https://github.com/daeh/computed-appraisals
Computed Appraisals Model. Code and data for the 2023 paper, "Emotion prediction as computation over a generative theory of mind"
https://github.com/daeh/computed-appraisals
affective-computing cognitive-science emotional-intelligence probabilistic-programming psychology
Last synced: about 1 year ago
JSON representation
Computed Appraisals Model. Code and data for the 2023 paper, "Emotion prediction as computation over a generative theory of mind"
- Host: GitHub
- URL: https://github.com/daeh/computed-appraisals
- Owner: daeh
- Created: 2023-02-25T02:19:52.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2023-06-12T20:28:46.000Z (about 3 years ago)
- Last Synced: 2025-03-26T06:22:09.628Z (about 1 year ago)
- Topics: affective-computing, cognitive-science, emotional-intelligence, probabilistic-programming, psychology
- Language: Python
- Homepage:
- Size: 9.52 MB
- Stars: 12
- Watchers: 1
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Emotion prediction as computation over a generative theory of mind
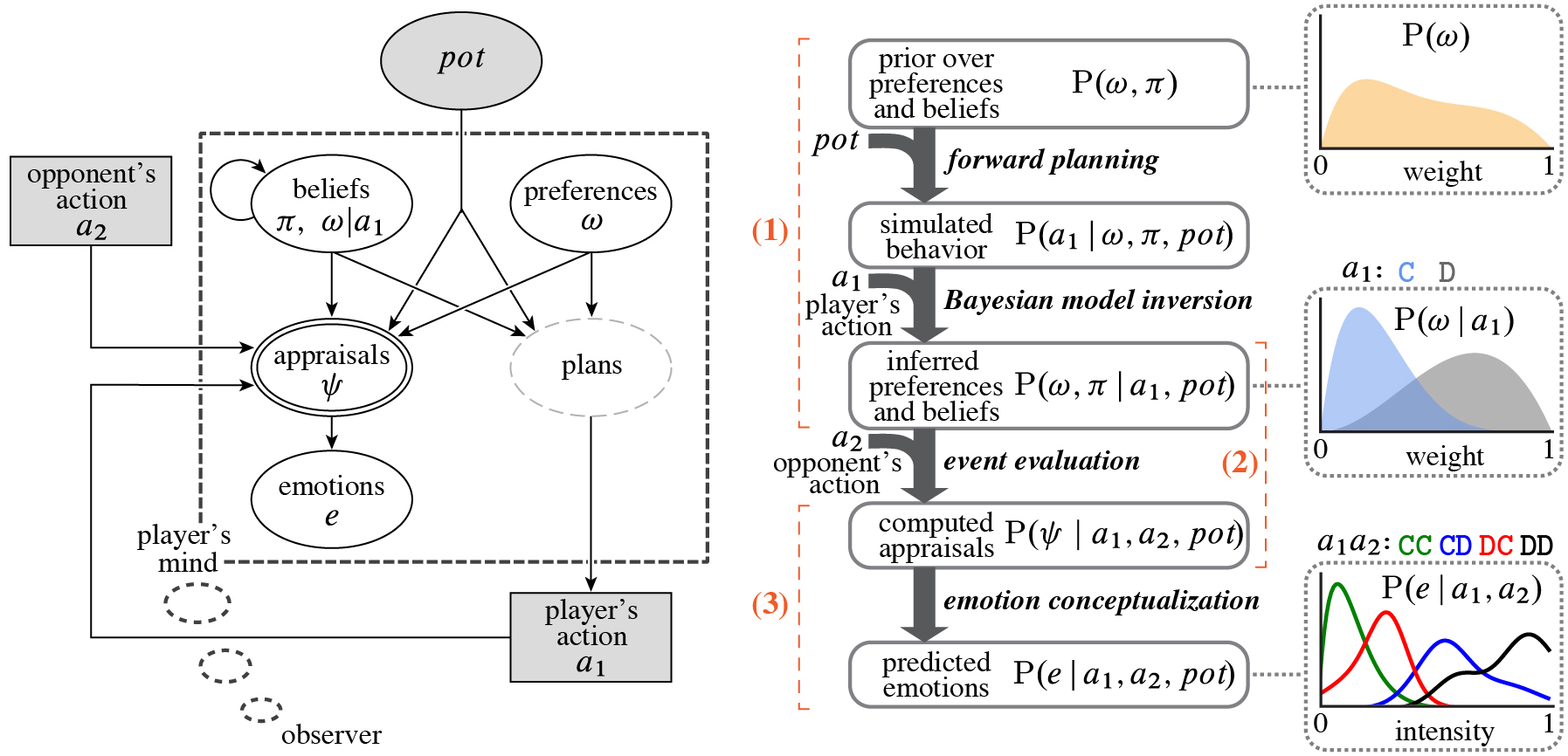
**ABSTRACT** From sparse descriptions of events, observers can make systematic and nuanced predictions of what emotions the people involved will experience. We propose a formal model of emotion prediction in the context of a public high-stakes social dilemma. This model uses inverse planning to infer a person's beliefs and preferences, including social preferences for equity and for maintaining a good reputation. The model then combines these inferred mental contents with the event to compute 'appraisals': whether the situation conformed to the expectations and fulfilled the preferences. We learn functions mapping computed appraisals to emotion labels, allowing the model to match human observers' quantitative predictions of twenty emotions, including joy, relief, guilt, and envy. Model comparison indicates that inferred monetary preferences are not sufficient to explain observers' emotion predictions; inferred social preferences are factored into predictions for nearly every emotion. Human observers and the model both use minimal individualizing information to adjust predictions of how different people will respond to the same event. Thus, our framework integrates inverse planning, event appraisals, and emotion concepts in a single computational model to reverse-engineer people's intuitive theory of emotions.
## Project information
This work is described in the open access **[paper](https://daeh.info/pubs/houlihan2023computedappraisals.pdf)**.
The GitHub repository ([https://github.com/daeh/computed-appraisals](https://github.com/daeh/computed-appraisals)) provides all of the raw behavioral data, models, and analyses.
The OSF repository ([https://osf.io/yhwqn](https://osf.io/yhwqn)) provides the cached model data and the behavioral paradigms used to collect the empirical data.
## Citing this work
If you use this repository, the data it includes, or build on the models/analyses, please cite the paper (NB citation given in Bib***La***Tex):
```bibtex
@article{houlihan2023computedappraisals,
title = {Emotion Prediction as Computation over a Generative Theory of Mind},
author = {Houlihan, Sean Dae and Kleiman-Weiner, Max and Hewitt, Luke B. and Tenenbaum, Joshua B. and Saxe, Rebecca},
date = {2023},
journaltitle = {Philosophical Transactions of the Royal Society A},
shortjournal = {Phil. Trans. R. Soc. A},
volume = {381},
number = {2251},
pages = {20220047},
doi = {10.1098/rsta.2022.0047},
url = {https://royalsocietypublishing.org/doi/abs/10.1098/rsta.2022.0047}
}
```
## Contents of the project
- `code` - models and analyses
- `dataIn` - raw behavioral data collected from human observers (see the [empirical data documentation](https://github.com/daeh/computed-appraisals/tree/main/dataIn))
- `dataOut` - cached model data (only on [OSF](https://osf.io/yhwqn))
- `paradigms` - mTurk experiments used to collect the behavioral data in `dataIn/` (only on [OSF](https://osf.io/yhwqn))
## Running the Computed Appraisal Model
To run the computed appraisals model (_cam_), you can install the dependencies necessary to regenerate the results and figures using a **(1)** [Docker container](#1-docker-container) **(2)** [conda environment](#2-conda-environment) or **(3)** [pip specification](#3-pip-specification).
NB Running this model from scratch is prohibitively compute-heavy outside of a High Performance Computing cluster. The model has been cached at various checkpoints to make it easy to explore the results on a personal computer. To make use of the cached model, download and uncompress [dataOut-cached.zip](https://osf.io/37dfr/). Then place the `dataOut` directory containing the cached `*.pkl` files in the local project folder that you clone/fork from this repository (e.g. `computed-appraisals/dataOut/`) .
### 1. `Docker` container
Requires [Docker](https://www.docker.com/). The image includes [WebPPL](https://github.com/probmods/webppl) and [TeX Live](https://www.tug.org/texlive/).
NB Docker is finicky about the cpu architecture. The example below builds an image optimized for `arm64` processors. For an example of building an image for `amd64` processors, see `.devcontainer/Dockerfile`.
```bash
### Clone git repo to the current working directory
git clone --branch main https://github.com/daeh/computed-appraisals.git computed-appraisals
### Enter the new directory
cd computed-appraisals
### (optional but recommended)
### Add the "dataOut" directory that you downloaded from OSF in order to use the cached model
### Build Docker Image
docker build --tag camimage .
### Run Container (optional to specify resources like memory and cpus)
docker run --rm --name=cam \
--memory 12GB --cpus 4 --platform=linux/arm64 \
--volume $(pwd)/:/projhost/ \
camimage /projhost/code/cam_main.py --projectdir /projhost/
```
The container tag is arbitrary (you can replace `camimage` with a different label).
### 2. `conda` environment
Requires [conda](https://docs.conda.io/en/latest/), [conda-lock](https://github.com/conda-incubator/conda-lock), and a local installation of [TeX Live](https://www.tug.org/texlive/). If you want to run the inverse planning models, you need to have the [WebPPL](https://github.com/probmods/webppl) executable in your `PATH` with the [webppl-json](https://github.com/stuhlmueller/webppl-json) add-on.
The example below uses the `conda-lock.yml` file to create an environment where the package versions are pinned to this project's specifications, which is recommend for reproducibility. If the lock file cannot resolve the dependencies for your system, you can use the `environment.yml` file to create an environment with the latest package versions. Simply replace the `conda-lock install ...` line with `conda env create -f environment.yml`.
```bash
### Clone git repo to the current working directory
git clone --branch main https://github.com/daeh/computed-appraisals.git computed-appraisals
### Enter the new directory
cd computed-appraisals
### (optional but recommended)
### Add the "dataOut" directory that you downloaded from OSF in order to use the cached model
### Create the conda environment
conda-lock install --name envcam conda-lock.yml
### Activate the conda environment
conda activate envcam
### Run the python code
python ./code/cam_main.py --projectdir $(pwd)
```
The conda environment name is arbitrary (you can replace `envcam` with a different label).
### 3. `pip` specification
If you use a strategy other than [conda](https://docs.conda.io/en/latest/) or [Docker](https://www.docker.com/) to manage python environments, you can install the dependencies using the `requirements.txt` file located in the root directory of the project. You need to have [TeX Live](https://www.tug.org/texlive/) installed locally. If you want to run the inverse planning models, you need to have the [WebPPL](https://github.com/probmods/webppl) executable in your `PATH` with the [webppl-json](https://github.com/stuhlmueller/webppl-json) add-on.
### Note on PyTorch
Different hardware architectures lead to very small differences in floating point operations. In our experience, setting a random seed causes `PyTorch` to initialize at the same values, but update steps of the Adam optimizer exhibit minuscule differences depending on the platform (e.g. `Intel Xeon E5` vs `Intel Xeon Gold` cores). As such, rerunning the `PyTorch` models may yield results that show small numerical differences from the cached data.
## Authors
- [Sean Dae Houlihan](https://daeh.info)
- [Max Kleiman-Weiner](https://www.mit.edu/~maxkw/)
- [Luke Hewitt](https://lukehewitt.mit.edu/)
- [Josh Tenenbaum](https://web.mit.edu/cocosci/josh.html)
- [Rebecca Saxe](https://saxelab.mit.edu/)