https://github.com/deric/handl-data-generators
Clustering data generators
https://github.com/deric/handl-data-generators
Last synced: about 1 year ago
JSON representation
Clustering data generators
- Host: GitHub
- URL: https://github.com/deric/handl-data-generators
- Owner: deric
- License: lgpl-3.0
- Created: 2015-05-26T15:39:08.000Z (about 11 years ago)
- Default Branch: master
- Last Pushed: 2015-11-23T12:33:35.000Z (over 10 years ago)
- Last Synced: 2025-02-09T20:42:19.842Z (over 1 year ago)
- Language: C
- Size: 1.13 MB
- Stars: 3
- Watchers: 3
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
README
# J. Handl: data generators
Syntetic data generators for creating datasets with Gaussian distribution. The code was taken from [official website](http://personalpages.manchester.ac.uk/mbs/Julia.Handl/generators.html) and slightly modified for modern compilers.
## Requirements
You'll need `g++` compiler.
* Debian: `apt-get install build-essential` should be enough
and run
```
$ make
```
## mult_generator
Currently does not take any parameters, all settings is hard-coded in constants:
```c
#define DIM 2 // dimensionality of the data
#define NUM 40 // number of clusters
#define MAXMU 10 // mean in each dimension is in range [0,MAXMU]
#define MINMU -10
#define MINSIGMA 0
#define MAXSIGMA 20*sqrt(DIM) // standard deviation (to be added on top
// of row sum in each dimension is in range [0,MAXSIGMA]
#define MAXSIZE 100 // size of each cluster is in range [MINSIZE,MAXSIZE]
#define MINSIZE 10
#define RUNS 10 // number of data sets to be generated
```
simply run:
```
$ ./mult_generator
```
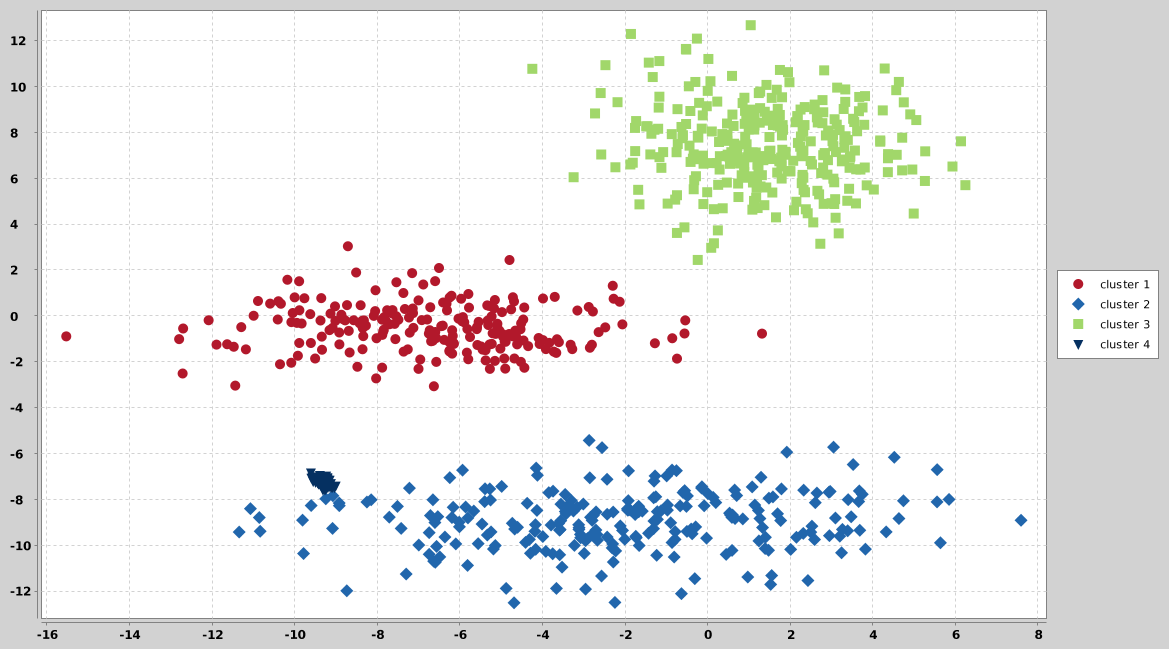
## elly
Ellipsoid generator
```
$ ./elly [-k ] [-d ] [-s ]
```
where all parameters are optional and:
* `` is a positive int >= 2
* `` is a positive int >= 2
* `` is a long int.
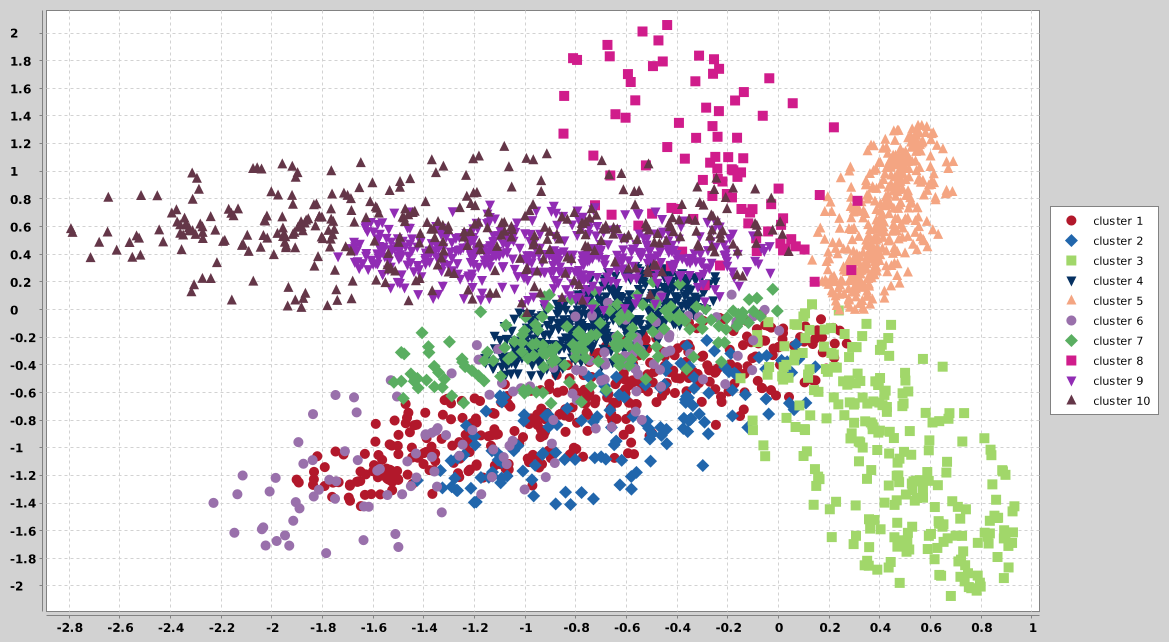
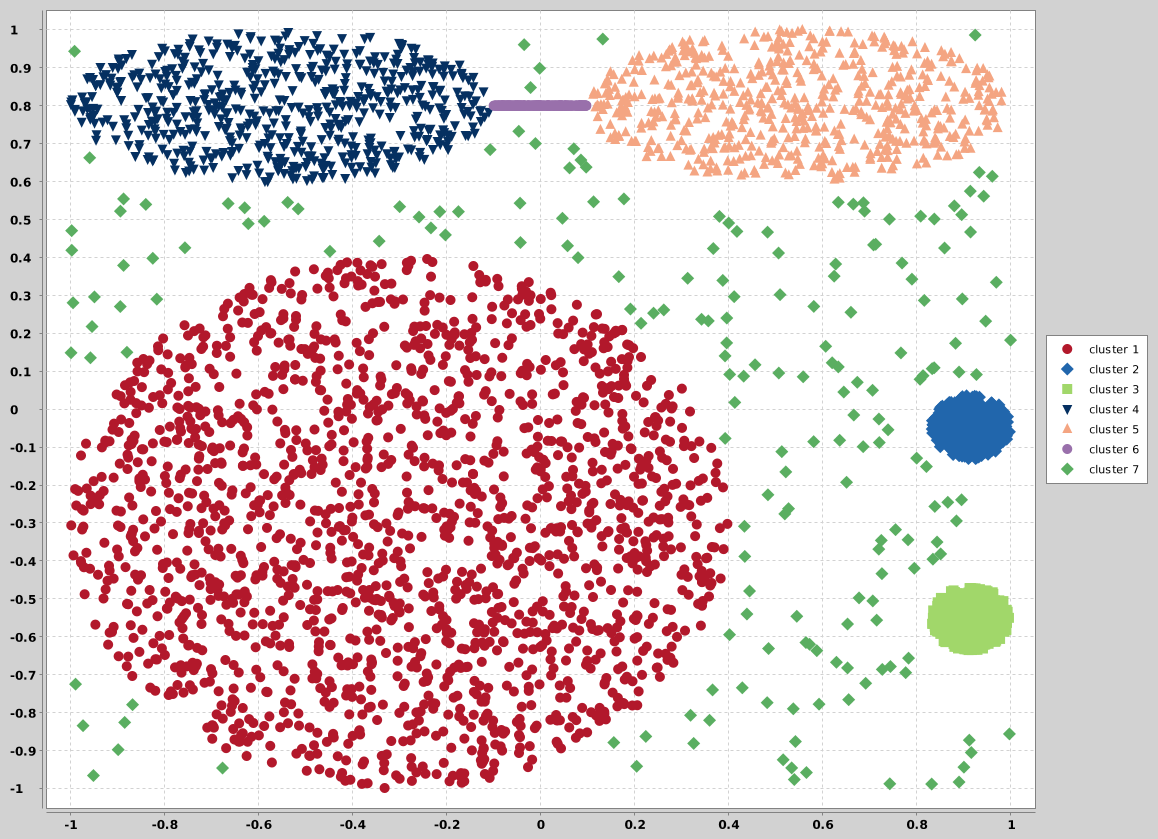
## cure
CURE data sets generator. See Guha, Sudipto, Rajeev Rastogi, and Kyuseok Shim. "CURE: an efficient clustering algorithm for
large databases." ACM SIGMOD Record. Vol. 27. No. 2. ACM, 1998. for more details.
The distribution of data points is just approximated
```
$ ./cure -n [-d ] [-s ] [-l ] [-m ] [-t type of data]
```
where:
* `-l` minimal x/y value
* `-m` maximal x/y value
* `-t` type of dataset, currently supports values 0-2
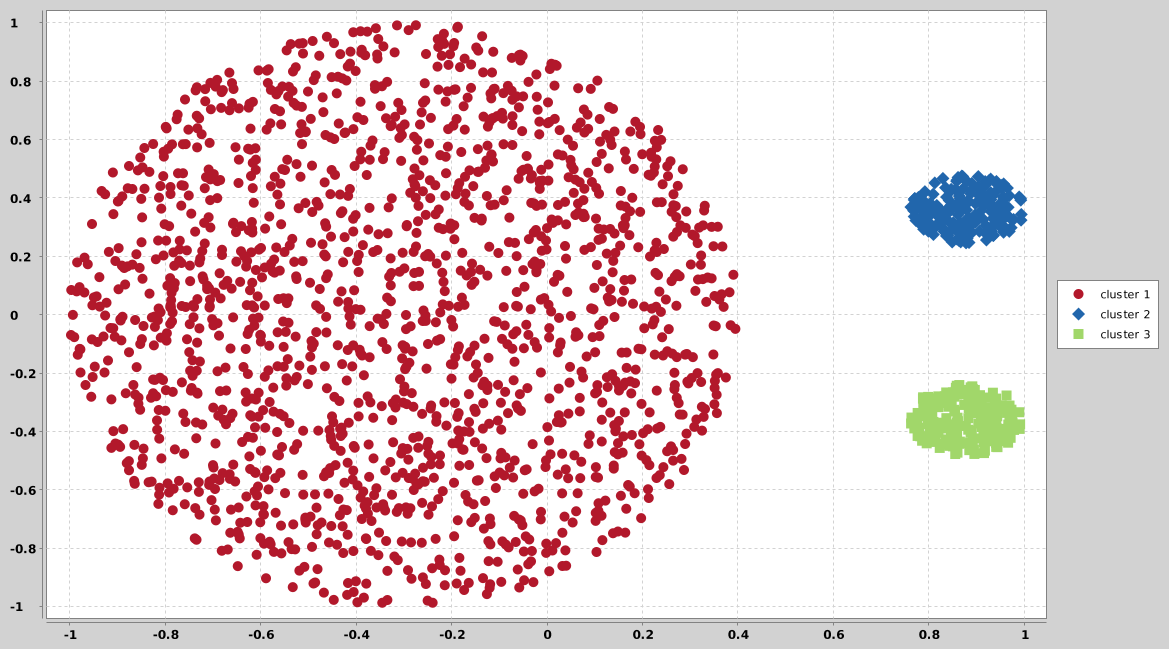
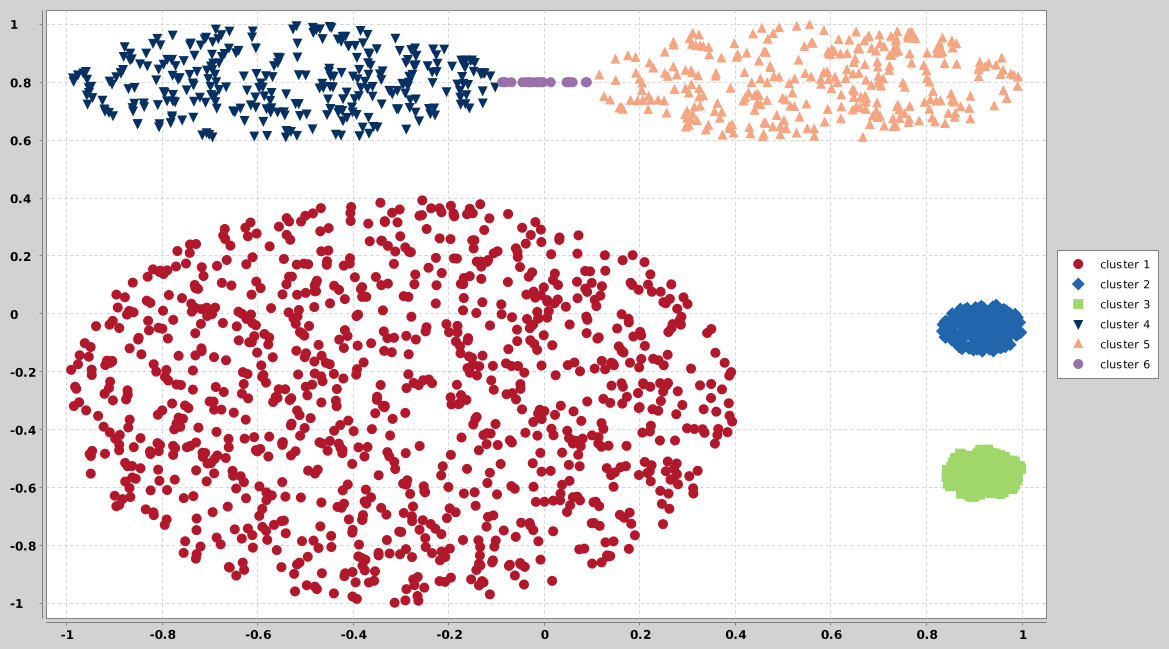
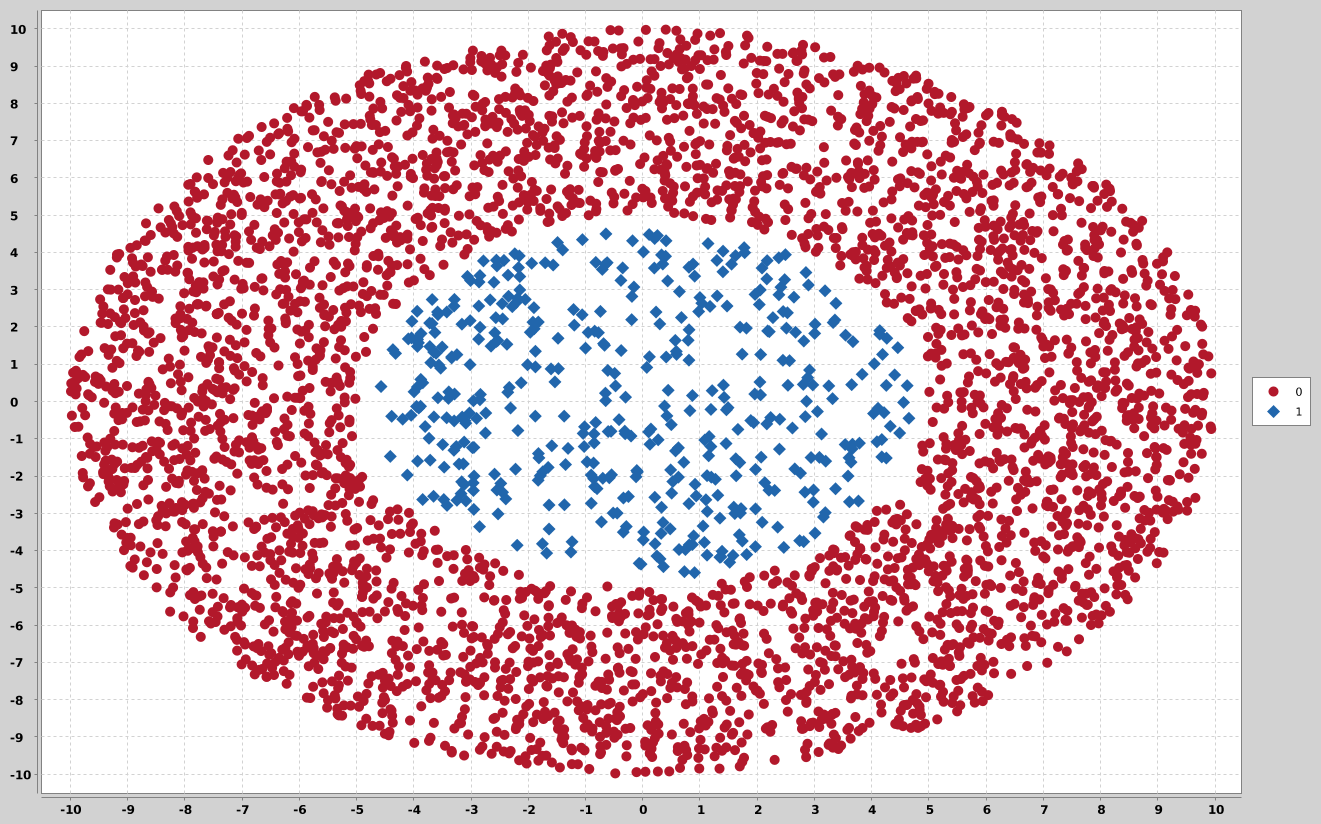
## disk
Disk in disk dataset are two clusters formed by a circle and an annulus around it.
## Authors
* Julia Handl
* Joshua Knowles
* John Burkardt
* Tomas Barton