https://github.com/deepmancer/clip-object-detection
Zero-shot object detection with CLIP, utilizing Faster R-CNN for region proposals.
https://github.com/deepmancer/clip-object-detection
clip deep-learning faster-rcnn object-detection openai-clip rcnn region-proposal zero-shot-object-detection
Last synced: about 1 year ago
JSON representation
Zero-shot object detection with CLIP, utilizing Faster R-CNN for region proposals.
- Host: GitHub
- URL: https://github.com/deepmancer/clip-object-detection
- Owner: deepmancer
- License: mit
- Created: 2023-08-17T23:37:02.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2024-12-09T14:43:58.000Z (over 1 year ago)
- Last Synced: 2025-05-13T01:05:07.874Z (about 1 year ago)
- Topics: clip, deep-learning, faster-rcnn, object-detection, openai-clip, rcnn, region-proposal, zero-shot-object-detection
- Language: Jupyter Notebook
- Homepage: https://deepmancer.github.io/clip-object-detection/
- Size: 27.5 MB
- Stars: 20
- Watchers: 1
- Forks: 4
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# 🚀 CLIP Zero-Shot Object Detection





> **Detect objects in images without training!**
Welcome to the **CLIP Zero-Shot Object Detection** project! This repository demonstrates how to perform zero-shot object detection by integrating OpenAI's **CLIP** (Contrastive Language-Image Pretraining) model with a **Faster R-CNN** for region proposal generation.
---
| **Source Code** | **Website** |
|:-----------------|:------------|
| github.com/deepmancer/clip-object-detection | deepmancer.github.io/clip-object-detection |
---
## 🎯 Quick Start
Set up and run the pipeline in three simple steps:
1. **Clone the Repository**:
```bash
git clone https://github.com/deepmancer/clip-object-detection.git
cd clip-object-detection
```
2. **Install Dependencies**:
```bash
pip install -r requirements.txt
```
3. **Run the Notebook**:
```bash
jupyter notebook clip_object_detection.ipynb
```
---
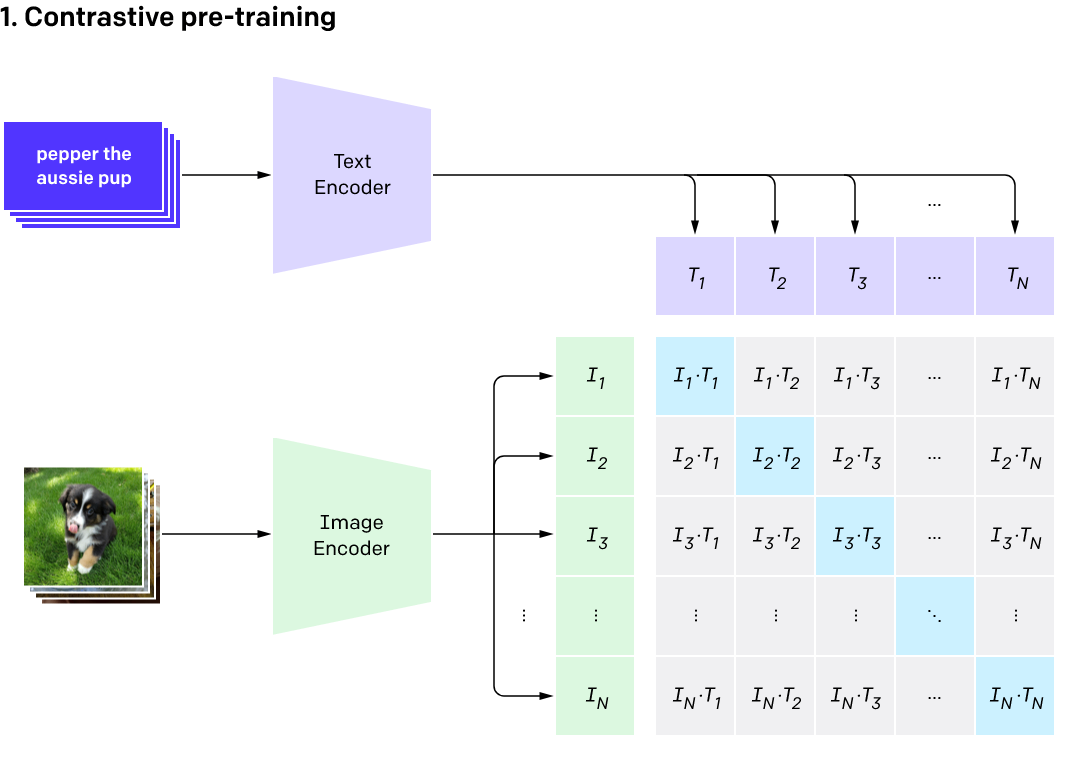
## 🤔 What is CLIP?
**CLIP** (Contrastive Language–Image Pretraining) is trained on 400 million image-text pairs. It embeds images and text into a shared space where the cosine similarity between embeddings reflects their semantic relationship.
---
## 🔍 Methodology
Our approach combines CLIP and Faster R-CNN for zero-shot object detection:
1. **📦 Region Proposal**: Use Faster R-CNN to identify potential object locations.
2. **🎯 CLIP Embeddings**: Encode image regions and text descriptions into a shared embedding space.
3. **🔍 Similarity Matching**: Compute cosine similarity between text and image embeddings to identify matches.
4. **✨ Results**: Highlight detected objects with their confidence scores.
---
## 📊 Example Results
### Input Image

### Region Proposals
Regions proposed by Faster R-CNN's RPN:

### Detected Objects
Objects detected by CLIP based on textual queries:

---
## 📦 Requirements
Ensure the following are installed:
- **PyTorch**: Deep learning framework.
- **Torchvision**: Pre-trained Faster R-CNN.
- **OpenAI CLIP**: [GitHub Repository](https://github.com/openai/CLIP.git).
- Additional dependencies are listed in [requirements.txt](requirements.txt).
---
## 📝 License
This project is licensed under the [MIT License](LICENSE). Feel free to use, modify, and distribute the code.
---
## ⭐ Support the Project
If this project inspires or assists your work, please consider giving it a ⭐ on GitHub! Your support motivates us to continue improving and expanding this repository.