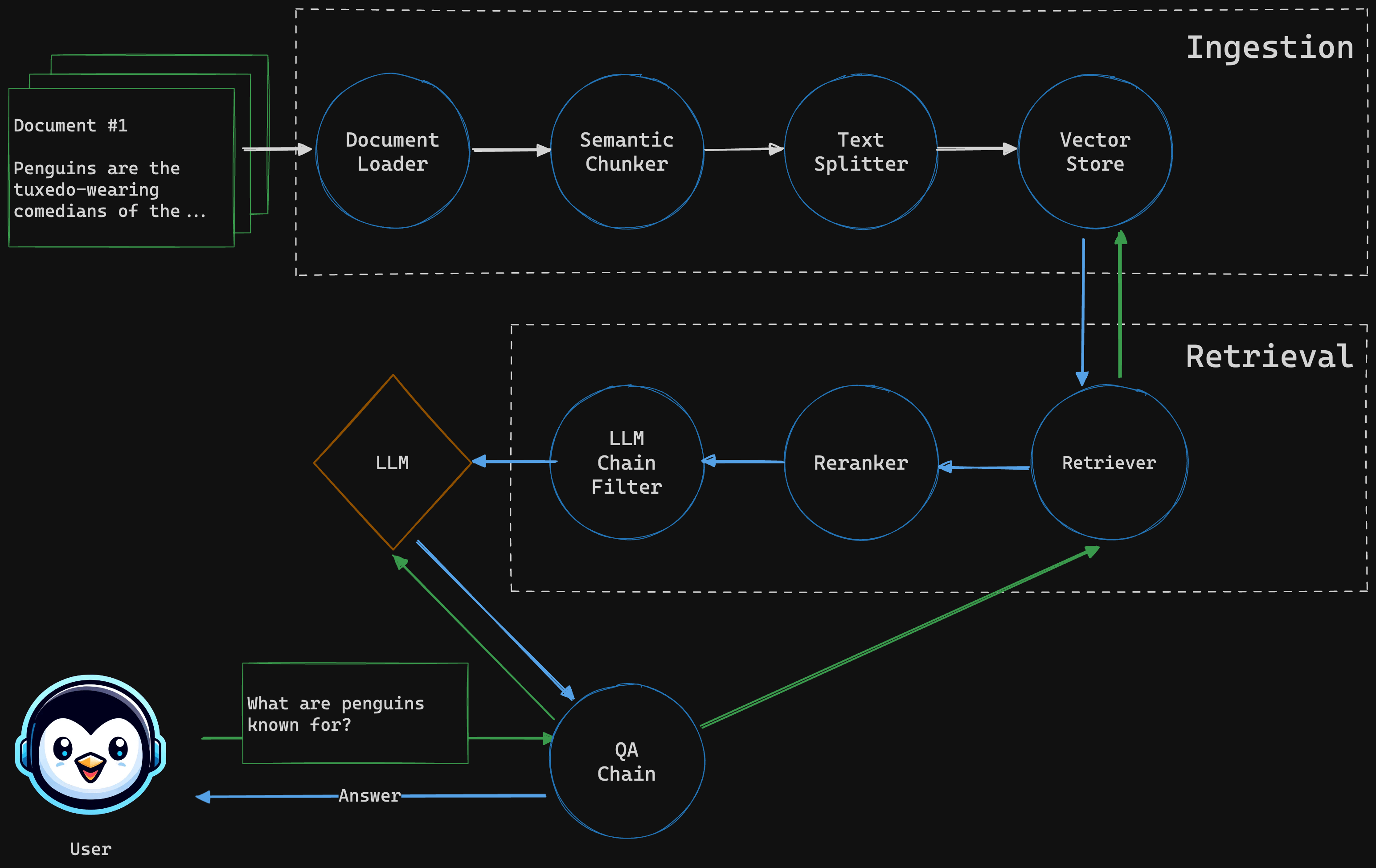
### Ingestor
Extracts text from PDF documents and creates chunks (using semantic and character splitter) that are stored in a vector databse
### Retriever
Given a query, searches for similar documents, reranks the result and applies LLM chain filter before returning the response.
### QA Chain
Combines the LLM with the retriever to answer a given user question
## Tech Stack
- [Ollama](https://ollama.com/) - run local LLM
- [Groq API](https://groq.com/) - fast inference for mutliple LLMs
- [LangChain](https://www.langchain.com/) - build LLM-powered apps
- [Qdrant](https://qdrant.tech/) - vector search/database
- [FlashRank](https://github.com/PrithivirajDamodaran/FlashRank) - fast reranking
- [FastEmbed](https://qdrant.github.io/fastembed/) - lightweight and fast embedding generation
- [Streamlit](https://streamlit.io/) - build UI for data apps
- [PDFium](https://pdfium.googlesource.com/pdfium/) - PDF processing and text extraction
## Add Groq API Key (Optional)
You can also use the Groq API to replace the local LLM, for that you'll need a `.env` file with Groq API key:
```sh
GROQ_API_KEY=YOUR API KEY
```