https://github.com/davidhintelmann/natural-language-processing
Natural Language Processing Using python's Scapy Library
https://github.com/davidhintelmann/natural-language-processing
Last synced: about 1 year ago
JSON representation
Natural Language Processing Using python's Scapy Library
- Host: GitHub
- URL: https://github.com/davidhintelmann/natural-language-processing
- Owner: davidhintelmann
- Created: 2020-10-08T08:14:15.000Z (over 5 years ago)
- Default Branch: main
- Last Pushed: 2020-10-11T03:42:00.000Z (over 5 years ago)
- Last Synced: 2025-02-03T20:03:21.073Z (over 1 year ago)
- Language: Jupyter Notebook
- Size: 6.76 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Natural Language Processing With Scapy Library for Python
This notebook starts by using [PRAW](https://praw.readthedocs.io/en/latest/#), "The Python Reddit API Wrapper" which will be used to download comments from the subreddit [r/news/](https://www.reddit.com/r/news/).
PRAW can be used to create chat bots on reddit or just to scrap data from it to gain insights into online social media. I will use to [Scapy](https://scapy.readthedocs.io/en/latest/introduction.html) to then perform natural language processing since this python library already have pretain models for this task.
We will try to create an algorithm to detect online harassment, and in particular to flag if a comment has a high likelihood of containing hate speech.
# Import Libraries
```python
import spacy
import praw
import pandas as pd
import json
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
from sklearn.metrics import plot_confusion_matrix
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
```
# Reddit PRAW
Go to this [page](https://www.reddit.com/prefs/apps) to create an app on Reddit's API page.
Rules for Reddits API can be found [here](https://github.com/reddit-archive/reddit/wiki/API).
Instructions for creating Reddit app below have been taken from [Felippe Rodrigues's](https://www.storybench.org/how-to-scrape-reddit-with-python/) post from [storybench.org](https://www.storybench.org/)
This form should open up:
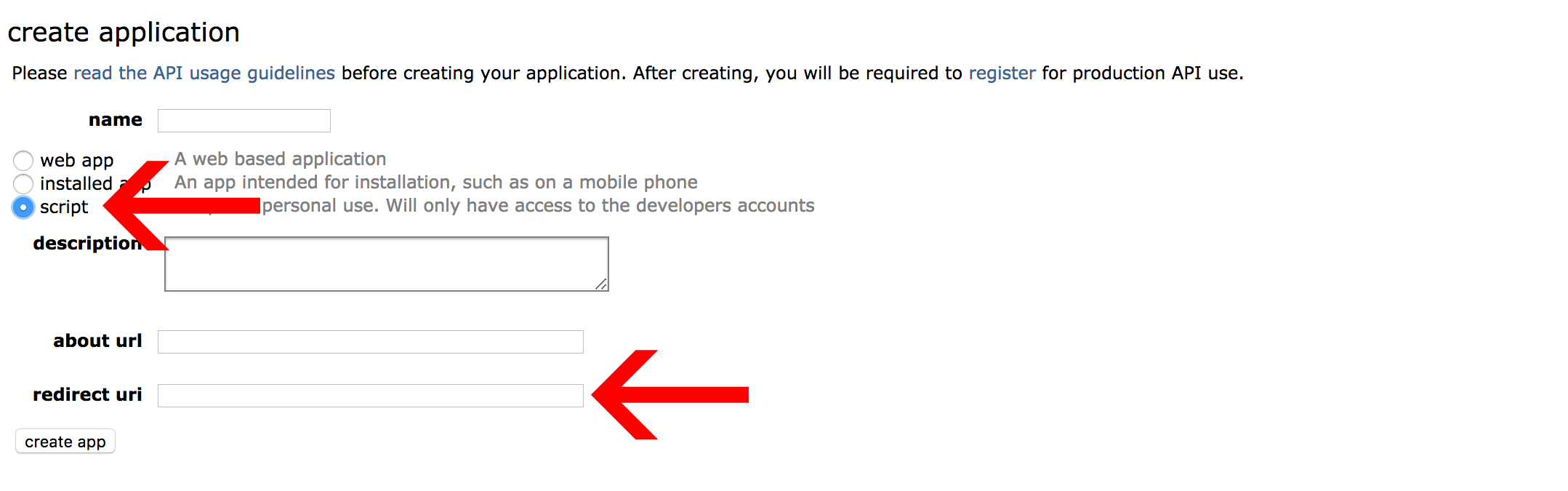
Pick a name for your application and add a description for reference. Also make sure you select the “script” option and don’t forget to put http://localhost:8080 in the redirect uri field. If you have any doubts, refer to [Praw documentation](https://praw.readthedocs.io/en/latest/getting_started/authentication.html#script-application).
Hit create app and now you are ready to use the OAuth2 authorization to connect to the API and start scraping. Copy and paste your 14-characters personal use script and 27-character secret key somewhere safe. You application should look like this:
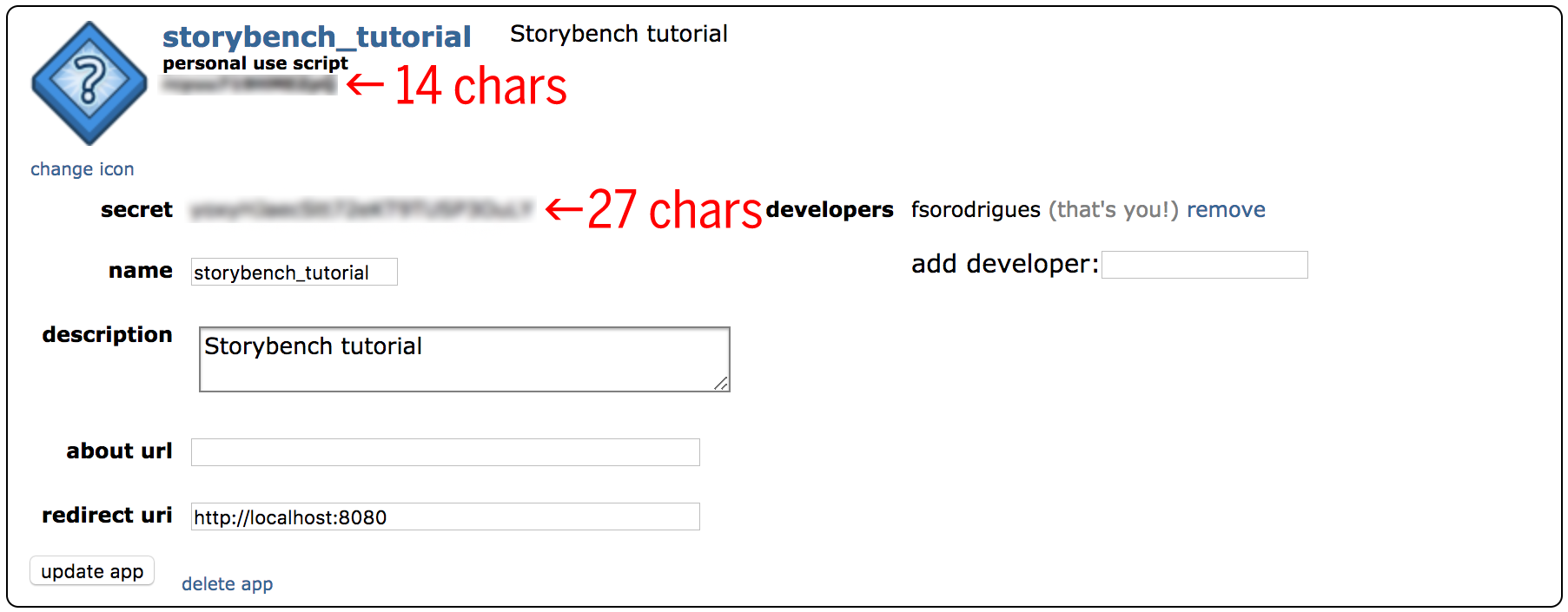
It is important to note below that the values in the fields `client_id`, `client_secret`, `user_agent`, `username`, and `password` need to be replaced with ones own from the reddit API. Below I have a reddit.json file in my parent directory and read values from this file which are fed into the `praw.Reddit()` function.
```python
id_ = ''
secret_ = ''
agent_ = ''
username_ = ''
password_ = ''
with open('../reddit.json', 'r') as file:
lines = json.load(file)
id_ += lines['client_id']
secret_ += lines['client_secret']
agent_ += lines['user_agent']
username_ += lines['username']
password_ += lines['password']
```
```python
reddit = praw.Reddit(client_id=id_,
client_secret=secret_,
user_agent=agent_,
username=username_,
password=password_)
```
## [r/news/](https://www.reddit.com/r/news/) subreddit.
The subreddit of interest is `r/news/` though one can edit the first line the cell below to change what subreddit to look at. We will only be looking at one article in this subreddit name
```python
subreddit = reddit.subreddit('news')
top_subreddit = subreddit.top(limit=10)
```
```python
topics_dict = {"title":[], "score":[], "id":[], "url":[], "comms_num": [], "created": [], "body":[]}
for n in top_subreddit:
topics_dict["title"].append(n.title)
topics_dict["score"].append(n.score)
topics_dict["id"].append(n.id)
topics_dict["url"].append(n.url)
topics_dict["comms_num"].append(n.num_comments)
topics_dict["created"].append(n.created)
topics_dict["body"].append(n.selftext)
```
```python
df = pd.DataFrame.from_dict(topics_dict)
```
```python
df.head()
```
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
title
score
id
url
comms_num
created
body
0
Blizzard Employees Staged a Walkout After the ...
226332
dfn3yi
https://www.thedailybeast.com/blizzard-employe...
9608
1.570683e+09
1
President Donald Trump says he has tested posi...
226153
j3oj21
https://www.cnbc.com/2020/10/02/president-dona...
34754
1.601644e+09
2
Kobe Bryant killed in helicopter crash in Cali...
213684
eubjfc
https://www.fox5dc.com/news/kobe-bryant-killed...
20656
1.580096e+09
3
Scientist Stephen Hawking has died aged 76
188177
84aebi
http://news.sky.com/story/scientist-stephen-ha...
6913
1.521028e+09
4
Jeffrey Epstein's autopsy more consistent with...
186237
dp5lr1
https://www.foxnews.com/us/forensic-pathologis...
10043
1.572465e+09
```python
submission = reddit.submission(id="eubjfc")
submission.comment_sort = "new"
len(submission.comments.list())
```
294
We will only look at one article to inspect if there is hate speech since this article alone has over 20,000 comments and will take time for my computer to process, I will limit PRAW to 'scrolling' down the page to load more comments with the `limit=99` parameter. In the cell below I am initializing a dictionary which to append values into each key which will be used to create a pandas dataframe.
```python
comments_dict = {"author":[], "score":[], "id":[], "replies":[], "edited": [], "created": [], "body":[]}
submission.comments.replace_more(limit=99)
for comment in submission.comments.list():
comments_dict["author"].append(comment.author)
comments_dict["score"].append(comment.score)
comments_dict["id"].append(comment.id)
comments_dict["replies"].append(comment.replies)
comments_dict["edited"].append(comment.edited)
comments_dict["created"].append(comment.created_utc)
#body_ = comment.body.replace
comments_dict["body"].append(comment.body)
```
```python
df_ = pd.DataFrame.from_dict(comments_dict)
```
```python
df_.head(2)
```
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
author
score
id
replies
edited
created
body
0
hoosakiwi
1
ffnzwqh
()
1.58007e+09
1.580073e+09
Let's try and keep the comments here civil. Yo...
1
randy88moss
1
fx335fo
()
False
1.594030e+09
Thinking about you, Mamba!
```python
txt = ''
for n in df_['body'].values:
n = n.replace("\n","").strip()
txt +=n
```
### Frequency Counter
We can now start to use natural language processing to counter the frequency of the words occuring the text above. Words which appear more often can tell us if the title of the news article, "Kobe Bryant killed in helicopter crash in California" matches the content of comments.
Then we will continue to create a model to predict if a comment is hate full speech or not.
```python
nlp = spacy.load("en_core_web_sm")
all_comments = nlp(txt)
words = [chunk.text for chunk in all_comments if not chunk.is_stop and not chunk.is_punct]
```
```python
comment_counts = Counter(words)
```
```python
comment_counts.most_common(10)
```
[('Kobe', 1160),
(' ', 1116),
('people', 772),
('like', 739),
('daughter', 577),
('helicopter', 556),
('know', 531),
('basketball', 450),
('family', 364),
('time', 363)]
### Lemmatization
From [Wikipedia](https://en.wikipedia.org/wiki/Lemmatisation),
>Lemmatisation (or lemmatization) in linguistics is the process of grouping together the inflected forms of a word so they can be analysed as a single item, identified by the word's lemma, or dictionary form.
For example, organizes, organized and organizing are all forms of organize. Here, organize is the lemma. The inflection of a word allows you to express different grammatical categories like tense (organized vs organize), number (trains vs train), and so on. Lemmatization is necessary because it helps you reduce the inflected forms of a word so that they can be analyzed as a single item. It can also help you normalize the text.
spaCy has the attribute lemma_ on the Token class. This attribute has the lemmatized form of a token:
```python
lemmas = [txt.lemma_ for txt in all_comments if not txt.is_stop and not txt.is_punct]
```
```python
lemma_counts = Counter(lemmas)
lemma_counts.most_common(10)
```
[('Kobe', 1159),
(' ', 1116),
('like', 808),
('daughter', 806),
('people', 782),
('know', 742),
('helicopter', 735),
('die', 589),
('say', 556),
('go', 514)]
We still have the issue of a space value being the second most common word in the comments text
### Preprocess Text
```python
def is_token_allowed(token):
'''
Only allow valid tokens which are not stop words
and punctuation symbols.
'''
if (not token or not token.string.strip() or token.is_stop or token.is_punct):
return False
return True
def preprocess_token(token):
# Reduce token to its lowercase lemma form
return token.lemma_.strip().lower()
```
```python
text_processed = [preprocess_token(txt) for txt in all_comments if is_token_allowed(txt)]
text_processed_counter = Counter(text_processed)
text_processed_counter.most_common(10)
```
[('kobe', 1320),
('people', 845),
('daughter', 809),
('like', 808),
('helicopter', 743),
('know', 742),
('die', 589),
('say', 556),
('go', 514),
('basketball', 487)]
We see an improvement above as we have gotten rid of the space value showing as the second most common word in the previous two frequency counters.
Though we can only visually inspect if the comments are related to the article heading, we will move on to creating a machine learning model to predict if a comment is hateful or not.
# Clean Train Data
Text data used for this classification problem is from a [GitHub repository](https://github.com/t-davidson/hate-speech-and-offensive-language) for the [paper](https://arxiv.org/abs/1703.04009) "Automated Hate Speech Detection and the Problem of Offensive Language", ICWSM 2017. Dataset was created as described by the paper:
>We begin with a hate speech lexicon containing words and phrases identified by internet users as hate speech, compiled by Hatebase.org... Workers were asked to label each tweet as one of three categories: hate speech, offensive but not hate speech, or neither offensive nor hate speech. They were provided with our definition along with a paragraph explaining it in further detail. Users were asked to think not just about the words appearing in a given tweet but about the context in which they were used. They were instructed that the presence of a particular word, however offensive, did not necessarily indicate a tweet is hate speech. Each tweet was coded by three or more people.
We will use this dataset to create a supervised machine learning model to predict the classifcation of the text in a reddit comment.
```python
df_twitter = pd.read_csv('labeled_data.csv')
```
```python
df_twitter.head()
```
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Unnamed: 0
count
hate_speech
offensive_language
neither
class
tweet
0
0
3
0
0
3
2
!!! RT @mayasolovely: As a woman you shouldn't...
1
1
3
0
3
0
1
!!!!! RT @mleew17: boy dats cold...tyga dwn ba...
2
2
3
0
3
0
1
!!!!!!! RT @UrKindOfBrand Dawg!!!! RT @80sbaby...
3
3
3
0
2
1
1
!!!!!!!!! RT @C_G_Anderson: @viva_based she lo...
4
4
6
0
6
0
1
!!!!!!!!!!!!! RT @ShenikaRoberts: The shit you...
The tweet column above has a lot of formating issues to be fed into a ML model. Since tweets can be nested we need to clean up the tweets a bit. A rudimentary fix has been made below but more time spent cleaning up the data will create a better model down the road.
```python
df_twitter['tweet'] = df_twitter['tweet'].str.replace('&','and').str.strip('! RT')
```
```python
df_twitter.head()
```
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Unnamed: 0
count
hate_speech
offensive_language
neither
class
tweet
0
0
3
0
0
3
2
@mayasolovely: As a woman you shouldn't compla...
1
1
3
0
3
0
1
@mleew17: boy dats cold...tyga dwn bad for cuf...
2
2
3
0
3
0
1
@UrKindOfBrand Dawg!!!! RT @80sbaby4life: You ...
3
3
3
0
2
1
1
@C_G_Anderson: @viva_based she look like a tranny
4
4
6
0
6
0
1
@ShenikaRoberts: The shit you hear about me mi...
```python
hate_speech = round(len(df_twitter[df_twitter['class']==0])/len(df_twitter)*100,2)
off_speech = round(len(df_twitter[df_twitter['class']==1])/len(df_twitter)*100,2)
neither_speech = round(len(df_twitter[df_twitter['class']==2])/len(df_twitter)*100,2)
print('The ratio of Hate Speech labelled rows to total rows is {}%\n\
The ratio of Offensive Speech labelled rows to total rows is {}%\n\
The ratio of Neutral labelled rows to total rows is {}%'.format(hate_speech,off_speech,neither_speech))
```
The ratio of Hate Speech labelled rows to total rows is 5.77%
The ratio of Offensive Speech labelled rows to total rows is 77.43%
The ratio of Neutral labelled rows to total rows is 16.8%
```python
len(df_twitter)
```
24783
Since the encoding the tweets into a bag of words takes a VERY long time on my computer I will reduce the size of this data set while keeping the ratio of the three classes of speeches constant.
```python
class_zero = df_twitter[df_twitter['class']==0][:143] # Hate Speech
class_one = df_twitter[df_twitter['class']==1][:1919] # Offensive Language
class_two = df_twitter[df_twitter['class']==2][:416] # Neither
```
```python
df_twitter = pd.concat([class_zero, class_one, class_two])
```
Below the Twitter data will be split into a training set and a test set with 1/4 of dataset going to the test set. This will allow how to validate the hatespeech model before moving on to a harder dataset, for example Reddit or any other online source.
```python
X_train, X_test, Y_train, Y_test = train_test_split(df_twitter['tweet'], df_twitter['class'], test_size=0.25, random_state=42)
```
Now the training text will be concatenated into one large string so we can use the `LabelBinarizer()` function from scikit-learn.
```python
twitter_text_train = ''
for n in X_train:
twitter_text_train += n + ' '
```
```python
twitter_encoder = LabelBinarizer()
twitter_encoder.fit(twitter_text_train.split())
```
LabelBinarizer()
```python
col_list = range(len(twitter_encoder.classes_)) # columns from classes create from LabelBinarizer
train_list = np.empty((len(X_train),len(twitter_encoder.classes_))) #create empty arrays to populate
test_list = np.empty((len(X_test),len(twitter_encoder.classes_)))
```
```python
for i, n in enumerate(X_train,0):
transformed = twitter_encoder.transform(n.split())
tmp_ = transformed.sum(axis=0).T
train_list[i] = tmp_
if i % 200 == 199:
print(i+1)
```
200
400
600
800
1000
1200
1400
1600
1800
```python
for i, n in enumerate(X_test,0):
transformed = twitter_encoder.transform(n.split())
tmp_ = transformed.sum(axis=0).T
test_list[i] = tmp_
if i % 100 == 99:
print(i+1)
```
100
200
300
400
500
600
```python
Twitter_train_df = pd.DataFrame(train_list)
Twitter_test_df = pd.DataFrame(test_list)
```
```python
Twitter_train_df.to_csv('train_list.csv', index=False)
Twitter_test_df.to_csv('test_list.csv', index=False)
```
```python
Twitter_test_df = Twitter_test_df.reindex(columns = Twitter_train_df.columns, fill_value=0)
```
```python
Twitter_train_df = pd.read_csv('train_list.csv')
Twitter_test_df = pd.read_csv('test_list.csv')
```
# Dimension Reduction
```python
#twitter_text = nlp(twitter_text)
#text_processed = [preprocess_token(txt) for txt in twitter_text if is_token_allowed(txt)]
```
# Predict if Comment is Hateful or Not
Different machine learning models will be investigated below to figure out the one that generalizes the best to the validation set which 25% of the twitter csv data. Then Reddit comments from `r/news/` will be transformed with the fit from `LabelBinarizer()` above, and this produces a 'bag of words' for a ML model to predict a classification for that reddit comment.
Let us begin by creating a model with Naive Bayes:
## Naive Bayes
```python
nb = GaussianNB()
nb_fit = nb.fit(Twitter_train_df,Y_train)
```
```python
nb_fit.score(Twitter_test_df,Y_test)
```
0.7645161290322581
We see above that we can only predict the class of twitter comment (hate speech, offensive speech, or neutral) with an accuracy of about 76.45%.
```python
parameters_knn = {
'n_neighbors':[3,4,5,6,7],
'weights':['uniform','distance'],
'algorithm':['auto','ball_tree','kd_tree','brute'],
}
knn = KNeighborsClassifier()
clf_knn = GridSearchCV(knn, parameters_knn, cv=5, n_jobs=-1, verbose=10)
clf_knn.fit(Twitter_train_df,Y_train)
```
Fitting 5 folds for each of 40 candidates, totalling 200 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 2 tasks | elapsed: 24.1s
[Parallel(n_jobs=-1)]: Done 9 tasks | elapsed: 43.7s
[Parallel(n_jobs=-1)]: Done 16 tasks | elapsed: 44.2s
[Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.4min
[Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 1.8min
[Parallel(n_jobs=-1)]: Done 45 tasks | elapsed: 2.1min
[Parallel(n_jobs=-1)]: Done 56 tasks | elapsed: 2.5min
[Parallel(n_jobs=-1)]: Done 69 tasks | elapsed: 3.1min
[Parallel(n_jobs=-1)]: Done 82 tasks | elapsed: 3.7min
[Parallel(n_jobs=-1)]: Done 97 tasks | elapsed: 4.3min
[Parallel(n_jobs=-1)]: Done 112 tasks | elapsed: 4.7min
[Parallel(n_jobs=-1)]: Done 129 tasks | elapsed: 5.6min
[Parallel(n_jobs=-1)]: Done 146 tasks | elapsed: 6.0min
[Parallel(n_jobs=-1)]: Done 165 tasks | elapsed: 6.2min
[Parallel(n_jobs=-1)]: Done 184 tasks | elapsed: 6.3min
[Parallel(n_jobs=-1)]: Done 200 out of 200 | elapsed: 6.3min finished
GridSearchCV(cv=5, estimator=KNeighborsClassifier(), n_jobs=-1,
param_grid={'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'],
'n_neighbors': [3, 4, 5, 6, 7],
'weights': ['uniform', 'distance']},
verbose=10)
```python
x = pd.DataFrame(clf_knn.cv_results_)
x[['mean_test_score','std_test_score','rank_test_score']].sort_values(by='rank_test_score').head()
```
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
mean_test_score
std_test_score
rank_test_score
37
0.790101
0.012655
1
29
0.788488
0.012594
2
9
0.788488
0.012594
2
4
0.788487
0.012499
4
24
0.788487
0.012499
4
```python
clf_knn.best_params_
```
{'algorithm': 'brute', 'n_neighbors': 6, 'weights': 'distance'}
```python
clf_knn.best_score_
```
0.7901008607947135
```python
clf_knn.best_estimator_.score(Twitter_test_df,Y_test)
```
0.8080645161290323
There is a slight improvement using a KNN model to classify text speech, however not by much. Lets try random forest.
```python
parameters_rf = {
'n_estimators':[50,75,100,125,150],
'criterion':['gini','entropy'],
'min_samples_split':[2,3,4],
'min_samples_leaf':[1,2,3]
}
rf = RandomForestClassifier()
clf_rf = GridSearchCV(rf, parameters_rf, cv=5, n_jobs=-1, verbose=10)
clf_rf.fit(Twitter_train_df,Y_train)
```
Fitting 5 folds for each of 90 candidates, totalling 450 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 2 tasks | elapsed: 4.6s
[Parallel(n_jobs=-1)]: Done 9 tasks | elapsed: 8.9s
[Parallel(n_jobs=-1)]: Done 16 tasks | elapsed: 12.7s
[Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 19.7s
[Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 24.4s
[Parallel(n_jobs=-1)]: Done 45 tasks | elapsed: 34.0s
[Parallel(n_jobs=-1)]: Done 56 tasks | elapsed: 40.9s
[Parallel(n_jobs=-1)]: Done 69 tasks | elapsed: 52.1s
[Parallel(n_jobs=-1)]: Done 82 tasks | elapsed: 57.9s
[Parallel(n_jobs=-1)]: Done 97 tasks | elapsed: 1.1min
[Parallel(n_jobs=-1)]: Done 112 tasks | elapsed: 1.2min
[Parallel(n_jobs=-1)]: Done 129 tasks | elapsed: 1.3min
[Parallel(n_jobs=-1)]: Done 146 tasks | elapsed: 1.4min
[Parallel(n_jobs=-1)]: Done 165 tasks | elapsed: 1.5min
[Parallel(n_jobs=-1)]: Done 184 tasks | elapsed: 1.5min
[Parallel(n_jobs=-1)]: Done 205 tasks | elapsed: 1.6min
[Parallel(n_jobs=-1)]: Done 226 tasks | elapsed: 1.8min
[Parallel(n_jobs=-1)]: Done 249 tasks | elapsed: 2.0min
[Parallel(n_jobs=-1)]: Done 272 tasks | elapsed: 2.3min
[Parallel(n_jobs=-1)]: Done 297 tasks | elapsed: 2.6min
[Parallel(n_jobs=-1)]: Done 322 tasks | elapsed: 2.7min
[Parallel(n_jobs=-1)]: Done 349 tasks | elapsed: 2.9min
[Parallel(n_jobs=-1)]: Done 376 tasks | elapsed: 3.0min
[Parallel(n_jobs=-1)]: Done 405 tasks | elapsed: 3.1min
[Parallel(n_jobs=-1)]: Done 434 tasks | elapsed: 3.3min
[Parallel(n_jobs=-1)]: Done 450 out of 450 | elapsed: 3.4min finished
GridSearchCV(cv=5, estimator=RandomForestClassifier(), n_jobs=-1,
param_grid={'criterion': ['gini', 'entropy'],
'min_samples_leaf': [1, 2, 3],
'min_samples_split': [2, 3, 4],
'n_estimators': [50, 75, 100, 125, 150]},
verbose=10)
```python
x = pd.DataFrame(clf_rf.cv_results_)
x[['mean_test_score','std_test_score','rank_test_score']].sort_values(by='rank_test_score').head()
```
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
mean_test_score
std_test_score
rank_test_score
1
0.817543
0.010441
1
6
0.815389
0.010508
2
8
0.813234
0.012193
3
2
0.813231
0.013584
4
48
0.812160
0.011136
5
```python
clf_rf.best_params_
```
{'criterion': 'gini',
'min_samples_leaf': 1,
'min_samples_split': 2,
'n_estimators': 75}
```python
clf_rf.best_score_
```
0.8175434020230125
```python
clf_rf.best_estimator_.score(Twitter_test_df,Y_test)
```
0.8419354838709677
There is an even smaller improvement using a Random Forest model to classify text speech.
## Confusion Matrix
```python
labels = ['Hate','Off','Neu']
plot_confusion_matrix(nb_fit, Twitter_test_df, Y_test, normalize='true', display_labels = labels)
plt.title('Naive Bayes Confusion Matrix')
plt.show()
```

```python
labels = ['Hate','Off','Neu']
plot_confusion_matrix(clf_knn.best_estimator_, Twitter_test_df, Y_test, normalize='true', display_labels = labels)
plt.title('K Nearest Neighbours Confusion Matrix')
plt.show()
```

```python
labels = ['Hate','Off','Neu']
plot_confusion_matrix(clf_rf.best_estimator_, Twitter_test_df, Y_test, normalize='true', display_labels = labels)
plt.title('Random Forest Confusion Matrix')
plt.show()
```

# Predict Reddit Comment Classification
```python
df_reddit = df_.copy()
```
```python
df_reddit.head()
```
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
author
score
id
replies
edited
created
body
0
hoosakiwi
1
ffnzwqh
()
1.58007e+09
1.580073e+09
Let's try and keep the comments here civil. Yo...
1
randy88moss
1
fx335fo
()
False
1.594030e+09
Thinking about you, Mamba!
2
rockinchanks
3
fvn9x00
()
False
1.592841e+09
R.I.P. It’s halfway through 2020 and it only r...
3
pspotboy
1
fvb2l2x
()
False
1.592542e+09
Maybe my\nMind just doesn’t have Kobe
4
oooOoh42069
1
fv5ckt5
()
False
1.592419e+09
I like how this post got made me smile awards ...
```python
Reddit_list = np.empty((len(df_reddit['body']),len(twitter_encoder.classes_)))
```
```python
for i, n in enumerate(df_reddit['body'],0):
transformed = twitter_encoder.transform(n.split())
tmp_ = transformed.sum(axis=0).T
Reddit_list[i] = tmp_
if i % 1000 == 999:
print(i+1)
```
1000
2000
3000
4000
5000
6000
7000
```python
Reddit_test_df = pd.DataFrame(test_list)
Reddit_test_df = Twitter_test_df.reindex(columns = Twitter_train_df.columns, fill_value=0)
```
```python
Reddit_predictions = clf_rf.best_estimator_.predict(Reddit_test_df)
```
```python
df_reddit['body'][0], Reddit_predictions[0]
```
("Let's try and keep the comments here civil. You don't have to like Kobe, but celebrating his death, making jokes about it, and wishing death/threatening other people still violates our rules. \n\nUsers who threaten other people will be banned on sight.",
1)
```python
df_reddit['body'][1], Reddit_predictions[1]
```
('Thinking about you, Mamba!', 1)
```python
df_reddit['body'][2], Reddit_predictions[2]
```
('R.I.P. It’s halfway through 2020 and it only really hit me that he’s gone. i didn’t even know you but you still hold a special place in my heart. i hope you, Gigi and the other passengers all have a nice stay in heaven. 😔',
1)
```python
df_reddit['body'][3], Reddit_predictions[3]
```
('Maybe my\nMind just doesn’t have Kobe', 1)
```python
df_reddit['body'][4], Reddit_predictions[4]
```
('I like how this post got made me smile awards and wholesome awards from people',
1)
```python
df_reddit['body'][21], Reddit_predictions[21]
```
('Nice bru 👊 I’ve started following him on YouTube now. I’m interested to hopefully understand the pilot’s thought process in these circumstances and conditions. It seems he was trained as an instructor to use Instruments and had deep knowledge of the route he was flying. Why did he drop nearly 400 feet in 14 seconds? What was his plan B?',
2)
```python
np.where(Reddit_predictions == 0)
```
(array([362]),)
```python
df_reddit['body'][362], Reddit_predictions[362]
```
("Death is a strange thing because it is so hard to wrap your head around it, the most common reaction is to go to how we feel about it, but Id encourage everone to place yourselves for a moment in the victim's shoes, the fear of plummeting to earth holding your loved ones knowing your going to die is unfathomable to me, my thoughts and prayers",
0)
# Results
Text Classification plays an important role in an area of in todays information age, especially with social media. Because of large of amount of data availability on web, for its easy retrieval this data must be organised according to it content, for exmaple clustering text on based on hate speech, offensive speech and neutral. Expansion of social media leds to usage of different kinds of languages on web. This adds complexity to Text classification task. Unfortunately using Twitter data from Thomas Davidson et al., 2017 does *not* generalize well to classifying text data from Reddit. We see above in the Predict Reddit Comment Classification section that most of the predictions are of class 1 (offensive speech) but when we look at the accompanying text it does not seem to be offensive.