https://github.com/deepmancer/roberta-adapter-fine-tuning
Fine-tuning a RoBERTa model for sentiment analysis on the IMDB movie reviews dataset using the Adapter method and PyTorch Transformers
https://github.com/deepmancer/roberta-adapter-fine-tuning
adapter-finetuning bert huggingface imdb-dataset llm pytorch roberta roberta-model sentiment-analysis sentiment-classification transformers
Last synced: over 1 year ago
JSON representation
Fine-tuning a RoBERTa model for sentiment analysis on the IMDB movie reviews dataset using the Adapter method and PyTorch Transformers
- Host: GitHub
- URL: https://github.com/deepmancer/roberta-adapter-fine-tuning
- Owner: deepmancer
- Created: 2023-05-10T19:49:52.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2024-08-16T12:48:16.000Z (almost 2 years ago)
- Last Synced: 2024-10-11T20:02:26.532Z (almost 2 years ago)
- Topics: adapter-finetuning, bert, huggingface, imdb-dataset, llm, pytorch, roberta, roberta-model, sentiment-analysis, sentiment-classification, transformers
- Language: Jupyter Notebook
- Homepage:
- Size: 156 KB
- Stars: 4
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# 🎭 Fine-Tuning RoBERTa with Adapters for Sentiment Analysis of IMDB Reviews



This project fine-tunes the RoBERTa model using Adapter layers to efficiently adapt the model for sentiment analysis on the IMDB movie reviews dataset.
---
## 📝 Project Description
This project showcases an advanced approach to sentiment analysis by fine-tuning the RoBERTa pretrained model from Hugging Face's Transformers library. The goal is to classify movie reviews as either positive or negative, reflecting the sentiment conveyed in the text. By leveraging the [Adapter](https://arxiv.org/abs/1902.00751) technique, this project inserts task-specific layers into the RoBERTa architecture, enabling focused training on sentiment analysis while preserving the majority of the pretrained model's weights. This method offers a balance between performance and computational efficiency, making it an ideal approach for domain-specific tasks.
### 🎯 Objective
- **Task**: Sentiment classification of IMDB movie reviews (positive or negative).
- **Model**: Fine-tune RoBERTa with additional Adapter layers for the sentiment analysis task, keeping the base model largely intact.
---
## 🧩 The Adapter Method
Adapters are lightweight modules that are inserted within each layer of a pretrained transformer model like RoBERTa. They allow the model to adapt to new tasks with minimal changes to the original model's parameters, which remain mostly frozen. This approach is particularly advantageous when fine-tuning large models on specific tasks, as it reduces the risk of overfitting and requires less computational resources.
### Adapter Architecture
Below is a visualization of the Adapter architecture within the Transformer layers:
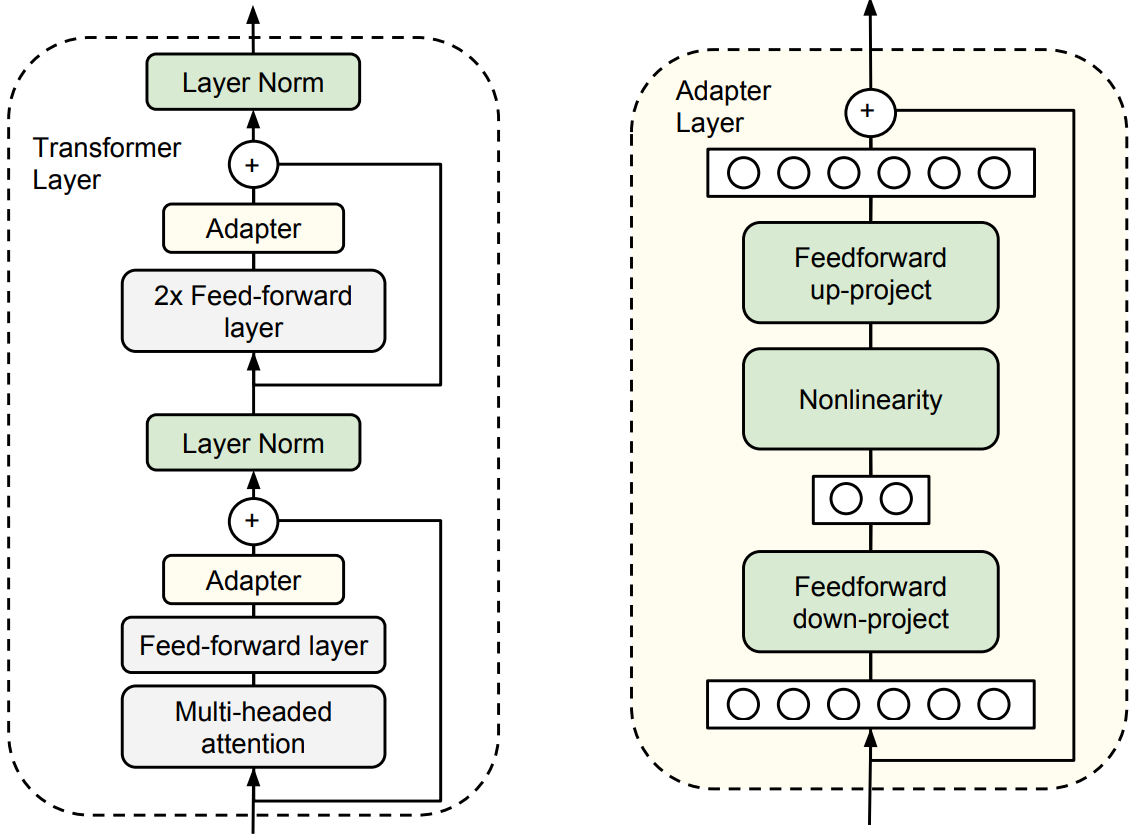
### Key Benefits:
- **Parameter Efficiency**: Only a small number of additional parameters are trained, preserving most of the original model's knowledge.
- **Task-Specific Learning**: Adapters allow the model to learn task-specific features without altering the broader, general-purpose capabilities of the pretrained model.
- **Scalability**: Easily extendable to multiple tasks by adding new adapters for each task, all while keeping the base model frozen.
---
## 🎥 The IMDB Dataset

The **IMDB movie reviews dataset** is a gold standard for sentiment analysis, widely used in NLP research. This dataset provides a robust foundation for training and evaluating sentiment analysis models.
### Dataset Overview
- **Size**: 50,000 movie reviews
- **Train/Test Split**: 25,000 reviews for training and 25,000 for testing
- **Labels**: Binary sentiment classification (positive/negative)
- **Distribution**: Even distribution of positive and negative reviews across training and testing sets
---
## ⚙️ Implementation Details
### Frameworks & Libraries
- **PyTorch**: The deep learning framework used for model implementation and training.
- **Transformers**: Hugging Face's library for accessing and fine-tuning the RoBERTa model.
- **Adapter-Hub**: Integration for using Adapters with the Transformers library, enabling efficient fine-tuning.
### Model Architecture
- **RoBERTa**: A robustly optimized BERT approach, RoBERTa is a transformer model pre-trained on a large corpus of text. It excels at understanding contextual representations of language.
- **Adapters**: Task-specific layers inserted within the RoBERTa model. These adapters are lightweight and are trained for the sentiment analysis task, while the majority of the original RoBERTa weights remain frozen.
### Training Process
- **Adapter Integration**: Adapter layers are added to the RoBERTa model. These layers are specifically trained for the sentiment analysis task, while the base model's parameters are largely untouched.
- **Fine-Tuning**: The model is fine-tuned on the IMDB dataset over several epochs, optimizing the adapter layers to accurately classify the sentiment of movie reviews.
---
## 📊 Results
The fine-tuned model achieves the following performance metrics on the IMDB test set:
| Model | Accuracy | Precision | Recall | F1-Score |
| ----------------- | ----------- | ----------------- | --------------- | ------------- |
| [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta) with Adapters | **94.16%** | **93.82%** | **94.54%** | **94.18%** |
These results demonstrate the effectiveness of using Adapter layers in fine-tuning large-scale transformer models like RoBERTa for specific tasks like sentiment analysis.
---
## 🧪 Evaluation Metrics
- **Accuracy**: Overall correctness of the model's predictions.
- **Precision**: The ratio of correctly predicted positive observations to the total predicted positives.
- **Recall**: The ratio of correctly predicted positive observations to all observations in the actual class.
- **F1-Score**: The weighted average of Precision and Recall, providing a single metric that balances both concerns.