https://github.com/datamllab/rlcard
Reinforcement Learning / AI Bots in Card (Poker) Games - Blackjack, Leduc, Texas, DouDizhu, Mahjong, UNO.
https://github.com/datamllab/rlcard
ai blackjack card-game card-games deep-reinforcement-learning doudizhu game game-ai game-bot gym-environment mahjong multi-agent openai-gym poker poker-game reinforcement-learning texas uno
Last synced: about 1 year ago
JSON representation
Reinforcement Learning / AI Bots in Card (Poker) Games - Blackjack, Leduc, Texas, DouDizhu, Mahjong, UNO.
- Host: GitHub
- URL: https://github.com/datamllab/rlcard
- Owner: datamllab
- License: mit
- Created: 2019-09-05T12:48:01.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2024-06-26T23:01:52.000Z (about 2 years ago)
- Last Synced: 2025-05-04T23:02:51.546Z (about 1 year ago)
- Topics: ai, blackjack, card-game, card-games, deep-reinforcement-learning, doudizhu, game, game-ai, game-bot, gym-environment, mahjong, multi-agent, openai-gym, poker, poker-game, reinforcement-learning, texas, uno
- Language: Python
- Homepage: http://www.rlcard.org
- Size: 8.22 MB
- Stars: 3,104
- Watchers: 77
- Forks: 670
- Open Issues: 73
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE.md
Awesome Lists containing this project
- StarryDivineSky - datamllab/rlcard - 大酒杯,勒杜克,德克萨斯州,窦滴竹,麻将,UNO。 (时间序列 / 网络服务_其他)
README
# RLCard: A Toolkit for Reinforcement Learning in Card Games

[](https://github.com/datamllab/rlcard/actions/workflows/python-package.yml)
[](https://badge.fury.io/py/rlcard)
[](https://coveralls.io/github/datamllab/rlcard?branch=master)
[](https://pepy.tech/project/rlcard)
[](https://pepy.tech/project/rlcard)
[](https://opensource.org/licenses/MIT)
[中文文档](README.zh-CN.md)
RLCard is a toolkit for Reinforcement Learning (RL) in card games. It supports multiple card environments with easy-to-use interfaces for implementing various reinforcement learning and searching algorithms. The goal of RLCard is to bridge reinforcement learning and imperfect information games. RLCard is developed by [DATA Lab](http://faculty.cs.tamu.edu/xiahu/) at Rice and Texas A&M University, and community contributors.
* Official Website: [https://www.rlcard.org](https://www.rlcard.org)
* Tutorial in Jupyter Notebook: [https://github.com/datamllab/rlcard-tutorial](https://github.com/datamllab/rlcard-tutorial)
* Paper: [https://arxiv.org/abs/1910.04376](https://arxiv.org/abs/1910.04376)
* Video: [YouTube](https://youtu.be/krK2jmSdKZc)
* GUI: [RLCard-Showdown](https://github.com/datamllab/rlcard-showdown)
* Dou Dizhu Demo: [Demo](https://douzero.org/)
* Resources: [Awesome-Game-AI](https://github.com/datamllab/awesome-game-ai)
* Related Project: [DouZero Project](https://github.com/kwai/DouZero)
* Zhihu: https://zhuanlan.zhihu.com/p/526723604
* Miscellaneous Resources:
* Check out our open-sourced [Large Time Series Model (LTSM)](https://github.com/daochenzha/ltsm)!
* Have you heard of data-centric AI? Please check out our [data-centric AI survey](https://arxiv.org/abs/2303.10158) and [awesome data-centric AI resources](https://github.com/daochenzha/data-centric-AI)!
**Community:**
* **Slack**: Discuss in our [#rlcard-project](https://join.slack.com/t/rlcard/shared_invite/zt-rkvktsaq-xkMwz8BfKupCM6zGhO01xg) slack channel.
* **QQ Group**: Join our QQ group to discuss. Password: rlcardqqgroup
* Group 1: 665647450
* Group 2: 117349516
**News:**
* We have updated the tutorials in Jupyter Notebook to help you walk through RLCard! Please check [RLCard Tutorial](https://github.com/datamllab/rlcard-tutorial).
* All the algorithms can suppport [PettingZoo](https://github.com/PettingZoo-Team/PettingZoo) now. Please check [here](examples/pettingzoo). Thanks the contribtuion from [Yifei Cheng](https://github.com/ycheng517).
* Please follow [DouZero](https://github.com/kwai/DouZero), a strong Dou Dizhu AI and the [ICML 2021 paper](https://arxiv.org/abs/2106.06135). An online demo is available [here](https://douzero.org/). The algorithm is also integrated in RLCard. See [Training DMC on Dou Dizhu](docs/toy-examples.md#training-dmc-on-dou-dizhu).
* Our package is used in [PettingZoo](https://github.com/PettingZoo-Team/PettingZoo). Please check it out!
* We have released RLCard-Showdown, GUI demo for RLCard. Please check out [here](https://github.com/datamllab/rlcard-showdown)!
* Jupyter Notebook tutorial available! We add some examples in R to call Python interfaces of RLCard with reticulate. See [here](docs/toy-examples-r.md)
* Thanks for the contribution of [@Clarit7](https://github.com/Clarit7) for supporting different number of players in Blackjack. We call for contributions for gradually making the games more configurable. See [here](CONTRIBUTING.md#making-configurable-environments) for more details.
* Thanks for the contribution of [@Clarit7](https://github.com/Clarit7) for the Blackjack and Limit Hold'em human interface.
* Now RLCard supports environment local seeding and multiprocessing. Thanks for the testing scripts provided by [@weepingwillowben](https://github.com/weepingwillowben).
* Human interface of NoLimit Holdem available. The action space of NoLimit Holdem has been abstracted. Thanks for the contribution of [@AdrianP-](https://github.com/AdrianP-).
* New game Gin Rummy and human GUI available. Thanks for the contribution of [@billh0420](https://github.com/billh0420).
* PyTorch implementation available. Thanks for the contribution of [@mjudell](https://github.com/mjudell).
## Contributors
The following games are mainly developed and maintained by community contributors. Thank you!
* Gin Rummy: [@billh0420](https://github.com/billh0420)
* Bridge: [@billh0420](https://github.com/billh0420)
Thank all the contributors!




























## Cite this work
If you find this repo useful, you may cite:
Zha, Daochen, et al. "RLCard: A Platform for Reinforcement Learning in Card Games." IJCAI. 2020.
```bibtex
@inproceedings{zha2020rlcard,
title={RLCard: A Platform for Reinforcement Learning in Card Games},
author={Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia},
booktitle={IJCAI},
year={2020}
}
```
## Installation
Make sure that you have **Python 3.6+** and **pip** installed. We recommend installing the stable version of `rlcard` with `pip`:
```
pip3 install rlcard
```
The default installation will only include the card environments. To use PyTorch implementation of the training algorithms, run
```
pip3 install rlcard[torch]
```
If you are in China and the above command is too slow, you can use the mirror provided by Tsinghua University:
```
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
```
Alternatively, you can clone the latest version with (if you are in China and Github is slow, you can use the mirror in [Gitee](https://gitee.com/daochenzha/rlcard)):
```
git clone https://github.com/datamllab/rlcard.git
```
or only clone one branch to make it faster:
```
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
```
Then install with
```
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
```
We also provide [**conda** installation method](https://anaconda.org/toubun/rlcard):
```
conda install -c toubun rlcard
```
Conda installation only provides the card environments, you need to manually install Pytorch on your demands.
## Examples
A **short example** is as below.
```python
import rlcard
from rlcard.agents import RandomAgent
env = rlcard.make('blackjack')
env.set_agents([RandomAgent(num_actions=env.num_actions)])
print(env.num_actions) # 2
print(env.num_players) # 1
print(env.state_shape) # [[2]]
print(env.action_shape) # [None]
trajectories, payoffs = env.run()
```
RLCard can be flexibly connected to various algorithms. See the following examples:
* [Playing with random agents](docs/toy-examples.md#playing-with-random-agents)
* [Deep-Q learning on Blackjack](docs/toy-examples.md#deep-q-learning-on-blackjack)
* [Training CFR (chance sampling) on Leduc Hold'em](docs/toy-examples.md#training-cfr-on-leduc-holdem)
* [Having fun with pretrained Leduc model](docs/toy-examples.md#having-fun-with-pretrained-leduc-model)
* [Training DMC on Dou Dizhu](docs/toy-examples.md#training-dmc-on-dou-dizhu)
* [Evaluating Agents](docs/toy-examples.md#evaluating-agents)
* [Training Agents on PettingZoo](examples/pettingzoo)
## Demo
Run `examples/human/leduc_holdem_human.py` to play with the pre-trained Leduc Hold'em model. Leduc Hold'em is a simplified version of Texas Hold'em. Rules can be found [here](docs/games.md#leduc-holdem).
```
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
```
We also provide a GUI for easy debugging. Please check [here](https://github.com/datamllab/rlcard-showdown/). Some demos:
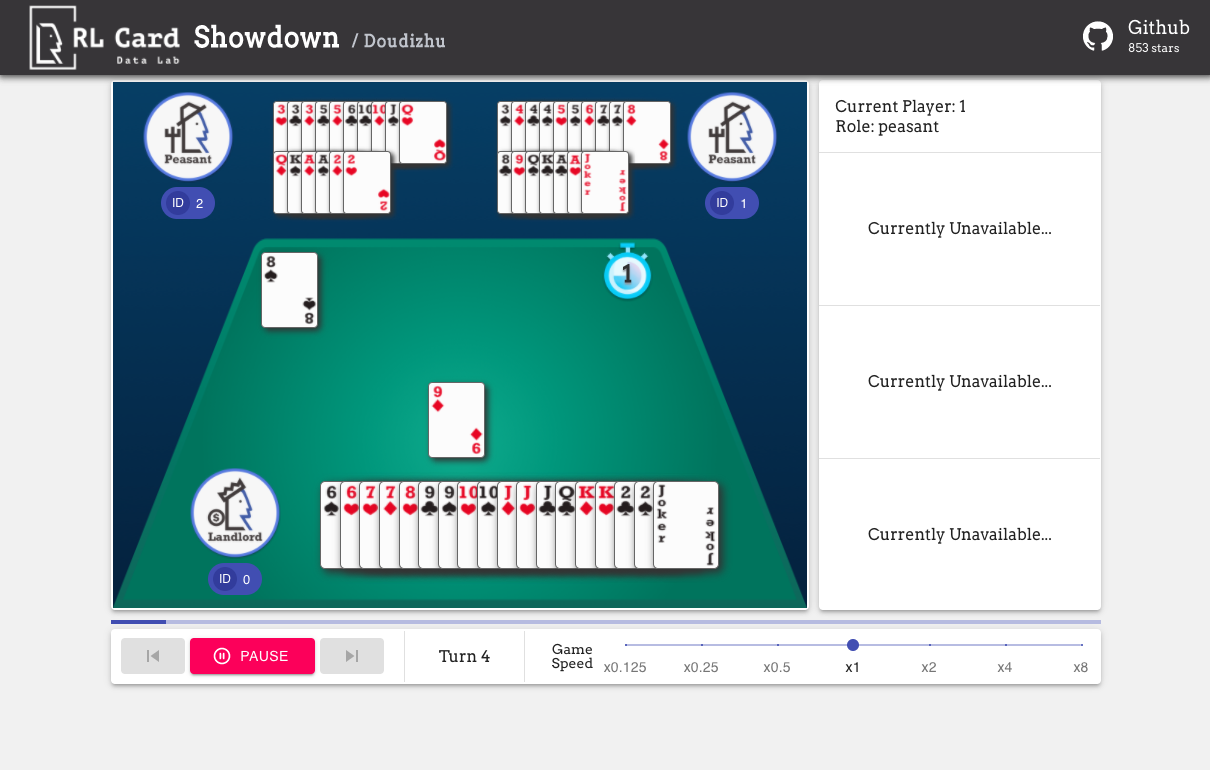
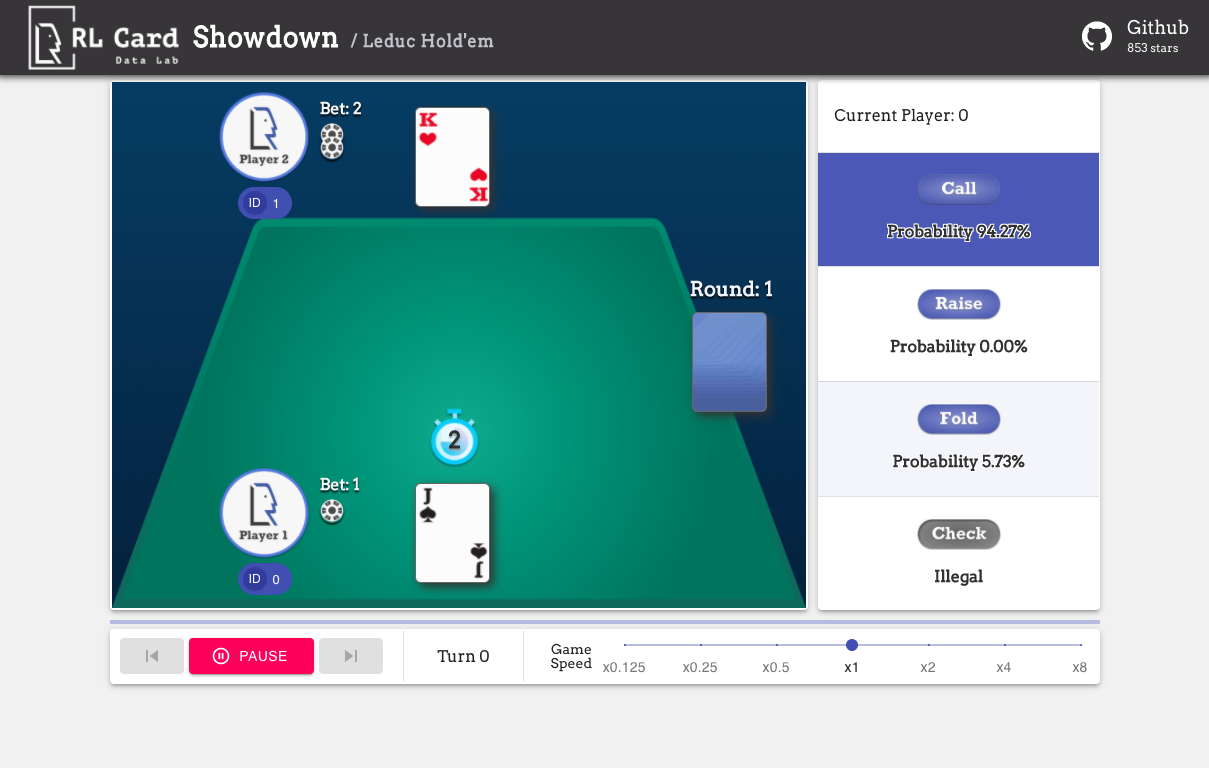
## Available Environments
We provide a complexity estimation for the games on several aspects. **InfoSet Number:** the number of information sets; **InfoSet Size:** the average number of states in a single information set; **Action Size:** the size of the action space. **Name:** the name that should be passed to `rlcard.make` to create the game environment. We also provide the link to the documentation and the random example.
| Game | InfoSet Number | InfoSet Size | Action Size | Name | Usage |
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------: | :---------------: | :---------: | :-------------: | :-----------------------------------------------------------------------------------------: |
| Blackjack ([wiki](https://en.wikipedia.org/wiki/Blackjack), [baike](https://baike.baidu.com/item/21%E7%82%B9/5481683?fr=aladdin)) | 10^3 | 10^1 | 10^0 | blackjack | [doc](docs/games.md#blackjack), [example](examples/run_random.py) |
| Leduc Hold’em ([paper](http://poker.cs.ualberta.ca/publications/UAI05.pdf)) | 10^2 | 10^2 | 10^0 | leduc-holdem | [doc](docs/games.md#leduc-holdem), [example](examples/run_random.py) |
| Limit Texas Hold'em ([wiki](https://en.wikipedia.org/wiki/Texas_hold_%27em), [baike](https://baike.baidu.com/item/%E5%BE%B7%E5%85%8B%E8%90%A8%E6%96%AF%E6%89%91%E5%85%8B/83440?fr=aladdin)) | 10^14 | 10^3 | 10^0 | limit-holdem | [doc](docs/games.md#limit-texas-holdem), [example](examples/run_random.py) |
| Dou Dizhu ([wiki](https://en.wikipedia.org/wiki/Dou_dizhu), [baike](https://baike.baidu.com/item/%E6%96%97%E5%9C%B0%E4%B8%BB/177997?fr=aladdin)) | 10^53 ~ 10^83 | 10^23 | 10^4 | doudizhu | [doc](docs/games.md#dou-dizhu), [example](examples/run_random.py) |
| Mahjong ([wiki](https://en.wikipedia.org/wiki/Competition_Mahjong_scoring_rules), [baike](https://baike.baidu.com/item/%E9%BA%BB%E5%B0%86/215)) | 10^121 | 10^48 | 10^2 | mahjong | [doc](docs/games.md#mahjong), [example](examples/run_random.py) |
| No-limit Texas Hold'em ([wiki](https://en.wikipedia.org/wiki/Texas_hold_%27em), [baike](https://baike.baidu.com/item/%E5%BE%B7%E5%85%8B%E8%90%A8%E6%96%AF%E6%89%91%E5%85%8B/83440?fr=aladdin)) | 10^162 | 10^3 | 10^4 | no-limit-holdem | [doc](docs/games.md#no-limit-texas-holdem), [example](examples/run_random.py) |
| UNO ([wiki](https://en.wikipedia.org/wiki/Uno_\(card_game\)), [baike](https://baike.baidu.com/item/UNO%E7%89%8C/2249587)) | 10^163 | 10^10 | 10^1 | uno | [doc](docs/games.md#uno), [example](examples/run_random.py) |
| Gin Rummy ([wiki](https://en.wikipedia.org/wiki/Gin_rummy), [baike](https://baike.baidu.com/item/%E9%87%91%E6%8B%89%E7%B1%B3/3471710)) | 10^52 | - | - | gin-rummy | [doc](docs/games.md#gin-rummy), [example](examples/run_random.py) |
| Bridge ([wiki](https://en.wikipedia.org/wiki/Bridge), [baike](https://baike.baidu.com/item/%E6%A1%A5%E7%89%8C/332030)) | | - | - | bridge | [doc](docs/games.md#bridge), [example](examples/run_random.py) |
## Supported Algorithms
| Algorithm | example | reference |
| :--------------------------------------: | :-----------------------------------------: | :------------------------------------------------------------------------------------------------------: |
| Deep Monte-Carlo (DMC) | [examples/run\_dmc.py](examples/run_dmc.py) | [[paper]](https://arxiv.org/abs/2106.06135) |
| Deep Q-Learning (DQN) | [examples/run\_rl.py](examples/run_rl.py) | [[paper]](https://arxiv.org/abs/1312.5602) |
| Neural Fictitious Self-Play (NFSP) | [examples/run\_rl.py](examples/run_rl.py) | [[paper]](https://arxiv.org/abs/1603.01121) |
| Counterfactual Regret Minimization (CFR) | [examples/run\_cfr.py](examples/run_cfr.py) | [[paper]](http://papers.nips.cc/paper/3306-regret-minimization-in-games-with-incomplete-information.pdf) |
## Pre-trained and Rule-based Models
We provide a [model zoo](rlcard/models) to serve as the baselines.
| Model | Explanation |
| :--------------------------------------: | :------------------------------------------------------: |
| leduc-holdem-cfr | Pre-trained CFR (chance sampling) model on Leduc Hold'em |
| leduc-holdem-rule-v1 | Rule-based model for Leduc Hold'em, v1 |
| leduc-holdem-rule-v2 | Rule-based model for Leduc Hold'em, v2 |
| uno-rule-v1 | Rule-based model for UNO, v1 |
| limit-holdem-rule-v1 | Rule-based model for Limit Texas Hold'em, v1 |
| doudizhu-rule-v1 | Rule-based model for Dou Dizhu, v1 |
| gin-rummy-novice-rule | Gin Rummy novice rule model |
## API Cheat Sheet
### How to create an environment
You can use the the following interface to make an environment. You may optionally specify some configurations with a dictionary.
* **env = rlcard.make(env_id, config={})**: Make an environment. `env_id` is a string of a environment; `config` is a dictionary that specifies some environment configurations, which are as follows.
* `seed`: Default `None`. Set a environment local random seed for reproducing the results.
* `allow_step_back`: Default `False`. `True` if allowing `step_back` function to traverse backward in the tree.
* Game specific configurations: These fields start with `game_`. Currently, we only support `game_num_players` in Blackjack, .
Once the environemnt is made, we can access some information of the game.
* **env.num_actions**: The number of actions.
* **env.num_players**: The number of players.
* **env.state_shape**: The shape of the state space of the observations.
* **env.action_shape**: The shape of the action features (Dou Dizhu's action can encoded as features)
### What is state in RLCard
State is a Python dictionary. It consists of observation `state['obs']`, legal actions `state['legal_actions']`, raw observation `state['raw_obs']` and raw legal actions `state['raw_legal_actions']`.
### Basic interfaces
The following interfaces provide a basic usage. It is easy to use but it has assumtions on the agent. The agent must follow [agent template](docs/developping-algorithms.md).
* **env.set_agents(agents)**: `agents` is a list of `Agent` object. The length of the list should be equal to the number of the players in the game.
* **env.run(is_training=False)**: Run a complete game and return trajectories and payoffs. The function can be used after the `set_agents` is called. If `is_training` is `True`, it will use `step` function in the agent to play the game. If `is_training` is `False`, `eval_step` will be called instead.
### Advanced interfaces
For advanced usage, the following interfaces allow flexible operations on the game tree. These interfaces do not make any assumtions on the agent.
* **env.reset()**: Initialize a game. Return the state and the first player ID.
* **env.step(action, raw_action=False)**: Take one step in the environment. `action` can be raw action or integer; `raw_action` should be `True` if the action is raw action (string).
* **env.step_back()**: Available only when `allow_step_back` is `True`. Take one step backward. This can be used for algorithms that operate on the game tree, such as CFR (chance sampling).
* **env.is_over()**: Return `True` if the current game is over. Otherewise, return `False`.
* **env.get_player_id()**: Return the Player ID of the current player.
* **env.get_state(player_id)**: Return the state that corresponds to `player_id`.
* **env.get_payoffs()**: In the end of the game, return a list of payoffs for all the players.
* **env.get_perfect_information()**: (Currently only support some of the games) Obtain the perfect information at the current state.
## Library Structure
The purposes of the main modules are listed as below:
* [/examples](examples): Examples of using RLCard.
* [/docs](docs): Documentation of RLCard.
* [/tests](tests): Testing scripts for RLCard.
* [/rlcard/agents](rlcard/agents): Reinforcement learning algorithms and human agents.
* [/rlcard/envs](rlcard/envs): Environment wrappers (state representation, action encoding etc.)
* [/rlcard/games](rlcard/games): Various game engines.
* [/rlcard/models](rlcard/models): Model zoo including pre-trained models and rule models.
## More Documents
For more documentation, please refer to the [Documents](docs/README.md) for general introductions. API documents are available at our [website](http://www.rlcard.org).
## Contributing
Contribution to this project is greatly appreciated! Please create an issue for feedbacks/bugs. If you want to contribute codes, please refer to [Contributing Guide](./CONTRIBUTING.md). If you have any questions, please contact [Daochen Zha](https://github.com/daochenzha) with [daochen.zha@rice.edu](mailto:daochen.zha@rice.edu).
## Acknowledgements
We would like to thank JJ World Network Technology Co.,LTD for the generous support and all the contributions from the community contributors.